
画像認識精度向上のためのデータ拡張入門

AIを知りたい
『いろいろなデータ拡張』って、画像をちょっとずつ変えてたくさん作るってことですよね?でも、なんでそんなことする必要があるんですか?

AIエンジニア
いい質問ですね。たとえば、猫を認識するAIを作るときは、色々な種類の猫の画像をたくさん学習させる必要があります。でも、あらゆる種類の猫の写真を全部集めるのは大変ですよね?
AIを知りたい
確かに、全部集めるのは無理そうです…。
AIエンジニア
そこで、持っている猫の画像を少しだけ変えて、例えば左右反転させたり、少し回転させたりすることで、色々なバリエーションの猫の画像を擬似的に作り出すんです。こうすることで、少ない元画像からたくさんの学習データを作れるので、AIの精度が上がりやすくなります。
各種データ拡張とは。
人工知能に関係する言葉である「色々なデータを増やす方法」について説明します。
「データを増やす」とは、今持っている画像に手を加えて、まるで違う画像を作り出すことです。
例えば、ものを正しく認識させるためには、色々なパターンの画像データが必要です。しかし、考えられる全てのパターンの画像をあらかじめ用意しておくことは、ほとんどできません。
そこで、データを増やす方法が役に立ちます。簡単な例としては、画像を上下左右にずらしたり、ひっくり返したり、大きくしたり小さくしたり、回転させたりすることなどがあります。
データ拡張とは

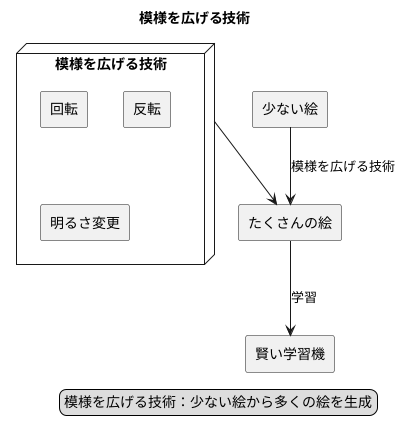
模様を認識する学習機を作るには、たくさんの模様の絵が必要です。しかし、たくさんの絵を集めるのは大変な仕事です。そこで、少ない絵からたくさんの絵を作り出す方法があります。これが、模様を広げる技術です。
模様を広げる技術は、持っている絵を少しだけ変えることで新しい絵を作ります。例えば、猫の絵を少し回転させたり、左右を反転させたり、明るさを変えたりします。こうすることで、元の猫の絵と少しだけ違う、新しい猫の絵が作れます。
学習機は、たくさんの種類の絵を見て学習することで、賢くなります。しかし、同じ猫の絵ばかり見ていても、あまり賢くなりません。色々な種類の猫の絵、例えば、色々な向きで色々な明るさの猫の絵を見ることで、どんな猫の絵を見ても猫だと分かるようになります。模様を広げる技術を使うと、少ない絵から色々な種類の絵を作ることができ、学習機を賢くすることができます。
模様を広げる技術は、料理に例えることができます。少ない材料でも、色々な工夫をすることで、たくさんの料理を作ることができます。例えば、野菜を切ったり、煮たり、焼いたりすることで、色々な料理を作ることができます。模様を広げる技術も、少ない絵から色々な絵を作ることで、学習機の学習を助けます。
このように、模様を広げる技術は、学習機を賢くするための大切な技術です。限られた絵から、たくさんの絵を作り出すことで、学習機は色々な模様を覚えることができます。そして、初めて見る模様でも、それが何かを正しく認識できるようになります。
データ拡張の種類

