ホールドアウト検証と交差検証

AIを知りたい
先生、ホールドアウト検証とk分割交差検証の違いがよくわからないのですが、教えていただけますか?

AIエンジニア
もちろんです。どちらも機械学習モデルの性能を評価する方法ですが、データの分け方が違います。ホールドアウト検証は、データを訓練用とテスト用に一度だけ分けます。k分割交差検証は、データをk個に分割し、順番に各部分をテスト用データとして使い、残りを訓練用データとして使います。
AIを知りたい
なるほど。一度だけ分けるのと、複数回に分けてテストをするのが違うんですね。ということは、k分割交差検証の方がより正確に評価できるのでしょうか?
AIエンジニア
その通りです。ホールドアウト検証は一度きりの分割なので、たまたま選んだデータによって結果が大きく変わる可能性があります。k分割交差検証は複数回評価を行うため、より安定した、モデルの性能に近い評価結果を得ることができます。
ホールドアウト検証とは。
人工知能に関わる言葉である「ホールドアウト検証」について説明します。この検証方法は、全てのデータを学習用データとテスト用データに分割して行う交差検証のことです。学習用データを使って人工知能モデルを訓練し、テスト用データを使ってその性能を評価します。また、学習用データとテスト用データの分割を複数回繰り返し、それぞれで学習と評価を行う方法をk分割交差検証といいます。
ホールドアウト検証とは

機械学習の良し悪しを確かめる方法の一つに、ホールドアウト検証というものがあります。これは、持っているデータを学習用とテスト用に二つに分けて使う方法です。学習用のデータで機械に学習させ、テスト用のデータでその学習の成果を確かめます。
たとえば、全部のデータのうち八割を学習用、残りの二割をテスト用とします。この分け方は、普通はでたらめに決めますが、データの種類によっては、偏りができないように工夫が必要な場合もあります。たとえば、時間の流れに沿って集めたデータの場合、古いデータを学習用、新しいデータをテスト用にすると良いでしょう。
ホールドアウト検証は、やり方が簡単で、計算の手間も少ないという良い点があります。しかし、データの分け方によって結果が変わってしまうという困った点もあります。たまたま学習用のデータに簡単なものばかりが入っていたり、逆に難しいものばかりが入っていたりすると、機械の本当の実力を正しく測ることができません。
この問題を少しでも軽くするために、データの分け方を変えて何度も検証を行うという方法もあります。たとえば、最初の検証では1番目から80番目のデータを学習用とし、81番目から100番目をテスト用とします。次の検証では、11番目から90番目のデータを学習用、1番目から10番目と91番目から100番目のデータをテスト用とします。このように少しずつずらしながら何度も検証を繰り返すことで、特定のデータの偏りの影響を減らすことができます。そして、それぞれの検証結果の平均を取ることで、より信頼性の高い評価を行うことができます。
ホールドアウト検証は手軽に使える検証方法ですが、データの分け方に注意が必要です。目的に合わせて適切にデータ分割を行い、必要であれば複数回の検証を行うことで、より正確な評価結果を得ることができます。
| 項目 | 内容 |
|---|---|
| 手法 | ホールドアウト検証 |
| 目的 | 機械学習モデルの性能評価 |
| 手順 | データを学習用とテスト用に分割し、学習用データでモデルを学習、テスト用データで性能を評価 |
| 分割比率 | 例:8:2 (学習:テスト) |
| 分割方法 |
|
| メリット |
|
| デメリット | データの分割方法によって結果が変わる可能性がある |
| 対策 |
|
| 注意点 | 目的に合わせて適切にデータ分割を行い、必要であれば複数回の検証を行う |
交差検証の必要性

