予測モデルの精度劣化:ドリフト問題

AIを知りたい
先生、「ドリフト」ってAIの分野でよく聞くんですけど、どういう意味ですか?

AIエンジニア
簡単に言うと、AIモデルの精度が悪くなっていく現象のことだよ。たとえば、ある時期に作った商品の売れ行き予測モデルが、時間が経つにつれて外れていく、といった状況だね。大きく分けて「概念ドリフト」と「データドリフト」の2種類があるんだ。
AIを知りたい
概念ドリフトとデータドリフト…違いがよくわからないです。
AIエンジニア
概念ドリフトは、予測したいもの自体が変わってしまうこと。例えば、ある商品の流行が過ぎて売れなくなると、以前の売れ行き予測モデルは役に立たなくなるよね。データドリフトは、予測に使うデータが変わってしまうこと。例えば、商品の購入者の年齢層が変わると、以前のデータに基づいた予測は精度が下がるんだ。
ドリフトとは。
人工知能で使われる「ずれ」という言葉について説明します。(人工知能は機械学習や予測分析などとも呼ばれます。)この「ずれ」にはいくつか種類があり、それぞれずれが生じる原因によって呼び方が違います。主な種類として、「意味のずれ」と「データのずれ」があります。
ドリフトとは

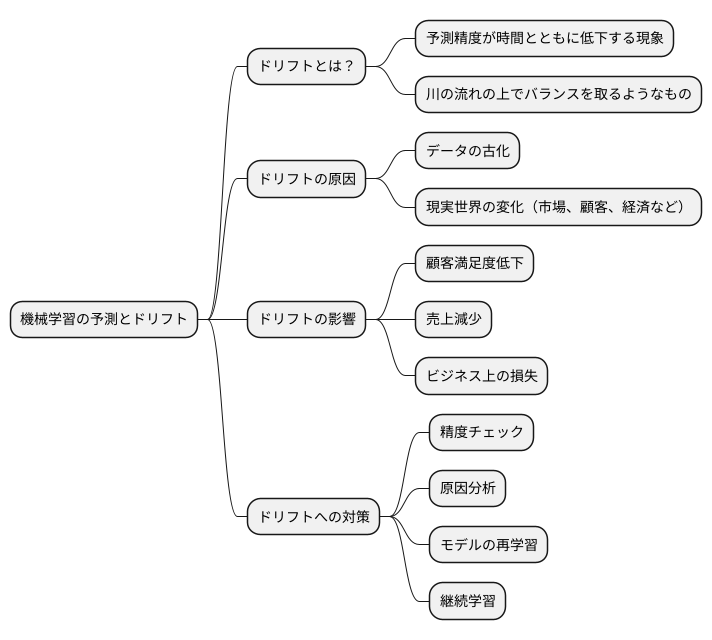
機械学習を使った予測は、まるで流れ行く水の上でバランスを取るようなものです。時間とともに、予測の精度は下がる「ずれ」が生じることがあります。この現象を「ドリフト」と呼びます。
なぜドリフトが起こるのでしょうか?それは、機械学習の予測を作る「もと」となるデータが古くなってしまうからです。学習に使ったデータは過去のものです。しかし、現実は常に変わっています。まるで生きている川のように、市場の流行、顧客の好み、経済状況などは常に変化しています。学習に使ったデータが古いままでは、この変化に対応できず、予測の精度が下がってしまいます。
ドリフトは、様々な問題を引き起こします。例えば、顧客のニーズを捉えきれず、顧客満足度が低下するかもしれません。商品の需要予測が外れて、売上が減ってしまうかもしれません。ビジネスの意思決定に誤りが生まれ、損失を招くかもしれません。
ドリフトへの対策は、機械学習をうまく使う上で欠かせません。定期的に予測の精度をチェックする必要があります。精度が下がっていることに気づいたら、その原因を探ることが大切です。データが古くなっているのが原因であれば、新しいデータを使ってモデルを学習し直す必要があります。変化の激しい状況に対応できるよう、常に学習し続ける仕組みを取り入れることも有効です。
