
推定:データの背後にある真実を探る

AIを知りたい
先生、「推定」ってどういう意味ですか?よくわからないです。

AIエンジニア
そうですね。推定とは、既に知っている知識を使って、未知のものを予測することです。例えば、山の形をしたデータがあったとします。この山の形は、頂上の位置と山の広がり方で決まりますよね。この頂上の位置や広がり方を計算することを推定と言います。
AIを知りたい
山の頂上の位置や広がり方ですか?具体的にはどのように計算するのでしょうか?
AIエンジニア
たくさんのデータから、平均や分散といった値を計算することで、山の形を決めることができます。そして、これらの計算された値を使って、まだ知らないデータに対しても予測ができるのです。
推定とは。
人工知能でよく使われる「推定」という言葉について説明します。推定とは、学習済みの計算方法にデータを入力して結果を得る作業のことです。すでに分かっている様々なデータの分布の形と、今手元にあるデータの形を比べて、似ている分布を見つけ出すのが推定です。例えば、正規分布は山の形をしていて、山の頂上の位置(平均)と山の広がり(分散)の2つが決まれば山の形が決まります。推定の役割は、データがある分布と同じ形をしているなら、その分布の形を決める値を計算することです。
推定とは何か

推定とは、既に学習を終えた計算模型を使って、未知の情報の予測を行うことです。 これは、過去の情報から規則性や繋がりを学び、それを基にまだ知らない情報を予想する作業と言えます。 例えば、過去の販売記録から将来の販売数を予想したり、顧客の買い物記録から好みそうな商品を勧めるといった場面で、推定は大切な働きをしています。
推定の過程を詳しく見てみましょう。まず、過去のデータを集めて、計算模型に学習させます。この学習過程では、データの中に潜む規則性やパターンを模型が見つけ出すように調整していきます。例えば、気温が上がるとアイスクリームの販売数も増えるといった関係性を、データから学習させるのです。学習が完了すると、その計算模型は未知のデータに対しても予測を行うことができるようになります。例えば、明日の気温が分かれば、学習した関係性を用いて明日のアイスクリームの販売数を予測することができるのです。
推定は、まるで名探偵がわずかな手がかりから犯人を推理するような作業と言えるでしょう。 多くの情報の中から重要な手がかりを選び出し、論理的に考えて結論を導き出す必要があるからです。ただし、推定は必ずしも正確な答えを導き出すとは限りません。学習に用いたデータの質や量、計算模型の種類などによって、予測の精度は大きく左右されます。 過去のデータには限界があり、未来は常に予測通りに進むとは限らないからです。 推定は、あくまでも過去の情報に基づいた予測であり、その結果には常に不確実性が伴うことを忘れてはなりません。
それでも、推定は私たちの生活の中で様々な場面で活用されています。天気予報、株価予測、医療診断など、推定は私たちの意思決定を支える重要な情報源となっています。 推定結果を鵜呑みにするのではなく、その背後にある考え方や限界を理解した上で活用することが大切です。
推定の仕組み

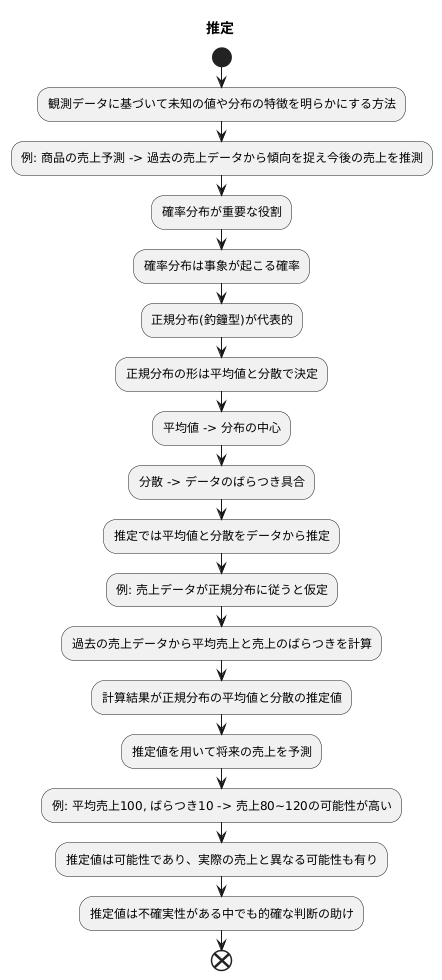
推定とは、観測されたデータに基づいて、未知の値や分布の特徴を明らかにする方法です。 例えば、ある商品の売上の将来予測をしたい場合、過去の売上データから売上の傾向を捉え、今後の売上を推測します。このような予測を行う際に重要な役割を果たすのが「確率分布」です。
確率分布は、ある事象がどのくらいの確率で起こるかを表すものです。数多くの種類がありますが、中でも「正規分布」は自然界や社会現象でよく見られる、代表的な確率分布です。正規分布は左右対称の釣鐘型をしており、その形は平均値と分散という二つの値によって決まります。 平均値は分布の中心を表し、分散はデータのばらつき具合を表します。分散が小さいほどデータは平均値の近くに集中し、分散が大きいほどデータは平均値から広く散らばります。
推定では、この平均値と分散をデータから推定します。 例えば、商品の売上データが正規分布に従うと仮定した場合、過去の売上データから平均売上と売上のばらつきを計算します。これらの計算結果が、正規分布の平均値と分散の推定値となります。
こうして得られた推定値を用いることで、将来の売上の予測が可能になります。例えば、平均売上が100で、売上のばらつきが10だと推定された場合、将来の売上は80から120の間になる可能性が高いと予測できます。もちろん、これはあくまで可能性であり、実際の売上はこれと異なる値になる可能性もあります。しかし、推定によって得られた情報は、不確実性がある中でもより的確な判断を行うための助けとなります。
このように、推定は観測データから未知の値を推測するだけでなく、確率分布を用いることで、将来の予測や意思決定に役立つ情報を提供してくれるのです。
推定の種類

