
過学習:機械学習の落とし穴

AIを知りたい
先生、過学習ってどういう意味ですか?

AIエンジニア
簡単に言うと、覚えるべきデータだけでなく、いらないデータの特徴まで覚えてしまうことだよ。例えば、漢字の書き取り練習で、教科書の例文だけを丸暗記して、似た漢字を書けないような状態だね。
AIを知りたい
例文だけを覚えるのが過学習なんですね。なぜ過学習は起きるのですか?
AIエンジニア
理由は主に二つあるよ。一つは、モデルが複雑すぎて、何でも覚えようとしてしまう場合。もう一つは、覚えるべきデータが少ないため、少ないデータの特徴を過度に捉えてしまう場合だね。漢字の例で言えば、複雑な例文を一つだけ覚える場合と、簡単な漢字を少しだけ練習する場合が、過学習に陥りやすいと言えるね。
過学習とは。
人工知能にまつわる言葉である「過学習」について説明します。過学習とは、特定の練習データにだけ過剰に適応してしまい、それ以外の予測したいデータに対応できなくなる状態のことです。過学習が起こる主な原因は二つあります。一つ目は、設定項目が多すぎて、表現力が豊かすぎるモデルになっていることです。二つ目は、練習データが少ないことです。
過学習とは

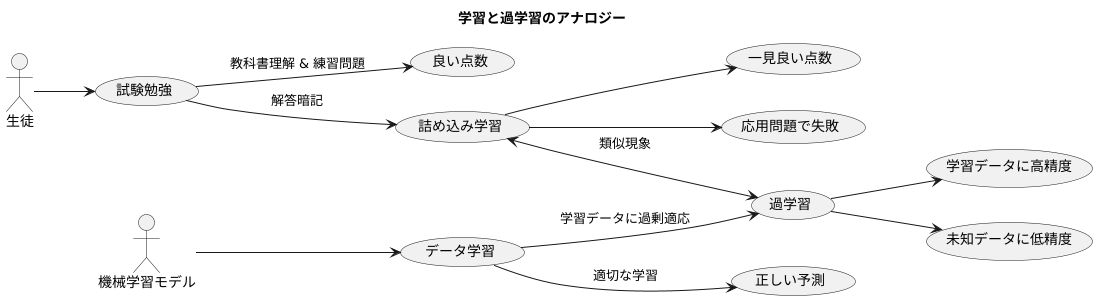
学習とは、まるで生徒が試験のために勉強するようなものです。 教科書の内容をよく理解し、練習問題を繰り返し解くことで、試験で良い点数が取れるようになります。これは機械学習でも同じで、たくさんのデータを使って学習させることで、未知のデータに対しても正しい予測ができるようになります。しかし、勉強の仕方を間違えると、いわゆる「詰め込み学習」になってしまうことがあります。 これは、特定の問題の解答だけを暗記し、問題の背後にある原理や考え方を理解していない状態です。このような学習方法は、試験では一見良い点数が取れるかもしれませんが、少し違う問題が出されると途端に解けなくなってしまいます。
機械学習においても、これと似た現象が起こることがあります。それが「過学習」です。過学習とは、学習に使ったデータに過度に適応しすぎてしまい、新しいデータに対する予測性能が低下する現象のことです。まるで詰め込み学習をした生徒のように、学習に使ったデータに対しては非常に高い精度を示すものの、未知のデータに対してはうまく対応できません。 例えば、猫の画像認識モデルを学習させる場合、学習データに特定の背景の猫の画像ばかりが含まれていると、その背景がない猫の画像を認識できなくなる可能性があります。これが過学習です。
過学習は、機械学習において避けるべき重要な課題です。なぜなら、機械学習の目的は、未知のデータに対しても高い精度で予測できるモデルを作ることだからです。過学習が発生すると、この目的が達成できなくなってしまいます。過学習を避けるためには、学習データの量や質を調整したり、モデルの複雑さを適切に制御したりするなどの対策が必要です。適切な対策を講じることで、過学習を防ぎ、汎化性能の高い、つまり様々なデータに対応できる柔軟なモデルを作ることができます。
過学習の兆候

