
隠れマルコフモデル:音声認識の立役者

AIを知りたい
『隠れマルコフモデル』って、音声認識で使われるんですよね?どんなものかよくわからないんですが…

AIエンジニア
そうだね。音声認識でよく使われるよ。簡単に言うと、目に見えない状態の変化を確率で推測するモデルなんだ。例えば、今日の天気を『晴れ』『曇り』『雨』の3つの状態だとすると、明日の天気は今日の天気によって変化する確率が違うよね?それを利用するんだよ。
AIを知りたい
なるほど。でも、『隠れ』ってどういう意味ですか?
AIエンジニア
いい質問だね。『隠れ』とは、実際にどんな状態の変化が起こっているかは直接観測できないという意味なんだ。例えば、音声認識では、マイクで拾った音声がどの音に対応するかは直接わからない。そこで、隠れマルコフモデルを使って、音響的な特徴から、隠れた状態、つまり『あ』『い』『う』といった音や単語を推測するんだよ。
隠れマルコフモデルとは。
音声認識に使われる技術の一つに「隠れマルコフモデル」というものがあります。これは、音の最小単位ごとに学習することで、たくさんの言葉を認識できるようにした仕組みです。この仕組みは、図を見ると分かるように、一方向に進む形をしています。また、「隠れ」という言葉が使われているのは、どの状態からどの音の特徴が出ているのかが直接には分からない、という意味です。
音声認識における役割

人間が話す言葉を機械が理解できるようにする技術、音声認識。この技術を支える重要な仕組みの一つとして隠れマルコフモデル、略して隠れマルコフ模型というものがあります。この隠れマルコフ模型は、音声を認識する上で、なくてはならない役割を担っています。
隠れマルコフ模型は、音声を音素と呼ばれる基本的な音の単位に分解します。日本語で言えば、「あいうえお」のような母音や、「かきくけこ」といった子音の組み合わせです。これらの音素は、実際には様々な要因で変化し、同じ音素でも発音に違いが生じることがあります。しかし、隠れマルコフ模型は、音素の並び方や出現する確率を統計的にモデル化することで、これらの変化に対応し、音声を認識します。
例えば、「こんにちは」という言葉を発音する場合を考えてみましょう。この言葉は、「こ」「ん」「に」「ち」「は」という五つの音素に分解できます。隠れマルコフ模型は、これらの音素がどのような順序で、どのくらいの確率で出現するかを学習しています。そのため、「こんいちは」や「こんにちわ」といったように、発音が多少ずれていても、「こんにちは」と認識することができます。
隠れマルコフ模型の優れた点は、その高い精度と柔軟性にあります。様々な言語や、人それぞれ異なる発音にも対応できるため、多くの音声認識システムで利用されています。音声検索や音声入力、音声翻訳など、私たちの生活で利用される様々な場面で、隠れマルコフ模型は、陰ながら活躍しているのです。さらに、雑音が多い環境でも、比較的高い精度で音声を認識できることから、実用性の高い技術として、幅広い分野で活用が期待されています。
| 項目 | 説明 |
|---|---|
| 技術名 | 音声認識 |
| 音声認識の仕組み | 隠れマルコフモデル(隠れマルコフ模型) |
| 隠れマルコフモデルの役割 | 音声を音素に分解し、音素の並び方や出現確率を統計的にモデル化することで音声を認識 |
| 音素の例 | 日本語の母音(あいうえお)、子音(かきくけこ)の組み合わせ |
| 認識の例 | 「こんにちは」を「こ」「ん」「に」「ち」「は」の音素に分解し、音素の出現順序と確率から認識 |
| 隠れマルコフモデルの利点 | 高い精度と柔軟性、様々な言語や発音に対応可能 |
| 活用例 | 音声検索、音声入力、音声翻訳 |
| 今後の展望 | 雑音が多い環境での音声認識、幅広い分野での活用 |
モデルの構造

