
学習を最適化:AdaGrad

AIを知りたい
『エイダグラッド』って、学習の速さを調整するんですよね?普通のやり方とどう違うんですか?

AIエンジニア
そうだね。エイダグラッドは学習の速さ、つまりどれくらい大きく値を更新するかを調整する手法の一つだ。普通のやり方、例えば確率的勾配降下法との違いは、過去の変化の大きさを記録して、それを学習の速さに反映させる点にあるんだ。
AIを知りたい
過去の変化の大きさ、ですか?具体的にはどういうことでしょうか?
AIエンジニア
過去の変化の度合いを二乗して、それを全部足し合わせるんだ。そして、この値が大きくなるほど、学習の速さは小さくなるように調整する。だから、最初は大きく変化するけど、だんだん変化が小さくなっていくんだ。
AdaGradとは。
人工知能で使われる言葉の一つに「アダグラッド」というものがあります。これは、学習をうまく進めるための方法です。学習を進めるときには「学習係数」というものを使いますが、アダグラッドは、この学習係数を調整しながら学習を進めていきます。似たような方法に「確率的勾配降下法」というものがありますが、アダグラッドはこれとは少し違います。アダグラッドでは、過去の勾配の二乗をすべて足し合わせたものを記録していきます。この記録は、学習が進むにつれてどんどん大きくなっていきます。すると、学習係数はだんだん小さくなっていき、最終的にはほとんど更新されなくなります。
はじめに

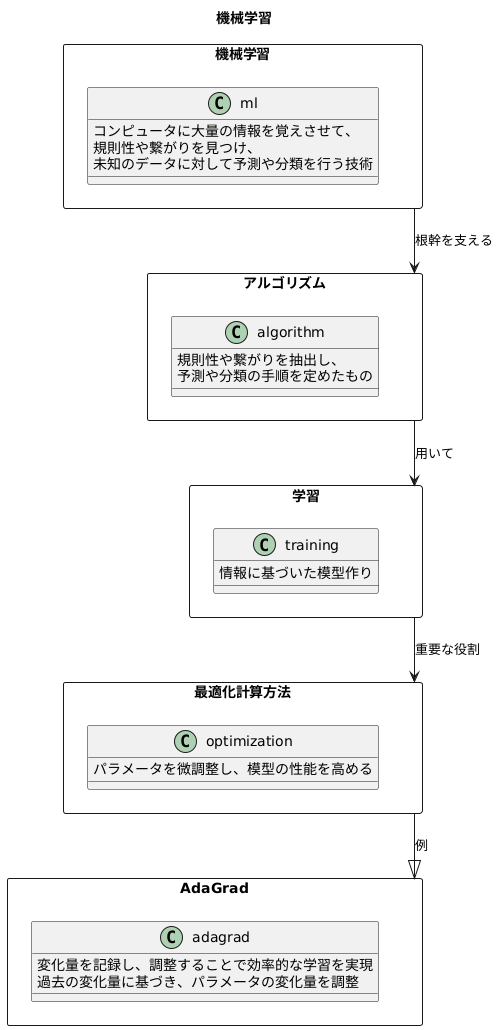
機械学習とは、コンピュータに大量の情報を覚えさせて、そこから規則性や繋がりを見つけることで、未知のデータに対しても予測や分類をできるようにする技術です。この技術の根幹を支えるのが、様々な計算方法、つまりアルゴリズムです。 これらの計算方法は、与えられた情報から規則性や繋がりを抽出し、予測や分類といった作業を実行するための手順を定めたものです。
これらのアルゴリズムを用いて、情報に基づいた模型を作り上げていきます。この模型作りを「学習」と呼びます。学習の過程で重要な役割を担うのが、最適化計算方法です。模型は様々な部品から構成されており、それぞれの部品には数値が割り当てられています。この数値を「パラメータ」と呼びます。最適化計算方法は、このパラメータを微調整することで、模型の性能を高めていくのです。
様々な最適化計算方法の中でも、AdaGradは効率的な学習を実現する手法として注目を集めています。AdaGradは、学習の過程で、それぞれの数値がどれくらい変化したかを記録し、その記録に基づいて、次にどれくらい数値を変化させるかを調整します。 例えば、ある数値がこれまで大きく変化してきた場合は、その数値を大きく変化させることによる影響は小さいと判断し、変化量を小さく調整します。逆に、ある数値がこれまであまり変化してこなかった場合は、その数値を大きく変化させることによる影響は大きいと判断し、変化量を大きく調整します。このように、AdaGradは、それぞれのパラメータに適切な変化量を適用することで、効率的な学習を実現するのです。これにより、学習の速度が向上し、より精度の高い模型を構築することが可能になります。
勾配降下法について

