
損失関数:機械学習の心臓部

AIを知りたい
先生、「損失関数」って、何ですか?よく聞くんですけど、難しそうで…

AIエンジニア
そうだね、難しそうだよね。「損失関数」は、機械学習のモデルが、どれだけ学習データと違っているかを測るためのものだよ。例えるなら、弓矢で的当てをしているとしよう。的に当たらないと、的の中心との距離があるよね? その距離が大きいほど、下手くそだってことがわかる。この「的の中心との距離」にあたるのが「損失」で、それを計算するための方法が「損失関数」なんだ。
AIを知りたい
なるほど。つまり、損失が小さいほど、モデルが良いということですね?
AIエンジニア
その通り! だから、機械学習では、この「損失」をできるだけ小さくするように、モデルを調整していくんだ。ちょうど、弓矢の練習で、何度も射って、的に当たるように腕を磨くのと同じようにね。
損失関数とは。
人工知能の分野でよく使われる「損失関数」について説明します。機械学習では、学習の良し悪しを数値で測る必要があります。この数値のことを「損失」と呼び、その損失を計算するための計算式が「損失関数」です。この損失の値をできるだけ小さくしたり、場合によっては大きくしたりすることで、機械学習のモデルをより良いものへと調整していきます。
損失関数とは

機械学習は、与えられた情報から規則性を見つけ出し、それを元にまだ知らない情報について予測する技術です。この学習の過程で、作り出した予測モデルの良し悪しを評価するために、損失関数というものが使われます。損失関数は、モデルが予測した値と、実際の値との間のずれを数値で表すものです。このずれが小さければ小さいほど、モデルの予測が正確であることを意味します。
例えて言うなら、弓矢で的を狙うことを考えてみましょう。的の中心に近いほど、予測が正確で、損失は小さくなります。逆に、中心から遠いほど、予測が不正確で、損失は大きくなります。損失関数は、矢が中心からどれくらい離れているかを測る役割を果たします。
機械学習の目的は、この損失関数の値を可能な限り小さくすることです。言い換えれば、矢を出来るだけ的の中心に近づけるように、モデルを調整していくということです。この調整は、モデル内部の様々な設定値(パラメータ)を少しずつ変えることで行われます。
損失関数の値を最小にする最適なパラメータを見つけることで、最も精度の高い予測を実現できるモデルを作ることができます。損失関数の種類は様々で、予測するものの種類や性質によって適切なものが異なります。例えば、回帰問題によく用いられる二乗誤差や、分類問題によく用いられる交差エントロピーなどがあります。それぞれの特性を理解し、適切な損失関数を用いることが、精度の高い機械学習モデルを構築する上で重要です。
| 用語 | 説明 | 弓矢の例え |
|---|---|---|
| 機械学習 | データから規則性を見出し、未知の情報を予測する技術 | 弓矢で的を射る技術 |
| 損失関数 | 予測値と実測値のずれを数値化したもの。ずれが小さいほど予測が正確。 | 矢が中心からどれくらい離れているかを測るもの |
| 機械学習の目的 | 損失関数の値を最小化すること | 矢を出来るだけ中心に近づけること |
| パラメータ | モデル内部の設定値。調整することでモデルの精度を上げる | 弓の調整、矢の角度など |
| 損失関数の種類 | 予測の種類や性質によって適切なものが異なる(例:二乗誤差、交差エントロピー) | 距離の測り方 |
損失関数の種類