ドリフトを理解し、適切な対策を講じることで、機械学習モデルは常に最高の状態を保ち、ビジネスの成長に貢献できます。まるで流れ行く水の上で、巧みにバランスを取り続ける達人のように。
二つの主なドリフト

機械学習モデルの予測精度が時間の経過と共に低下する現象、ドリフト。大きく分けて二つの種類があります。一つは概念ドリフト、もう一つはデータドリフトです。これらは別々の現象ですが、時に相互に関連し合い、複雑にモデルの精度に影響を与えます。
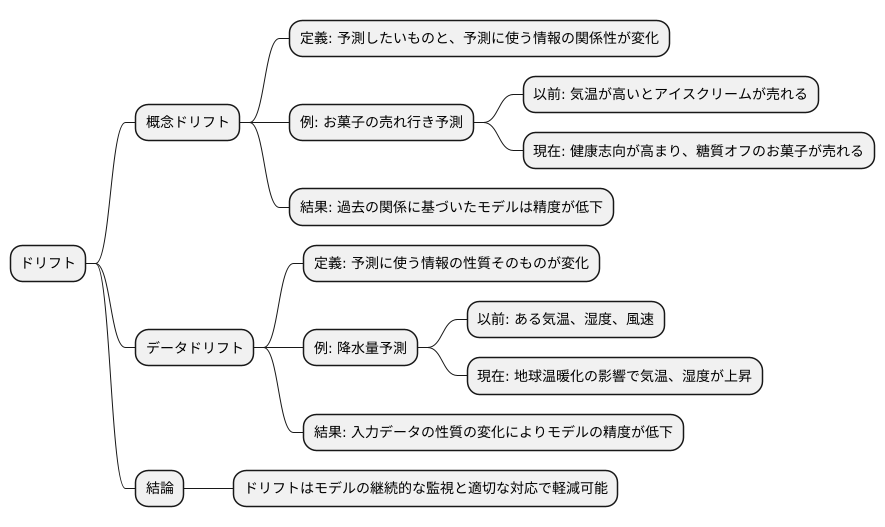
まず、概念ドリフトについて説明します。これは予測したいものと、予測に使う情報の関係性が変化してしまうことです。例えば、あるお菓子の売れ行きを予測するモデルを考えてみましょう。このモデルは、気温や湿度、広告費などの情報を使って、お菓子がどれだけ売れるかを予測します。しかし、消費者の好みが変わり、健康志向が高まったとします。すると、以前は気温が高いと売れていたアイスクリームの売れ行きが鈍くなり、代わりに糖質オフのお菓子が売れ始めるかもしれません。このように、気温と売れ行きの関係が変わってしまったことが概念ドリフトです。これまでの関係に基づいて学習したモデルは、新しい状況に対応できず、予測精度が落ちてしまいます。
次に、データドリフトについて説明します。これは予測に使う情報の性質そのものが変化してしまうことを指します。例えば、ある地域の降水量を予測するモデルを考えてみましょう。このモデルは、過去の気温、湿度、風速などのデータを使って学習されています。しかし、近年、地球温暖化の影響で、その地域の気候が変化し、以前よりも気温が高く、湿度も高くなったとします。学習時とは気温や湿度の分布が変化したため、過去のデータに基づいて学習したモデルは、現在の状況に合わなくなり、正確な予測ができなくなります。これがデータドリフトです。つまり、入力データの性質の変化がモデルの予測精度を低下させるのです。これらのドリフトは、モデルの継続的な監視と適切な対応によって軽減できます。
概念ドリフトへの対応

データの傾向が時とともに変化する現象、いわゆる概念ドリフトは、機械学習モデルの予測精度を低下させる大きな要因となります。この概念ドリフトに対処するためには、いくつかの方法が考えられますが、中でもモデルの再学習は非常に効果的です。