勾配降下法は、機械学習の心臓部ともいえる、大切な学習方法です。この方法は、ちょうど山を下るように、最も低い場所を探し出すための手順を定めたものです。山を下る時、私たちは自然と最も急な斜面を下っていきますよね。勾配降下法もこれと同じ考え方で、関数の値が最も速く小さくなる方向を探し出して、その方向にパラメータと呼ばれる大切な数値を調整していきます。
具体的には、まず現在の地点での勾配、つまり斜面の傾き具合を調べます。この傾きは、関数の微分によって計算されます。そして、この傾きが最も急な方向とは反対の方向に、少しだけ進みます。どのくらい進むかは、学習率と呼ばれる数値で決めます。学習率は、一歩の大きさを決める大切な値で、大きすぎると最適な場所を通り過ぎてしまい、小さすぎるとなかなか目的地にたどり着けません。ちょうど良い大きさを見つけることが重要です。
この「勾配を計算し、学習率に基づいてパラメータを更新する」という手順を何度も繰り返すことで、徐々に関数の最小値、つまり山の最も低い場所へと近づいていきます。勾配降下法には様々な種類があり、例えば、全てのデータを使って勾配を計算するバッチ勾配降下法、ランダムに選んだ一つのデータを使って勾配を計算する確率的勾配降下法、そして、いくつかのデータをまとめて使って勾配を計算するミニバッチ勾配降下法などがあります。どの方法を選ぶかは、扱うデータの量や性質によって変わってきます。AdaGradは、この勾配降下法をさらに進化させた方法で、より効率的に学習を進める工夫が凝らされています。勾配降下法をしっかりと理解することは、AdaGradを学ぶための第一歩であり、ひいては機械学習の様々な手法を理解する上で非常に大切です。
AdaGradの仕組み

学習の効率を上げる手法のひとつとして、エイダグラッドという方法があります。これは、勾配降下法を改良したもので、それぞれの学習パラメータごとに学習の速さを調整することで、より良い学習結果を得られるように工夫されています。
勾配降下法は、山の斜面を下るように最適な値を探す方法です。この時、斜面の傾きが急な場合は大きく一歩進み、緩やかな場合は小さく一歩進みます。この一歩の大きさを学習率と呼びます。全ての学習パラメータで同じ学習率を使うと、最適な値にたどり着くまでに時間がかかったり、うまくたどり着けない場合もあります。
エイダグラッドは、それぞれのパラメータがこれまでどのくらい変化してきたかを記録し、その記録に基づいて学習率を調整します。具体的には、過去の変化量の二乗を全て足し合わせた値を保存します。この値が大きいパラメータは、これまで大きく変化してきたことを意味します。逆に、この値が小さいパラメータは、これまであまり変化していないことを意味します。
エイダグラッドでは、この過去の変化量の記録を使って、パラメータごとに学習率を調整します。これまで大きく変化してきたパラメータは、学習率を小さくします。これは、既に最適な値に近づいている可能性が高いため、大きな変化を避けるためです。逆に、これまであまり変化していないパラメータは、学習率を大きくします。これは、まだ最適な値から遠い可能性が高いため、より速く最適な値に近づくためです。
このように、エイダグラッドは、パラメータごとに学習率を調整することで、学習の効率を高めることができます。学習パラメータの中には、頻繁に更新されるものと、そうでないものがあります。エイダグラッドは、頻繁に更新されるパラメータの学習率を小さくすることで、学習が不安定になるのを防ぎ、更新頻度の低いパラメータの学習率を大きくすることで、最適な値への到達を早めます。これにより、全体としてより効率的な学習を実現できるのです。
| 手法 | 説明 | 学習率の調整 |
|---|---|---|
| 勾配降下法 | 山の斜面を下るように最適な値を探す。斜面の傾き(勾配)に応じて一歩の大きさ(学習率)を変える。 | 全てのパラメータで同じ学習率を使用 |
| エイダグラッド(改良版勾配降下法) | パラメータごとに学習の速さを調整することで、より良い学習結果を得る。 | パラメータの過去の変化量に基づいて調整
|
学習率の調整

学習の速さを決める大切な要素、学習率。これを適切に調整することは、機械学習モデルの性能を最大限に引き出す鍵となります。 AdaGradは、この学習率を各々の学習パラメータに合わせて自動で調整する、優れた手法です。
AdaGradの最大の特徴は、パラメータごとに学習率を個別に調整できる点にあります。 これは、各パラメータが持つ情報の量や更新頻度に応じて、最適な学習の歩幅を調整することを意味します。
例えば、あるパラメータの勾配、つまり変化の度合いが常に大きいとします。これは、そのパラメータが既に最適な値に近づいていることを示唆しています。このような場合、AdaGradは学習率を小さく調整します。そうすることで、最適値周辺での細かい調整が可能となり、より精度の高い学習結果が得られます。
逆に、あるパラメータの勾配が小さい場合は、まだ最適な値から遠く離れている可能性が高いと考えられます。この場合、AdaGradは学習率を大きく調整することで、最適値への到達を早めます。
このように、AdaGradは各パラメータの勾配情報を蓄積し、その情報に基づいて学習率を動的に調整します。これにより、パラメータの重要度や更新頻度を自動的に考慮しながら、効率的な学習を実現します。結果として、手動で学習率を調整する手間を省きつつ、より良い学習結果を得ることができるのです。 特に、データの特性がパラメータごとに大きく異なる場合や、最適な学習率を見つけるのが難しい場合に、AdaGradは大きな効果を発揮します。 AdaGradは、まさに学習を加速させる賢い助っ人と言えるでしょう。
| 勾配の大きさ | 学習率の調整 | 理由 | 結果 |
|---|---|---|---|
| 大きい | 小さく | 最適値に近づいているため、細かい調整が必要 | 精度の高い学習結果 |
| 小さい | 大きく | 最適値から遠く離れているため、大きな変化が必要 | 最適値への到達を早める |
AdaGradの利点