機械学習では、学習した模型の良し悪しを評価するために、損失関数と呼ばれる指標を用います。この損失関数は、様々な種類があり、扱う問題やデータの性質に合わせて適切なものを選ぶ必要があります。大きく分けて、数値を予測する回帰問題と、種類を予測する分類問題で用いられる損失関数が異なります。
まず、回帰問題でよく使われる損失関数を見てみましょう。代表的なものとして、平均二乗誤差と平均絶対誤差があります。平均二乗誤差は、予測値と実際の値の差を二乗したものの平均値です。この損失関数は、大きな誤差をより強く捉えるという特徴があります。例えば、あるデータの予測値と実際の値の差が大きい場合、その差を二乗することで、損失への影響がより大きくなります。一方で、平均絶対誤差は、予測値と実際の値の差の絶対値の平均値です。こちらは、平均二乗誤差に比べて、外れ値と呼ばれる大きく外れた値の影響を受けにくいという利点があります。つまり、一部の極端に大きな誤差があっても、全体の損失値への影響が小さくなります。
次に、分類問題で用いられる損失関数について説明します。分類問題では、クロスエントロピー誤差やヒンジ損失がよく用いられます。クロスエントロピー誤差は、予測された確率分布と実際の確率分布のずれ具合を評価します。予測が正しい確率が高いほど、この値は小さくなります。例えば、画像認識で猫を認識するタスクを考えます。猫の画像を入力した際に、模型が「猫である確率90%、犬である確率10%」と予測した場合、クロスエントロピー誤差は比較的小さくなります。しかし、「猫である確率50%、犬である確率50%」と予測した場合は、誤差は大きくなります。もう一つのヒンジ損失は、主にサポートベクターマシンと呼ばれる学習方法で使われます。ヒンジ損失は、正しく分類されたデータ点と、分類の境界線との距離(マージン)を最大化するように設計されています。境界線から遠いデータ点ほど、損失への影響は小さくなります。このように、様々な損失関数があり、それぞれ異なる特徴を持っているので、問題に合わせて適切に選択する必要があります。適切な損失関数を選ぶことで、より精度の高い模型を学習することができます。
| 問題の種類 | 損失関数 | 説明 | 特徴 |
|---|---|---|---|
| 回帰問題 | 平均二乗誤差 | 予測値と実際の値の差を二乗したものの平均値 | 大きな誤差をより強く捉える |
| 平均絶対誤差 | 予測値と実際の値の差の絶対値の平均値 | 外れ値の影響を受けにくい | |
| 分類問題 | クロスエントロピー誤差 | 予測された確率分布と実際の確率分布のずれ具合を評価 | 予測が正しい確率が高いほど、値は小さくなる |
| ヒンジ損失 | 正しく分類されたデータ点と分類の境界線との距離(マージン)を最大化 | 境界線から遠いデータ点ほど、損失への影響は小さい |
最適化との関係

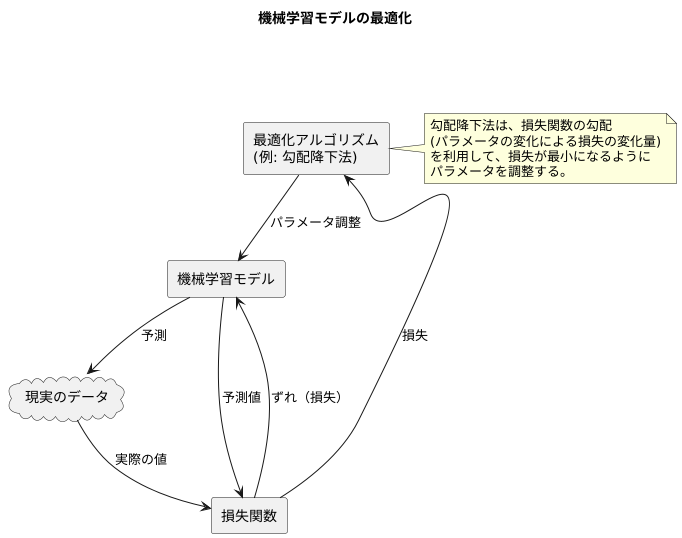
機械学習のモデルを作る際には、そのモデルがどれくらいうまく現実を捉えているかを測る必要があります。この測り方を損失関数と呼びます。損失関数は、モデルの予測と実際の値との間のずれを数値化したものと言えるでしょう。このずれが小さければ小さいほど、モデルの性能が良いと判断できます。
この損失関数を最小にすることが、モデルの最適化です。最適化とは、モデルが持つ様々な調整つまみ、つまりパラメータを調整して、損失関数の値をできるだけ小さくする作業です。ちょうど、ラジオの周波数を少しずつ調整して、一番クリアに聞こえる場所を探すようなものです。
この最適化を行う際に、よく使われる方法の一つが勾配降下法です。勾配降下法は、山の斜面を下っていくように、損失関数が小さくなる方向へパラメータを調整する方法です。山の斜面の傾きが急なほど、つまり損失関数の勾配が大きいほど、パラメータの調整幅も大きくなります。逆に、傾きが緩やかになるにつれて、調整幅も小さくなり、最終的には谷底、つまり損失関数の最小値にたどり着きます。
損失関数の勾配は、各パラメータを少しだけ変化させたときに、損失関数の値がどれくらい変化するかを表しています。この勾配の情報を使うことで、どのパラメータを、どの程度調整すれば、損失関数を効率的に小さくできるかが分かります。
最適化アルゴリズムは、いわば損失関数の最小値へと導く道案内人です。様々な種類の道案内人が存在し、それぞれに特徴があります。勾配降下法はその中でも代表的なもので、機械学習モデルの学習を成功させるための重要な役割を担っています。適切な道案内人を選ぶことで、より早く、より正確に、最適なモデルを作ることができるのです。
モデル評価との関連