統計学における推定とは、観察されたデータに基づいて、母集団の特性を推測する手続きのことです。推定には大きく分けて二つの種類があります。一つは「母数推定」と呼ばれるもので、もう一つは「非母数推定」と呼ばれるものです。それぞれの特徴を詳しく見ていきましょう。
まず、母数推定について説明します。母数推定では、データが特定の確率分布(例えば、正規分布や二項分布など)に従うと仮定します。これらの分布は、平均値や分散といった少数の「母数」と呼ばれる数値によって特徴づけられます。母数推定では、観測されたデータからこれらの母数の値を推測します。例えば、データが正規分布に従うと仮定した場合、母数推定によって母集団の平均値と分散を推定することができます。この方法は、データの背後にある確率分布が分かっている場合に有効であり、比較的少ないデータからでも精度の高い推定を行うことができます。
次に、非母数推定について説明します。非母数推定は、データが特定の確率分布に従うことを仮定しません。つまり、母集団分布について何も知らない場合でも適用できます。この方法は、データの分布に制約を設けないため、様々なデータに適用できるという利点があります。例えば、データの分布が歪んでいる場合や、外れ値が多い場合でも、非母数推定を用いることができます。ただし、一般的に母数推定に比べて多くのデータが必要となる場合があり、推定の精度が劣る可能性もあります。
どちらの方法を用いるかは、データの特性や分析の目的に応じて適切に選択する必要があります。もしデータが正規分布に近い形をしている場合は、母数推定が有効です。一方、データの分布が不明な場合や、特定の分布に当てはまらない場合は、非母数推定が適しています。適切な推定方法を選択することで、より正確な母集団の特性を推測できます。
| 推定の種類 | 説明 | 利点 | 欠点 | 適用例 |
|---|---|---|---|---|
| 母数推定 | データが特定の確率分布(例:正規分布、二項分布)に従うと仮定し、その分布を特徴づける母数(例:平均値、分散)を推定する。 | 少ないデータでも精度の高い推定が可能。 | データの分布が仮定と異なる場合、推定が不正確になる。 | データが正規分布に近い形をしている場合。 |
| 非母数推定 | データが特定の確率分布に従うことを仮定しない。 | 様々なデータに適用可能。分布の形状に制約されない。 | 母数推定に比べ、多くのデータが必要。推定精度が劣る可能性がある。 | データの分布が不明な場合、特定の分布に当てはまらない場合。 |
推定の活用事例

私たちの身の回りでは、様々な場面で推定が行われています。まるで探偵がわずかな手がかりから真相を推理するように、限られた情報から全体像を捉えようとするのが推定です。
例えば、病院では、医者が患者の訴える症状や検査結果といった情報から、患者の病気を推定します。咳や発熱といった症状、血液検査やレントゲン写真といった検査データは、病気の手がかりとなります。医者はこれらの情報を総合的に判断し、どの病気が考えられるかを推定し、診断を下します。
お金を扱う金融の世界でも推定は欠かせません。日々変化する株式や為替の値動きを予測するために、過去のデータや経済状況などを分析し、将来の値動きを推定します。この推定に基づいて、投資家は投資判断を行います。
商品の売買を行う会社でも推定は活用されています。過去の販売データや顧客の属性、世の中の流行などを分析することで、顧客がどんな商品を求めているのかを推定します。そして、その推定に基づいて新商品の開発や販売戦略を立てます。テレビやインターネットで流れる広告も、消費者の行動を推定した結果に基づいて作られています。
このように、推定は医療、金融、販売といった様々な分野で活用され、私たちの生活を支えています。限られた情報から全体像を明らかにし、将来を予測するために、推定は必要不可欠な手法と言えるでしょう。
| 分野 | 手がかりとなる情報 | 推定する内容 |
|---|---|---|
| 医療 | 患者の訴える症状(咳、発熱など)、検査結果(血液検査、レントゲン写真など) | 患者の病気 |
| 金融 | 過去のデータ、経済状況など | 将来の株式や為替の値動き |
| 販売 | 過去の販売データ、顧客の属性、世の中の流行など | 顧客のニーズ、将来の売れ行き |
推定と機械学習