機械学習を行う上で、「過学習」は避けるべき問題の一つです。過学習とは、訓練に使ったデータに特化しすぎてしまい、新しいデータに対してうまく対応できない状態を指します。まるで、試験の過去問ばかりを暗記して、応用問題に対応できない生徒のようなものです。
過学習が起きているかどうかを見分けるには、訓練データと検証データに対するモデルの性能を比較することが大切です。訓練データとは、モデルの学習に用いるデータのこと、検証データとは、学習したモデルの性能を評価するために用いるデータのことです。例えるなら、訓練データは過去問、検証データは模擬試験のようなものです。過去問の点数は満点に近いのに、模擬試験の点数が低い生徒は、過去問の内容を暗記しているだけで、真の理解に至っていない可能性があります。
訓練データの誤差が非常に小さく、検証データの誤差が大きい場合は、過学習の兆候です。これは、モデルが訓練データの特徴を細部まで覚え込んでしまい、新しいデータにうまく対応できない状態を表しています。また、訓練データに対する精度と検証データに対する精度の差が大きい場合も同様に過学習を示唆しています。過去問では高得点を取れるのに、少し問題の形式が変わっただけで点数が取れなくなるのは、過学習の典型的な例です。
これらの兆候が見られた場合、モデルの修正や調整が必要です。例えば、モデルの複雑さを抑える、学習するデータ量を増やす、といった対策が有効です。生徒に暗記ではなく、理解を促すように、モデルにもデータの背後にある本質を学習させることが重要です。適切な調整を行い、過学習を防ぐことで、より汎用性の高い、信頼できるモデルを構築することができます。
| 項目 | 説明 | 例え |
|---|---|---|
| 過学習 | 訓練データに特化しすぎて、新しいデータにうまく対応できない状態 | 過去問ばかりを暗記して、応用問題に対応できない生徒 |
| 訓練データ | モデルの学習に用いるデータ | 過去問 |
| 検証データ | 学習したモデルの性能を評価するために用いるデータ | 模擬試験 |
| 過学習の兆候 | 訓練データの誤差が非常に小さく、検証データの誤差が大きい場合 訓練データに対する精度と検証データに対する精度の差が大きい場合 |
過去問では高得点を取れるのに、模擬試験では点数が低い |
| 過学習の対策 | モデルの複雑さを抑える 学習するデータ量を増やす |
生徒に暗記ではなく、理解を促す |
発生原因その1:複雑すぎるモデル

学習しすぎの問題は、複雑すぎる作りの模型を使うことが大きな一因です。部品が多すぎる模型は、学習に使うデータの一つ一つの特徴に、必要以上に合わせようとしてしまいます。たとえるなら、少ない数の点を通る曲線を、複雑な計算式を無理やり使って描くようなものです。一見すると完璧に合っているように見えますが、新しい点を加えると、その曲線から大きく外れてしまうかもしれません。つまり、複雑な模型は、本来ならば無視すべきちょっとした違いや例外的なデータにも合わせ込んでしまい、新しいデータにうまく対応できなくなってしまうのです。
具体的に考えてみましょう。果物の見分け方を学習させる場面を想像してみてください。りんご、みかん、ぶどうの三種類の果物を見分けるのに、大きさ、色、形といった単純な特徴だけで十分なはずです。しかし、模型が複雑すぎると、果物の表面の模様や、枝についていた時の位置、果物に付いている傷まで学習してしまうかもしれません。
このような複雑な模型は、学習に使った果物については完璧に見分けられるでしょう。しかし、新しい果物を与えられた時、例えば、いつもと少し違う模様のりんごや、傷のないぶどうを見せられた時に、うまく見分けられない可能性があります。なぜなら、この模型は、本質的な特徴ではなく、学習データの細かな特徴にこだわりすぎてしまったからです。
適切な複雑さの模型を作るためには、学習させるデータの量と種類を考慮することが重要です。データが少ないのに複雑な模型を使うと、学習しすぎの問題が発生しやすくなります。反対に、データが豊富にあれば、より複雑な模型を使っても問題ありません。また、学習データに偏りがある場合、模型は偏った知識を学習してしまい、新しいデータへの対応力が低下します。そのため、多様でバランスの取れたデータを使うことが大切です。
| 問題点 | 原因 | 具体例 | 対策 |
|---|---|---|---|
| 学習しすぎ | 複雑すぎるモデル | りんご、みかん、ぶどうの判別で、果物の模様や傷まで学習 | データ量と種類を考慮、適切な複雑さのモデルを選択 |
| 新しいデータへの対応力低下 | 学習データの細かな特徴にこだわりすぎ | いつもと違う模様のりんご、傷のないぶどうをうまく判別できない | データの偏りをなくし、多様でバランスの取れたデータを使用 |
発生原因その2:データ不足