画像データを増やすための技術、データ拡張には様々な種類があります。それぞれ画像に異なる変化を加えることで、実際には撮影していない画像を作り出すことができます。これは、まるで写真の被写体を様々に動かしたり、レンズの倍率を変えたりするようなものです。
まず、平行移動は画像を上下左右にずらす技術です。被写体が画面の真ん中からずれた写真や、画面の外に少しはみ出た写真などを作り出すことができます。まるでカメラを少し動かして被写体を捉え直したような効果です。これにより、被写体が様々な位置にある状況を再現できます。
次に、回転は画像を任意の角度で回転させる技術です。被写体が傾いた写真を作ることで、例えば立っている人が少し体を傾けている様子や、物が斜めに置かれている様子を表現できます。これにより、被写体の向きが様々な方向を向いている状況を再現できます。
反転は画像を左右、または上下に反転させる技術です。左右の反転は鏡に映したような効果を生み出し、上下の反転は逆さまにしたような効果を生み出します。左右対称の被写体の場合、反転によって新たなデータを作り出す効果は薄いですが、非対称の被写体であれば、反転によって新たな情報をモデルに学習させることができます。
拡大・縮小は画像のサイズを変える技術です。被写体を大きくしたり小さくしたりすることで、まるでカメラのズーム機能を使ったように、被写体との距離感が変わったように見せることができます。被写体が近づけば大きく見え、遠ざかれば小さく見えるという、現実世界での見え方の変化を再現できます。
これらの技術は、単独で使うことも、組み合わせて使うこともできます。例えば、画像を回転させてから平行移動させることで、被写体が傾いて、かつ画面の中心からずれた画像を作り出すことができます。このように複数の技術を組み合わせることで、より複雑で多様な画像を作り出し、学習データの量と質を向上させることができます。データ拡張によって、様々なバリエーションの画像を学習させることで、学習モデルは特定の状況に偏ることなく、より多くの状況に対応できるようになります。
| データ拡張技術 | 説明 | 効果 |
|---|---|---|
| 平行移動 | 画像を上下左右にずらす。 | 被写体が様々な位置にある状況を再現。 |
| 回転 | 画像を任意の角度で回転させる。 | 被写体の向きが様々な方向を向いている状況を再現。 |
| 反転 | 画像を左右、または上下に反転させる。 | 鏡に映したり、逆さまにしたような効果。非対称の被写体であれば新たな情報を学習させることができる。 |
| 拡大・縮小 | 画像のサイズを変える。 | 被写体との距離感が変わったように見せる。 |
データ拡張の利点

機械学習モデルの性能を高める上で、データ拡張は非常に有効な手法です。この手法を用いることで、様々な恩恵を受けることができます。まず、データ拡張の最も大きな利点は、過学習の抑制です。過学習とは、学習に用いたデータの特徴にモデルが過剰に適応しすぎて、新しいデータに対してうまく対応できない状態を指します。あたかも、特定の問題集の解答だけを丸暗記した生徒が、少し問題文が変わっただけで解けなくなってしまうようなものです。データ拡張は、既存のデータに様々な変換を加えることで、学習データのバリエーションを増やします。たとえば、画像データであれば、回転、拡大縮小、色の変更などを行うことで、元のデータとは少し異なる新たなデータを作り出すことができます。これにより、モデルは特定のデータの特徴に固執することなく、より汎用的な特徴を学習できるようになります。結果として、未知のデータに対しても高い精度で予測できるようになり、モデルの汎化性能が向上します。
次に、データ拡張はデータ収集の手間と費用を削減するのにも役立ちます。機械学習モデルの学習には、大量のデータが必要となることが一般的です。しかし、現実世界で多様なデータを収集することは、時間と費用がかかる作業です。データ拡張を活用すれば、既存のデータから人工的に新しいデータを生成することができるため、データ収集にかかる負担を大幅に軽減できます。必要なデータ量を確保するために、多大な労力をかけてデータを集める必要がなくなるため、開発期間の短縮にも繋がります。
さらに、データのプライバシー保護の観点からも、データ拡張は有効な手段です。例えば、個人の顔写真などの機密性の高いデータを学習に用いる場合、データの漏洩リスクを低減する必要があります。データ拡張を用いて画像データに加工を施すことで、個人を特定しにくくしながらも、モデル学習に必要なデータとしての価値を維持することができます。このように、データ拡張はプライバシー保護とモデル性能向上を両立させるための、有用なツールと言えるでしょう。
| メリット | 説明 |
|---|---|
| 過学習の抑制 | 学習データのバリエーションを増やすことで、モデルが特定のデータの特徴に固執することなく、より汎用的な特徴を学習できるようになる。結果として、未知のデータに対しても高い精度で予測できるようになり、モデルの汎化性能が向上する。 |
| データ収集の手間と費用の削減 | 既存のデータから人工的に新しいデータを生成することで、データ収集にかかる負担を軽減し、開発期間の短縮にも繋がる。 |
| データのプライバシー保護 | 画像データに加工を施すことで、個人を特定しにくくしながらも、モデル学習に必要なデータとしての価値を維持することができる。 |
データ拡張の適用事例