機械学習モデルの性能をきちんと測るには、交差検証という方法がとても大切です。似た方法にホールドアウト検証というものがありますが、これはデータを訓練用とテスト用に一度だけ分けて検証します。そのため、たまたま分け方が偏ってしまうと、正しい性能が測れないことがあります。例えば、たまたまテストデータに簡単な問題ばかり入っていたら、実際よりも性能が良く見えてしまうかもしれません。
交差検証を使うと、このような偏りを減らすことができます。交差検証では、データをいくつかのグループに分け、それぞれのグループを順番にテストデータとして使います。例えば、5つのグループに分ける場合、最初の検証では1番目のグループがテストデータ、残りの4つのグループが訓練データになります。次の検証では2番目のグループがテストデータ、残りのグループが訓練データになります。これを全てのグループが一度ずつテストデータになるまで繰り返します。
こうして何度も検証することで、特定のデータの分け方に偏ることなく、モデルの性能をより正確に測ることができます。それぞれの検証で得られた結果を平均することで、最終的な性能評価とします。
交差検証の中でも、よく使われるのがk分割交差検証です。これは、データをk個のグループに分けて検証する方法です。kの値は、データの量や計算にかかる時間などを考えて決める必要があります。一般的には、5分割交差検証や10分割交差検証がよく使われます。データが少ない場合は、kの値を小さくすると、より多くのデータで訓練できるため、より信頼性の高い評価ができます。ただし、kの値を小さくしすぎると、検証の回数が減るため、評価の安定性が低下する可能性があります。逆に、データが多い場合は、kの値を大きくすることで、より多くのテストデータを使って評価できますが、計算時間が長くなる可能性があります。
このように、交差検証は、機械学習モデルの性能をより正確に評価するために欠かせない手法と言えるでしょう。
| 検証方法 | データ分割 | メリット | デメリット |
|---|---|---|---|
| ホールドアウト検証 | 訓練用とテスト用に一度だけ分割 | 簡単で計算コストが低い | データの分割方法に偏りがあるため、正しい性能が測れない可能性がある |
| 交差検証 | k個のグループに分割し、各グループを順番にテストデータとして使用 | データ分割の偏りを軽減し、モデルの性能をより正確に測定できる | 計算コストが高い |
| k分割交差検証 | データをk個のグループに分割 | kの値を調整することで、データ量や計算時間に合わせて最適化できる | kの値の設定が重要であり、適切な値を選択する必要がある |
k分割交差検証の詳細

機械学習モデルの性能を正しく測ることはとても大切です。そこでよく使われる手法の一つに、k分割交差検証があります。この手法は、持っている学習データをk個のグループに均等に分けます。そして、そのうちの1つのグループを検証データとして使い、残りのk-1個のグループを学習データとしてモデルの訓練を行います。この訓練と検証を、k個のグループ全てが1回ずつ検証データになるように繰り返します。
例えば、5分割交差検証(k=5)の場合、学習データを5つのグループに分けます。1回目の検証では、1つ目のグループを検証データ、残りの4つのグループを学習データとしてモデルを訓練し、性能を評価します。2回目の検証では、2つ目のグループを検証データ、それ以外の4つのグループを学習データとしてモデルを訓練、評価します。これを全てのグループが検証データになるまで繰り返します。
それぞれの検証では、正解率などの評価指標を計算します。k回の検証が終わると、k個の評価指標の平均値を求めます。この平均値が、モデルの最終的な性能を表す指標となります。1回の検証だけで性能を評価するよりも、k回の検証で得られた平均値を使うことで、より信頼できる性能評価ができます。
さらに、k個の評価指標のばらつき具合も重要な情報です。ばらつきは標準偏差で表され、標準偏差が小さいほど、モデルの性能が安定していると考えられます。つまり、異なるデータに対しても、同じような性能を発揮できるということです。
k分割交差検証は、データを全て学習に使うため、限られた学習データを有効に活用できます。特にデータが少ない場合は、この手法が役に立ちます。ただし、k回の検証を行うため、単純な学習と検証を1回だけ行う手法に比べると、計算に時間がかかります。それでも、より確かな性能評価を得るためには、k分割交差検証は非常に有効な手法と言えるでしょう。
データ分割の注意点