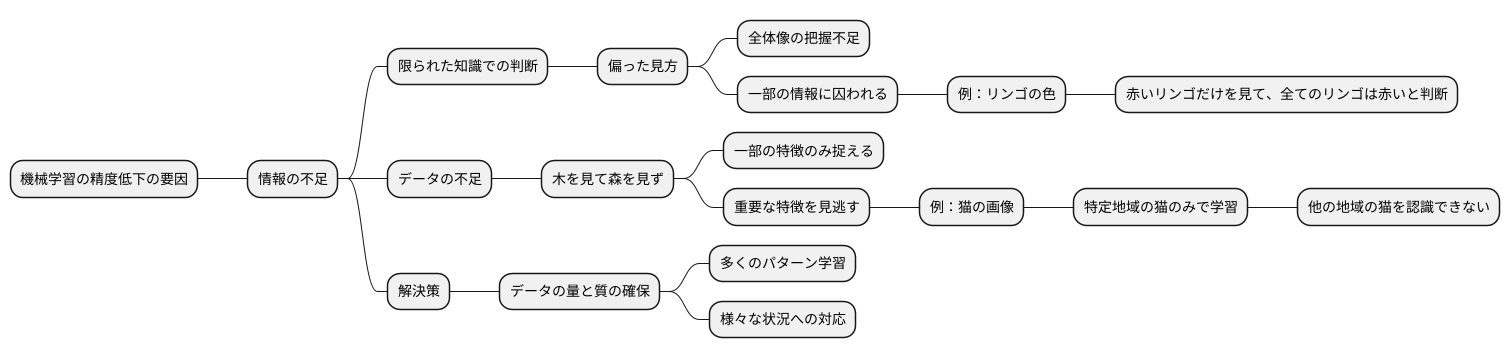
機械学習の精度を下げるもう一つの大きな要因は、学習に用いる情報の不足です。まるで限られた知識だけで世界を理解しようとするようなもので、どうしても偏った見方になりがちです。
十分な情報がなければ、全体像を捉えることができず、一部の情報に囚われてしまいます。例えば、リンゴを数個しか見たことがない人が、その色や形から「すべてのリンゴは赤い」と判断してしまうようなものです。実際には、緑や黄色のリンゴも存在しますが、限られた経験から誤った認識をしてしまうのです。
機械学習も同じで、学習データが少ないと、モデルはデータの特徴の一部だけを捉え、それ以外の重要な特徴を見逃す可能性があります。これは、一部分だけを見て全体を判断する「木を見て森を見ず」の状態です。結果として、新しいデータに直面した際に、適切な判断ができず、誤った予測をしてしまうのです。
例えば、特定の地域でしか撮影されていない猫の画像だけで学習させた場合、その地域特有の猫の特徴に偏って学習してしまいます。他の地域で一般的な猫の画像を見せても、猫だと認識できない可能性があるのです。
学習データの不足は、まるで狭い視野で世界を見るようなものです。広い視野を持つためには、多くの情報が必要です。機械学習モデルを正しく学習させるためには、質の高いデータはもちろん、十分な量のデータを集めることが不可欠です。データが多ければ多いほど、モデルはより多くのパターンを学習し、様々な状況に対応できるようになります。データの量と質は、機械学習モデルの性能を左右する重要な要素と言えるでしょう。
過学習への対策