学習の進め方を自動で調整する手法である、エイダグラッドには様々な長所があります。まず第一に、学習の歩幅を人の手で調整する必要がないという点が挙げられます。従来の方法では、最適な歩幅を見つけるために何度も試行錯誤を繰り返す必要がありました。しかし、エイダグラッドは自動的に歩幅を調整してくれるので、この手間を省くことができます。これにより、時間と労力を大幅に削減できます。
第二に、エイダグラッドはまばらな情報にもうまく対応できます。まばらな情報とは、ほとんどがゼロであるような情報のことです。例えば、商品の購入履歴など、多くのユーザーが購入していない商品も含まれるため、データ全体としてはゼロが多い状態になります。エイダグラッドは、ゼロ以外の情報に対しては大きな歩幅で、ゼロの情報に対しては小さな歩幅で学習を進めます。このように、情報の特性に合わせて歩幅を調整することで、まばらな情報でも効率的に学習できます。
第三に、エイダグラッドは学習の過程で生じる揺らぎにも強いという利点があります。学習の過程では、様々な要因で揺らぎが生じることがあります。例えば、データにノイズが含まれていたり、モデルが複雑すぎたりする場合です。エイダグラッドは、過去の学習情報を蓄積して活用することで、これらの揺らぎの影響を軽減し、安定した学習を実現します。具体的には、過去の情報を基に、どの程度揺らぎを抑えるべきかを判断し、それに応じて歩幅を調整します。このように、エイダグラッドは過去の情報をうまく活用することで、より安定した学習を可能にします。
| 長所 | 説明 |
|---|---|
| 自動での歩幅調整 | 人の手で学習の歩幅を調整する必要がなく、試行錯誤の手間を省き、時間と労力を削減できる。 |
| まばらな情報への対応 | ゼロ以外の情報には大きな歩幅、ゼロの情報には小さな歩幅で学習を進めることで、まばらな情報でも効率的に学習できる。 |
| 学習の揺らぎへの耐性 | 過去の学習情報を蓄積・活用し、揺らぎの影響を軽減、安定した学習を実現。過去の情報を基に揺らぎの抑制度合いを判断し、歩幅を調整する。 |
AdaGradの欠点

エイダグレードは、勾配の二乗和の平方根の逆数によって学習の歩幅を調整する手法です。これは、頻繁に更新されるパラメータの学習歩幅を小さくし、まれに更新されるパラメータの学習歩幅を大きくすることで、学習の効率を高めることを目的としています。しかし、この仕組みにより、エイダグレードには学習の進行とともに更新が停滞してしまうという欠点があります。
エイダグレードでは、過去のすべての勾配の二乗和を蓄積していきます。そして、この蓄積された値が時間の経過とともに単調に増加していくため、学習歩幅は徐々に小さくなっていきます。学習の初期段階では、この調整が有効に機能し、適切なパラメータ更新を実現します。しかし、学習が進むにつれて、蓄積された勾配の二乗和が非常に大きくなってしまい、学習歩幅が極端に小さくなってしまうのです。
結果として、学習の後半では、たとえ大きな勾配が得られたとしても、学習歩幅が小さすぎるため、パラメータがほとんど更新されなくなります。これはまるで、目的地まであと少しのところで、歩く速度が遅すぎて到着できないようなものです。この状態に陥ると、最適なパラメータの値に収束することが難しくなり、モデルの性能が向上しなくなってしまいます。
この問題を解決するために、エイダグレードを改良した手法がいくつか提案されています。例えば、アールエムエスプロップやアダムなどは、過去の勾配情報を指数関数的に減衰させることで、学習歩幅の減少を抑制し、学習の停滞を防いでいます。これらの手法は、エイダグレードの利点を活かしつつ、その欠点を克服することで、より効果的な学習を実現しています。
| 手法 | 説明 | 利点 | 欠点 | 改良手法 |
|---|---|---|---|---|
| エイダグレード | 勾配の二乗和の平方根の逆数によって学習の歩幅を調整 | 頻繁に更新されるパラメータの学習歩幅を小さくし、まれに更新されるパラメータの学習歩幅を大きくすることで、学習の効率を高める | 学習の進行とともに更新が停滞してしまう。過去のすべての勾配の二乗和を蓄積していくため、学習歩幅が徐々に小さくなり、学習の後半ではパラメータがほとんど更新されなくなる。 | RMSprop, Adam |
| RMSprop Adam |
過去の勾配情報を指数関数的に減衰させる | 学習歩幅の減少を抑制し、学習の停滞を防ぐ。エイダグレードの利点を活かしつつ、その欠点を克服。 | (記載なし) | – |