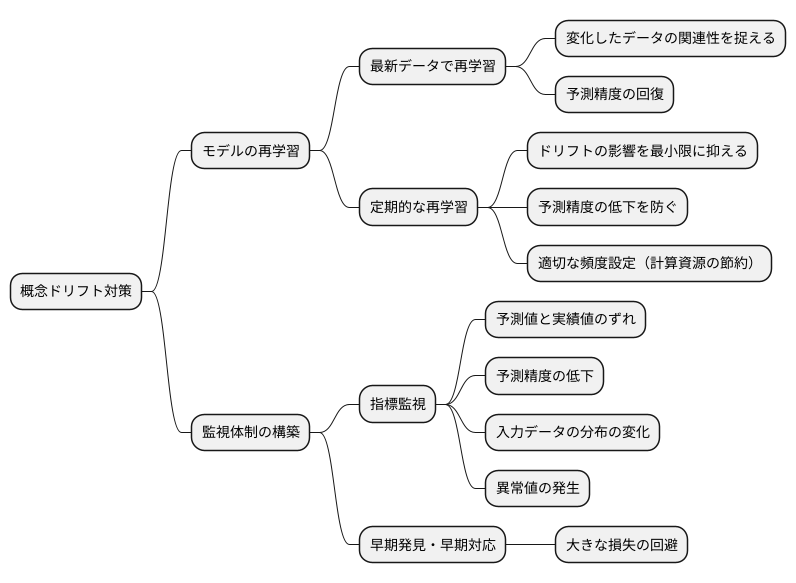
まず、変化したデータの関連性を捉え直すことが重要です。私たちの社会は常に変化しており、過去のデータが将来もそのまま通用するとは限りません。例えば、消費者の好みや流行は日々変化します。過去の購買データに基づいて学習したモデルは、現在の消費者の動向を正しく反映できない可能性があります。そこで、最新の購買データを用いてモデルを再学習することで、変化した関係性をモデルに反映させることができます。これにより、予測精度を回復させ、より正確な予測を行うことができるようになります。
また、定期的なモデルの再学習も重要です。あらかじめ再学習の計画を立て、例えば月に一度や週に一度など、一定の間隔でモデルを再学習することで、ドリフトの影響を最小限に抑えることができます。常に最新のデータで学習した状態を保つことで、予測精度の低下を防ぐことができます。ただし、再学習には計算資源が必要となるため、適切な頻度を設定する必要があります。あまりに頻繁に再学習を行うと、計算資源の無駄遣いになる可能性があります。
さらに、早期に変化の兆候を捉える監視体制の構築も重要です。具体的には、予測値と実績値のずれや、予測精度の低下といった指標を監視することで、概念ドリフトの発生を早期に検知することができます。また、入力データの分布の変化や異常値の発生なども、ドリフトを示唆する重要な指標となります。これらの指標を継続的に監視することで、迅速な対応が可能になり、大きな損失を回避することができます。早期発見、早期対応こそが、概念ドリフトへの有効な対策と言えるでしょう。
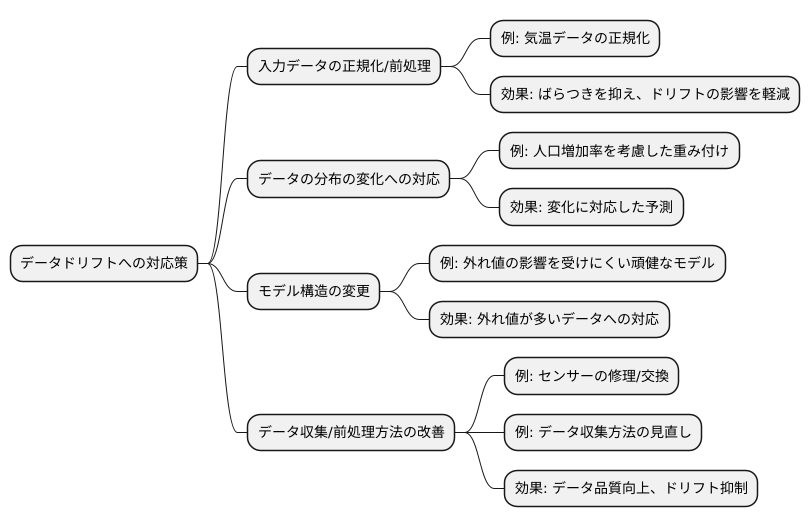
データドリフトへの対応

機械学習のモデルは、時間の経過とともに予測精度が低下することがあります。これは、学習時と運用時でデータの性質が変化してしまう「データドリフト」が原因であることが少なくありません。このデータドリフトに適切に対応しなければ、モデルの信頼性は失われ、期待通りの成果を得ることが難しくなります。
データドリフトへの対応策として、まず入力データの正規化や前処理が挙げられます。これは、データのばらつきを抑え、一定の範囲内に収める処理のことです。例えば、気温データを使って予測モデルを構築している場合、地球温暖化の影響で気温の平均値や分布範囲が変化することが考えられます。このような変化に対応するために、気温データを正規化し、過去のデータと比較可能な状態にすることで、ドリフトの影響を軽減し、モデルの安定性を維持することができます。