機械学習を行う上で、学習済みモデルの性能をきちんと評価することはとても大切です。そのために、集めたデータを訓練データとテストデータに分割し、訓練データでモデルを学習させ、テストデータでその性能を測ります。このとき、データをどのように分割するかは、モデルの評価精度に大きく影響します。ただ闇雲にデータを分割するのではなく、いくつかの注意点を守る必要があります。
まず、データの偏りについてです。例えば、犬と猫を分類するモデルを作る場合、訓練データに犬の画像ばかり、テストデータに猫の画像ばかりが含まれていたらどうなるでしょうか。モデルは犬の特徴ばかりを学習してしまい、猫を正しく分類できなくなってしまうでしょう。これは極端な例ですが、現実のデータでも同じことが起こり得ます。ある特徴を持ったデータが特定のグループに偏って存在する場合、ランダムに分割するだけでは、偏りがそのまま訓練データとテストデータに反映されてしまいます。このような場合は、層化抽出法と呼ばれる手法を用いることで、各グループのデータが訓練データとテストデータに均等に配分されるように分割できます。こうすることで、偏りの影響を抑え、モデルの真の性能をより正確に評価できます。
次に、時系列データについてです。例えば、過去1年間の株価データから未来の株価を予測するモデルを訓練する場合を考えてみましょう。このとき、ランダムにデータを分割してしまうと、未来のデータが訓練データに含まれ、過去のデータがテストデータに含まれるという状況が発生する可能性があります。これは、まるで未来の答えを見てから過去の出来事を予測するようなものです。当然、モデルは高い性能を示しますが、これは不正行為です。現実の予測では未来の情報は使えません。時系列データの場合は、時間の流れを尊重し、古いデータを訓練データ、新しいデータをテストデータとして分割する必要があります。
このように、データを分割する際には、データの特性をしっかりと理解し、適切な方法を選択することがモデルの性能を正しく評価するために不可欠です。闇雲にデータを分割するのではなく、偏りや時系列といった要素を考慮することで、より信頼性の高い評価結果を得ることができます。
| データの種類 | 分割時の注意点 | 手法 |
|---|---|---|
| 偏りのあるデータ | 特定の特徴を持ったデータが特定のグループに偏って存在する場合、ランダムに分割すると偏りが訓練データとテストデータに反映されてしまう。 | 層化抽出法 |
| 時系列データ | ランダムに分割すると、未来のデータが訓練データに含まれ、過去のデータがテストデータに含まれる状況が発生する可能性がある。 | 古いデータを訓練データ、新しいデータをテストデータとして分割 |
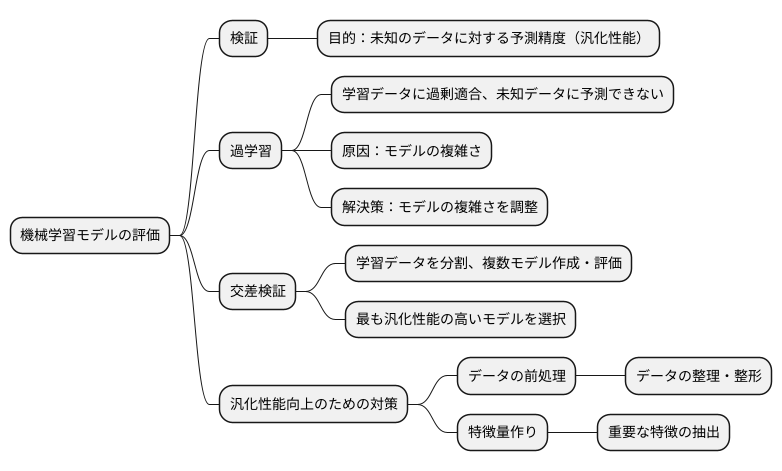
検証における目的

機械学習モデルを作る上で、そのモデルがどれほど役立つかを測ることはとても大切です。この測り方を検証と言い、色々な検証方法がありますが、どれも目的は同じです。それは、未知のデータに対して、そのモデルがどれくらい正確に予測できるかを確かめることです。この力を汎化性能と呼びます。
作ったモデルが、学習に使ったデータに対しては完璧な予測をしても、新しいデータに対してはさっぱり予測できない、ということがよくあります。これは、まるで試験のために教科書を丸暗記した生徒が、教科書に載っていない問題には全く答えられないようなものです。このような状態を過学習と呼びます。過学習は、モデルが学習データの特徴を捉えすぎて、本来注目すべき本質を見失っている状態と言えるでしょう。
過学習を防ぐには、モデルの複雑さを調整する必要があります。モデルが複雑すぎると、学習データの細かな特徴にまで過剰に適合してしまい、汎化性能が低下します。反対に、モデルが単純すぎると、データの本質的な特徴を捉えきれず、やはり汎化性能が低下します。ちょうど良い複雑さを見つけることが重要です。
そこで、交差検証という方法が役に立ちます。交差検証では、学習データをいくつかのグループに分け、あるグループを検証用データとして残し、残りのグループを学習用データとしてモデルを作ります。これを全てのグループが検証用データになるように繰り返すことで、様々なモデルの汎化性能を評価できます。そして、最も高い汎化性能を示したモデルを選びます。これは、色々な服を試着してみて、一番自分に似合う服を選ぶようなものです。
さらに、モデルの汎化性能を高めるには、データの前処理や特徴量作りも大切です。データの前処理とは、データを整理したり、整えたりすることで、モデルが学習しやすくする作業です。特徴量作りとは、モデルにとって重要な特徴をデータから抽出する作業です。これらは、料理で言えば、食材を洗ったり切ったり、下味をつけたりするような下準備に当たります。
交差検証とこれらの手法を組み合わせることで、より美味しい料理、つまり高性能なモデルを作ることができるのです。