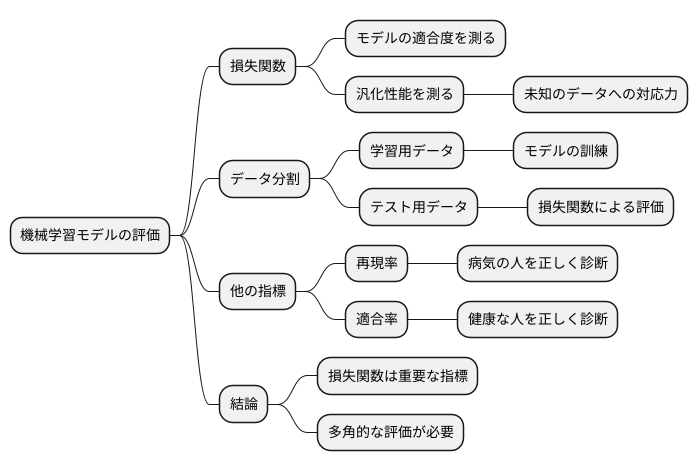
機械学習モデルを作る上で、その良し悪しを見極めることはとても大切です。この良し悪しを測るための物差しの一つが損失関数です。損失関数は、モデルがどれくらい学習データに適合しているかを測るだけでなく、まだ知らないデータにどれくらい対応できるかどうかも測るために使われます。
モデルを作る際には、集めたデータを学習用とテスト用に分けます。学習用データでモデルを鍛え、テスト用データで実際の現場でどれくらい使えるかを調べます。このテストの際に損失関数が活躍します。テスト用データを使って損失関数の値を計算することで、未知のデータに対する予測の正確さを評価できるのです。この未知のデータへの対応力は汎化性能と呼ばれ、機械学習モデルの重要な能力です。
損失関数の値が小さければ小さいほど、汎化性能が高い、つまり未知のデータにもうまく対応できる良いモデルと言えます。しかし、損失関数の値だけで判断するのは早計です。損失関数はモデルの性能を測る一つの指標に過ぎません。例えば、病気の有無を診断するモデルでは、病気の人を正しく病気と判断できるか(再現率)や、健康な人を正しく健康と判断できるか(適合率)といった他の指標も重要になります。これらの指標も合わせて見ることで、多角的にモデルの性能を評価し、本当に使える良いモデルかどうかを判断できます。損失関数は、モデルの学習から評価まで、モデル作り全体を通して重要な役割を担っているのです。
今後の展望

機械学習という技術は、まるで生き物のように常に進化を続けています。その進化を支える重要な要素の一つに、損失関数と呼ばれるものがあります。この関数は、機械が学習する際の道しるべのような役割を果たします。機械は、この損失関数を最小にするように学習を進めることで、より正確な予測や判断ができるようになるのです。
近年、様々な新しい損失関数が開発されています。例えば、「敵対的生成ネットワーク」略して「敵生成網」と呼ばれる技術があります。この技術では、二つのネットワーク、いわば二人の弟子が競い合うように学習を進めます。一人は絵を描く弟子、もう一人は絵を評価する弟子です。絵を描く弟子は、評価する弟子を騙せるような、より本物に近い絵を描こうとします。一方、評価する弟子は、本物の絵と偽物の絵を見分けられるように、目を鍛えます。このように、二人の弟子が異なる損失関数を用いて切磋琢磨することで、より高度な学習を可能にしています。
また、特定の作業に特化した損失関数も開発されています。例えば、写真の識別作業では、写真同士の似ている度合いを考慮した損失関数が用いられることがあります。これにより、機械は写真の微妙な違いを認識し、より正確な識別ができるようになります。
このように、損失関数の研究は、機械学習の進化にとって欠かせないものです。今後、より複雑で高度な機械学習の仕組みが開発されるにつれて、それに合わせた新しい損失関数の開発もますます重要になってくるでしょう。まるで、新しい技術の進歩に合わせて、より精緻な道しるべが必要になるように。損失関数の更なる発展によって、機械学習は私たちの生活をより豊かに、より便利にしてくれると期待されています。
| 損失関数概要 | 説明 | 例 |
|---|---|---|
| 役割 | 機械学習における道しるべ。関数を最小化することで、機械は正確な予測や判断を行う。 | – |
| 敵対的生成ネットワーク(敵生成網) | 二つのネットワーク(絵を描く弟子、絵を評価する弟子)が競い合うように学習。それぞれのネットワークが異なる損失関数を用いることで、高度な学習が可能。 | 絵を描く弟子:評価する弟子を騙せるような本物に近い絵を描く 評価する弟子:本物の絵と偽物の絵を見分ける |
| 特定作業向け損失関数 | 特定の作業に特化した損失関数を用いることで、より正確な結果を得られる。 | 写真の識別作業:写真同士の似ている度合いを考慮した損失関数 |