また、データの分布の変化を適切に捉える処理も有効です。例えば、特定の地域で人口が増加し、それに伴って購買データの分布が変化した場合、地域ごとの人口増加率を考慮した重み付けを行うことで、変化に対応した予測を行うことができます。
モデルの構造自体を変更するという方法もあります。新しいデータに外れ値が多く含まれるようになった場合、従来のモデルでは対応しきれず、予測精度が低下する可能性があります。このような場合は、外れ値の影響を受けにくい、頑健なモデルに変更することで、予測精度を維持することができます。
さらに、データドリフトの根本原因を特定し、データの収集方法や前処理方法を改善することも重要です。例えば、センサーの故障が原因でデータにノイズが混入している場合は、センサーを修理または交換することで、データの品質を向上させることができます。また、データの収集方法に偏りがある場合は、収集方法を見直すことで、より代表的なデータを取得し、ドリフトの発生を抑制することができます。これらの対策を組み合わせることで、データドリフトによる悪影響を最小限に抑え、信頼性の高い予測モデルを維持することが可能になります。
ドリフト検知の重要性

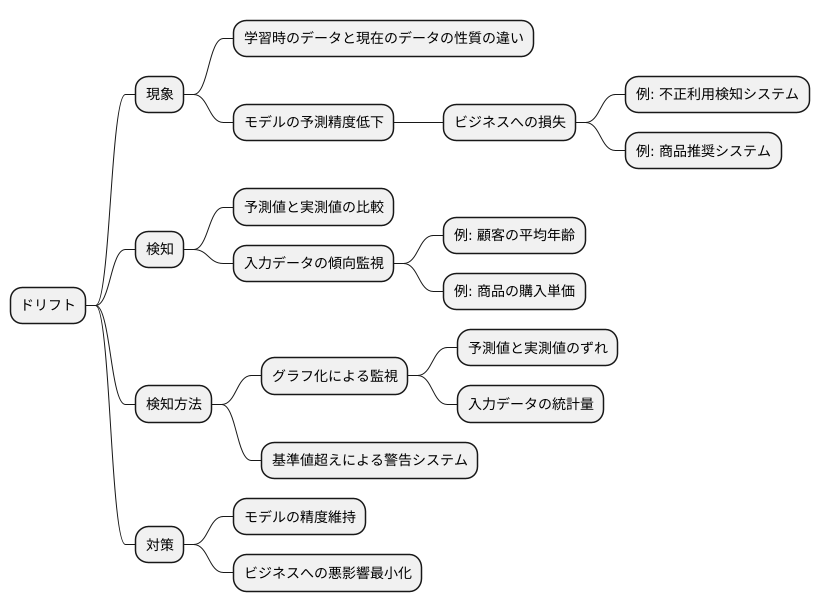
機械学習のモデルは、学習した時点でのデータに基づいて未来を予測します。しかし、時間の経過とともに現実世界の状況は変化します。学習時と現在のデータの性質に違いが生じると、せっかく作ったモデルの予測精度が下がり、役に立たなくなることがあります。これが「ドリフト」と呼ばれる現象です。
ドリフトは、まるで船が航路から徐々にずれていくように、モデルの予測性能を少しずつ低下させます。このズレに早く気づき修正しなければ、ビジネスに大きな損失をもたらす可能性があります。例えば、不正利用検知システムでドリフトが発生すると、新しい手口を見逃し、被害が拡大するかもしれません。商品推奨システムであれば、顧客の好みからずれた商品を提示し続け、販売機会の損失につながります。
そのため、ドリフトを早期に検知することが非常に重要です。具体的には、モデルが出した予測値と実際の結果を比較して、予測の正確さが維持されているかを確認します。また、入力データの傾向にも注意を払います。例えば、顧客の平均年齢や商品の購入単価など、データの特徴に大きな変化がないか監視します。これらの変化はドリフトの兆候を示している可能性があります。