機械学習を行う上で、学習をうまく進めることはとても重要です。しかし、学習を進めすぎると、過学習と呼ばれる状態に陥ることがあります。過学習とは、訓練データに過度に適合しすぎてしまい、新しいデータに対してうまく予測できない状態のことです。まるで、教科書の例題だけを丸暗記して、応用問題が解けない生徒のような状態です。
過学習を防ぐには、いくつかの対策があります。まず、モデルの複雑さを調整することが大切です。モデルが複雑すぎると、訓練データの細かな特徴まで捉えすぎてしまい、過学習しやすくなります。例えるなら、複雑な数式を覚えるよりも、基本的な公式を理解する方が応用がきくのと同じです。具体的には、モデルのパラメータ数を減らしたり、正則化と呼ばれる手法を用いることで、モデルの複雑さを抑えることができます。正則化とは、モデルの重みに制限を加えることで、過度に複雑なモデルにならないようにする技術です。
次に、訓練データの量を増やすことも効果的です。訓練データが少ないと、モデルはデータの全体像を把握できず、一部の特徴に偏って学習してしまう可能性があります。多くの例題を解くことで、様々な問題への対応力が身につくように、より多くのデータで学習させることで、モデルはデータの全体像をより正確に把握し、過学習のリスクを軽減できます。
さらに、交差検証と呼ばれる手法も有効です。これは、訓練データを複数のグループに分け、それぞれのグループでモデルを学習させ、他のグループで性能を評価する手法です。様々な問題を解くことで、自分の得意不得意を理解できるように、交差検証によって、モデルの汎化性能、つまり新しいデータに対する予測能力を評価することができます。
これらの対策を適切に組み合わせることで、過学習を防ぎ、より精度の高い、様々なデータに対応できるモデルを構築することが可能になります。大切なのは、モデルの複雑さ、データ量、そして検証方法のバランスです。適切な学習を行い、より良い成果を生み出すようにしましょう。
| 対策 | 説明 | 例え |
|---|---|---|
| モデルの複雑さを調整 | モデルが複雑すぎると過学習しやすいため、パラメータ数を減らしたり、正則化を用いて複雑さを抑える。 | 複雑な数式を覚えるより、基本的な公式を理解する方が応用がきく。 |
| 訓練データの量を増やす | 訓練データが少ないと、モデルはデータの全体像を把握できず、一部の特徴に偏って学習してしまう。 | 多くの例題を解くことで、様々な問題への対応力が身につく。 |
| 交差検証 | 訓練データを複数のグループに分け、それぞれのグループでモデルを学習させ、他のグループで性能を評価する。 | 様々な問題を解くことで、自分の得意不得意を理解できる。 |
適切な対策で精度向上を

機械学習では、学習に使ったデータへの適合しすぎを「過学習」と言います。まるで試験のヤマを当てたように、特定の問題にだけ正解できるものの、それ以外の問題には対応できない状態です。過学習はモデルの精度を大きく下げてしまうため、適切な対策が必要です。
過学習が起きる原因の一つに、モデルが複雑すぎるという点が挙げられます。複雑なモデルは、学習データの細かな特徴まで捉えすぎてしまい、本来重要なパターンを見失ってしまうことがあります。例えるなら、木の枝葉の細部まで覚えてしまうことで、森全体の形を見失うようなものです。この対策として、モデルの構造を単純化したり、特定の特徴を無視するといった調整が必要です。
学習データが少ないことも過学習の原因となります。限られたデータから規則性を導き出そうとすると、データの偏りに引っ張られ、一般的な法則を捉えきれません。少ない例題だけを暗記してしまい、応用問題が解けない状態に似ています。この場合は、より多くの学習データを集めることが重要です。データを増やすことで、モデルはより普遍的な規則性を学習できます。
正則化という手法も有効です。これは、モデルが複雑になりすぎるのを防ぐための仕組みで、過学習を抑える効果があります。複雑なモデルにペナルティを与えることで、モデルを滑らかにし、過剰な適合を防ぎます。
また、交差検証も重要な手法です。学習データを複数のグループに分け、それぞれのグループでモデルを学習・評価することで、モデルの汎化性能を確かめます。これは、本番のデータに対する性能を事前に予測するのに役立ちます。様々な問題を解くことで、真の実力を測るようなものです。
これらの対策を適切に行うことで、過学習の影響を抑え、信頼性の高い予測モデルを作ることができます。過学習への対策は、精度向上には欠かせない重要な手順と言えるでしょう。
| 過学習の原因 | 説明 | 対策 |
|---|---|---|
| モデルが複雑すぎる | 学習データの細かな特徴まで捉えすぎてしまい、本来重要なパターンを見失ってしまう。 | モデルの構造を単純化、特定の特徴を無視 |
| 学習データが少ない | 限られたデータから規則性を導き出そうとすると、データの偏りに引っ張られ、一般的な法則を捉えきれない。 | より多くの学習データを集める |
| – | – | 正則化(モデルが複雑になりすぎるのを防ぐ) |
| – | – | 交差検証(学習データを複数のグループに分け、モデルの汎化性能を確かめる) |