情報の増やし方は、人の目や耳が学ぶのと同じように、様々な場面を想定して行います。例えば、写真の明るさや色合いを変えたり、左右を反転させたり、ノイズを加えたりすることで、実際には撮影していない画像を作り出せます。この技術は、物の見分け方や写真の分類、写真の特定部分の抽出など、幅広い用途で使われています。
自動運転技術の開発では、この技術が欠かせません。晴天の日の写真だけでなく、雨や雪の日の写真、昼と夜の写真など、様々な条件の画像を人工的に作り出すことで、どんな状況でも安全に運転できる車の学習に役立てています。また、医療の分野でも、この技術は重要な役割を担っています。例えば、病気の診断に使う画像データは、数が限られている場合が多いです。そこで、少ない画像データを基に様々なバリエーションの画像を作り出し、診断の正確さを高めるのに役立てています。
言葉の学習においても、この技術は力を発揮します。文章を少し変えたり、単語の順番を入れ替えたりすることで、実際には書かれていない文章を作り出せます。これにより、機械翻訳や言葉の感情を読み取る技術の向上に繋がります。さらに、音声の学習でも、この技術は有効です。音の高さや速さを変えたり、雑音を加えたりすることで、実際には録音していない音声を作り出せます。これにより、周りの騒音が大きい場所でも正確に音声を認識できる技術の開発に役立ちます。
このように、情報の増やし方は、機械学習の様々な分野で必要不可欠な技術となっています。この技術によって、限られた情報から多くの学びを得ることができ、将来、さらに技術が発展していくことが期待されます。
| 分野 | 情報の増やし方 | 用途 |
|---|---|---|
| 画像認識 | 明るさ、色合い、反転、ノイズ追加など | 物の見分け方、写真の分類、写真の特定部分の抽出、自動運転、医療診断 |
| 自然言語処理 | 文章の変更、単語の順番入れ替え | 機械翻訳、感情分析 |
| 音声認識 | 音の高低、速度変更、雑音追加 | ノイズ除去、音声認識 |
データ拡張の注意点