ドリフトの兆候を捉えるためには、様々な方法があります。予測値と実測値のずれの大きさや、入力データの統計量の推移をグラフ化して監視するのも有効です。また、あらかじめ基準値を設定し、それを超えたら自動的に警告を出すシステムを構築すれば、迅速な対応が可能になります。
早期にドリフトを検知し適切な対策を講じることで、モデルの精度を保ち、ビジネスへの悪影響を最小限に抑えることができます。変化の激しい現代において、ドリフト検知は機械学習モデルを運用する上で欠かせない要素と言えるでしょう。
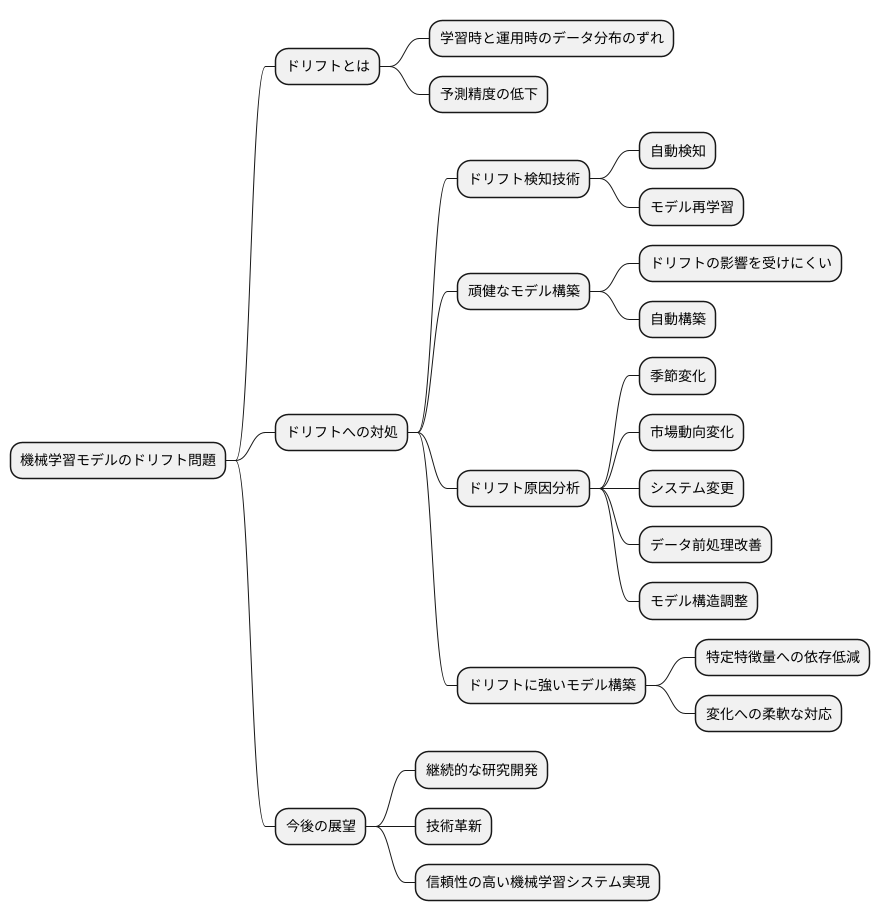
今後の展望

機械学習の予測モデルは、時間の経過と共に予測精度が低下することがあります。これは、学習時と運用時のデータの分布にずれが生じる「ドリフト」と呼ばれる現象が原因です。このドリフトへの適切な対処は、機械学習モデルを安定して運用していく上で非常に重要な課題となっています。
今後、ドリフトの検知と対応に関する技術は、さらに進化していくと予想されます。例えば、自動でドリフトを検知し、モデルを再学習させる技術や、ドリフトの影響を受けにくい、頑健なモデルを自動的に構築する技術などが研究されています。これらの技術が発展することで、ドリフトによる悪影響を最小限に抑え、より安定した予測モデルの運用が可能になると期待されます。
また、ドリフトの原因を自動的に分析する技術の開発も重要です。データの分布の変化には様々な要因が考えられます。例えば、季節の変化や市場動向の変化、システムの変更などが挙げられます。これらの要因を特定することで、より効果的な対策を立てることが可能になります。原因が分かれば、データの前処理方法を改善したり、モデルの構造を調整したりすることで、ドリフトの影響を軽減することができます。
さらに、ドリフトに強いモデルの構築も重要です。例えば、特定の特徴量に過度に依存しないモデルや、変化に柔軟に対応できるモデルなどが考えられます。このようなモデルは、データの分布が変化しても、安定した予測性能を維持することができます。
機械学習の活用範囲は、様々な分野で広がり続けています。それに伴い、ドリフトへの対応の重要性はますます高まっています。継続的な研究開発と技術革新によって、ドリフトの問題を克服し、より信頼性の高い機械学習システムを実現することが、今後の発展に不可欠です。