推定とは、既知の情報をもとに未知の事柄を論理的に導き出すことです。これは、機械学習においても中心的な役割を担っています。機械学習は、大量のデータから規則性を自動的に見つけ出し、それを利用して未知のデータについて予測を行う技術です。この予測を行う部分がまさに推定にあたります。機械学習モデルは、学習データと呼ばれる既知のデータを使って訓練され、データの中に隠されたパターンや関係性を学習します。まるで職人が経験から技術を磨くように、機械学習モデルもデータから知識を吸収していくのです。そして、十分に学習したモデルを用いて、新たなデータに対して推定を行います。
例えば、天気予報を考えてみましょう。過去の気象データ(気温、湿度、風速など)と実際の天気(晴れ、曇り、雨など)を大量に学習させます。すると、モデルは気象データと天気の関連性を学習し、特定の気象データから未来の天気を推定できるようになります。つまり、明日の気温や湿度、風速などのデータを入力すると、モデルは過去のデータから学習した規則性に基づいて「明日は晴れ」といった予測を出力するのです。このように、機械学習における推定とは、学習済みのモデルを用いて未知のデータに対する予測を行うことを指します。
画像認識も推定の一例です。大量の画像データと、それぞれの画像に何が写っているかという情報(例えば、「猫」「犬」「車」など)をモデルに学習させます。学習後、モデルに新しい画像を入力すると、モデルは画像の特徴を分析し、学習済みのパターンと照らし合わせて、画像に何が写っているかを推定します。 機械学習と推定は、様々な分野で活用されています。医療診断、商品推薦、自動運転など、私たちの生活に深く関わる多くの技術で、機械学習による推定が重要な役割を果たしています。今後、データの活用がますます重要になるにつれて、推定の技術もさらに発展し、私たちの社会をより豊かにしていくことでしょう。
推定の未来

近年の情報量の爆発的な増加と計算機の処理能力の向上は、様々な事柄を予測する技術を大きく進歩させています。特に、人間の脳の仕組みを模倣した「深層学習」と呼ばれる技術の進歩は目覚ましく、従来の方法では解くのが難しかった複雑な問題にも答えを出せるようになってきました。
例えば、人の言葉を扱う分野では、この深層学習を用いた予測によって、まるで人間のように文章を理解したり、文章を作ったりすることが可能になりつつあります。深層学習は大量のデータからパターンや特徴を自動的に学習するため、人間がルールを設定する必要がなく、複雑な現象の予測にも対応できます。この技術によって、文章の自動要約、機械翻訳、質疑応答システムなどの精度が飛躍的に向上し、実用化が進んでいます。また、音声認識の分野でも、深層学習を用いることで、騒音の中でも音声を正確に聞き取ることが可能になり、より自然な音声対話システムの実現に近づいています。
深層学習以外にも、様々な予測技術が開発されています。例えば、統計学に基づく従来の予測手法も、計算機の性能向上によって、より大規模なデータに適用できるようになり、精度の向上が図られています。また、複数の予測モデルを組み合わせることで、それぞれのモデルの弱点を補い、より精度の高い予測を実現する「アンサンブル学習」と呼ばれる手法も注目を集めています。
今後、さらに高度な予測技術が開発されることで、様々な分野で革新的な変化が起きると期待されています。医療分野では、病気の早期発見や個別化医療の実現、製造業では、製品の品質向上や生産効率の最適化、金融分野では、リスク管理や投資判断の高度化など、予測技術の応用範囲は広範です。未来のデータ活用を支える基盤技術として、予測技術はますます重要な役割を担っていくでしょう。膨大なデータから価値ある情報を抽出し、未来を予測する技術は、社会の様々な場面で不可欠な存在となり、私たちの生活をより豊かに、より安全なものにしてくれるでしょう。
| 技術 | 説明 | 応用例 |
|---|---|---|
| 深層学習 (ディープラーニング) | 人間の脳の仕組みを模倣した技術。大量のデータからパターンや特徴を自動的に学習し、複雑な現象の予測に対応。 | 文章の自動要約、機械翻訳、質疑応答システム、音声認識、自然言語処理 |
| 統計学に基づく予測手法 | 従来の予測手法。計算機の性能向上により、大規模データへの適用と精度向上が実現。 | (具体的な応用例は本文に明示的に記載されていない) |
| アンサンブル学習 | 複数の予測モデルを組み合わせることで、それぞれの弱点を補い、精度を高める手法。 | (具体的な応用例は本文に明示的に記載されていない) |