情報を増やし、学習の効果を高める技術であるデータ拡張は、使い方を誤ると、せっかくの学習がうまくいかなくなることがあります。まるで料理と同じで、良い素材を使っても、調理方法を間違えると、おいしくなくなってしまうのと同じです。
例えば、画像を扱う場合を考えてみましょう。学習に使う画像を回転させたり、拡大縮小したりすることで、データの数を増やすことができます。しかし、回転の角度が大きすぎたり、拡大縮小の比率が過度になると、画像の情報が失われてしまいます。料理で例えるなら、食材を焼きすぎて焦がしてしまったり、煮込みすぎて形がなくなってしまうようなものです。こうなると、何が写っているのか分からなくなり、学習の妨げとなります。
また、データの種類に応じた適切な方法を選ぶことも大切です。例えば、医療用の画像を考えてみましょう。健康診断で使うレントゲン写真などは、少しの変化も見逃せない重要な情報を含んでいます。このような画像に、一般的な画像と同じようにデータ拡張を適用すると、実際には存在しない病変を作り出してしまう可能性があります。これは、料理に不要な調味料を大量に入れて、味を壊してしまうようなものです。
データ拡張を行う際には、まずデータの特徴をしっかり理解することが重要です。どのような変化を加えても問題ないのか、どの程度の変化まで許容されるのかを判断する必要があります。そして、データの加工後には、加工したデータが元の情報と矛盾していないかを確認する必要があります。例えば、画像を反転させた場合、元の画像に付けられていたラベル(説明書き)が、反転後の画像にも適切かどうかを確認する必要があります。料理で言えば、味付けを変えた後に、味見をして確認するようなものです。
このように、データ拡張は、慎重かつ適切に利用することで、学習の効果を高める強力な道具となります。データの特徴を理解し、適切な方法を選ぶことが、データ拡張を成功させる鍵となります。
| 料理の例え | データ拡張における問題点 | データ拡張における注意点 |
|---|---|---|
| 食材を焼きすぎて焦がす 煮込みすぎて形がなくなる |
回転角度が大きすぎる 拡大縮小の比率が過度 |
画像の情報が失われない程度の回転・拡大縮小 |
| 不要な調味料を大量に入れて味を壊す | 医療用画像に一般的なデータ拡張を適用し、存在しない病変を作り出す | データの種類に適したデータ拡張方法を選択 |
| 味付けを変えた後に味見をする | 加工後のデータが元の情報と矛盾していないか確認 (例: ラベルの適切性) |
データ加工後に確認作業を行う |
| 良い素材を使っても、調理方法を間違えるとおいしくなくなる | データ拡張の使い方を誤ると学習がうまくいかない | データの特徴を理解し、適切な方法を選ぶ |
今後の展望

今後のデータ拡張技術は、機械学習の進歩を支える重要な役割を担うと考えられます。深層学習を中心とした技術革新により、データ拡張は更なる進化を遂げるでしょう。
まず、画像データを例に挙げると、従来の手法では回転や反転といった単純な操作が中心でした。しかし、近年では敵対的生成ネットワークのような高度な生成モデルを用いることで、より本物に近い画像を作り出すことが可能になっています。これにより、限られたデータから大量の学習用データを作り出し、より精度の高い画像認識モデルの構築が可能になるでしょう。また、画像だけでなく、音声や文章など、様々な種類のデータに対しても、深層学習を用いたデータ拡張技術の開発が期待されています。
加えて、データ拡張技術の自動化も重要な研究分野です。これまでは、データの種類や特性に応じて、適切なデータ拡張手法を手作業で選定する必要がありました。しかし、今後、機械学習を用いて自動的に最適なデータ拡張方法を探索する技術が確立されれば、より効率的に高精度なモデルを構築できるようになるでしょう。これは、専門知識を持たない人でも、容易にデータ拡張技術を活用できるようになることを意味します。
さらに、個人情報保護の観点からも、データ拡張技術は重要性を増しています。個人情報を含むデータを機械学習に利用する場合、プライバシー保護の観点からデータの加工や匿名化が必要となります。データ拡張技術は、個人が特定できないようなデータを生成することで、プライバシーを守りながら機械学習を行うことを可能にします。今後、社会全体でデータの利活用が進むにつれて、データ拡張技術はプライバシー保護のための重要な手段として、ますます注目を集めるでしょう。
このように、データ拡張技術は、機械学習の発展を支えるだけでなく、データのプライバシー保護にも貢献する重要な技術です。今後、様々な分野での応用が期待され、更なる発展が期待されます。
| 項目 | 内容 |
|---|---|
| 画像データ拡張 | 従来:回転・反転などの単純な操作 近年:敵対的生成ネットワーク(GAN)などによる高精度な生成モデル 効果:限られたデータから大量の学習用データ生成、高精度な画像認識モデル構築 |
| 音声・テキストデータ拡張 | 深層学習を用いた技術開発に期待 |
| データ拡張の自動化 | 従来:データ特性に合わせた手動での拡張手法選定 今後:機械学習による最適な拡張方法の自動探索 効果:効率的な高精度モデル構築、非専門家による活用促進 |
| プライバシー保護 | 個人情報を含むデータの加工・匿名化 データ拡張による個人が特定できないデータ生成 効果:プライバシー保護しながら機械学習の実現 |