隠れマルコフモデルとは、直接目には見えない状態の遷移と、そこから生まれる目に見える記号の列によって構成される確率モデルです。例として、音声認識を考えてみましょう。人が話す言葉は、音のつながりでできています。この音の最小単位である音素(「あ」や「い」など)が、隠れマルコフモデルにおける「隠れた状態」に当たります。私たちが耳にするのは、音素そのものではなく、音素が組み合わさってできた音声です。この音声をコンピュータで扱うために、音声信号の特徴を数値化したものを「記号」として捉えます。つまり、隠れマルコフモデルは、目に見えない音素の列から、目に見える音声信号の特徴がどのように生成されるかを確率的に表現するモデルです。
隠れマルコフモデルでは、状態の遷移がマルコフ過程と呼ばれる性質に従うと仮定します。マルコフ過程とは、現在の状態が直前の状態だけに依存し、それ以前の状態には影響を受けないという性質のことです。例えば、「あ」という音素の次にどの音素が現れるかは、直前の「あ」という音素だけに影響され、それ以前の音素には関係ないということです。さらに、各状態からは特定の記号が一定の確率で出力されると考えます。例えば、「あ」という音素からは、「あ」の音波の特徴を表す記号が、高い確率で出力されるでしょう。
隠れマルコフモデルの状態遷移は、左から右への構造で表現されます。これは、時間の流れに沿って状態が遷移していくことを表しています。例えば、「おはよう」という言葉は、「お」→「は」→「よ」→「う」の順に音素が遷移していきます。この様子を左から右へ進む矢印で表すのが、隠れマルコフモデルのleft-to-right型の構造です。この構造により、時間の流れを考慮した音声認識などが可能になります。
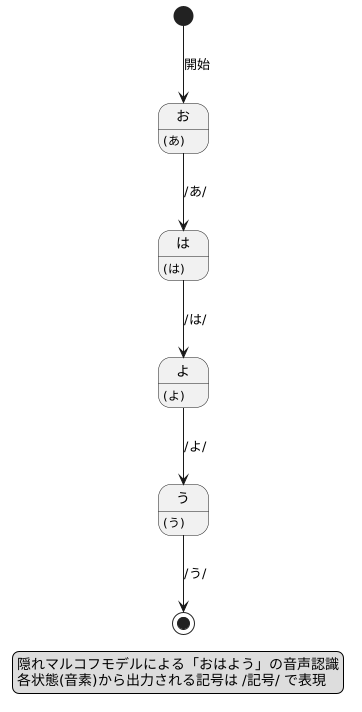
音素と語彙

音声を認識するには、まず音声を分解する必要があります。その分解された最小単位が音素です。音素とは、言葉を構成する音の最小単位であり、日本語では、母音の「あいうえお」や子音の「かきくけこ」、撥音の「ん」などが該当します。まるで積み木のように、これらの音素を組み合わせることで、様々な単語を作り出すことができます。
音素を認識する技術の一つに、隠れマルコフモデル(HMM)があります。HMMは、それぞれの音素が持つ音響的な特徴を学習します。例えば、「あ」という音素は、特定の周波数帯域の音が強く出るといった特徴があります。HMMは、このような音響的な特徴のパターンを大量の音声データから学習することで、音声を音素の列へと変換します。
HMMの大きな利点は、音素単位で学習を行うため、語彙の追加や変更に柔軟に対応できることです。例えば、「こんにちは」という言葉を認識させたい場合、「こ」「ん」「に」「ち」「は」という五つの音素を学習させれば認識が可能になります。もし新しい単語を認識させたい場合でも、その単語を構成する音素が既に学習済みであれば、新たに単語全体を学習させる必要はありません。そのため、新しい言葉を追加する際にも、少ない労力で対応できます。
さらに、音素を組み合わせて単語を認識するHMMは、未知の単語に対してもある程度の認識能力を発揮します。学習していない単語であっても、既知の音素の組み合わせで構成されている場合は、ある程度の音声認識が可能になります。これは、従来の音声認識技術に比べて大きな進歩であり、音声認識システムの実用性を飛躍的に向上させる要因となっています。このように、音素に基づいた学習を行うHMMは、音声認識技術において重要な役割を担っていると言えます。
| 項目 | 説明 |
|---|---|
| 音素 | 言葉を構成する音の最小単位(例:あいうえお、かきくけこ、ん) |
| 隠れマルコフモデル(HMM) | 音素の音響的な特徴を学習し、音声を音素列に変換する技術 |
| HMMの利点1 | 音素単位で学習するため、語彙の追加や変更に柔軟に対応可能 |
| HMMの利点2 | 未知の単語でも、既知の音素の組み合わせであればある程度の認識が可能 |
隠れ状態の意味

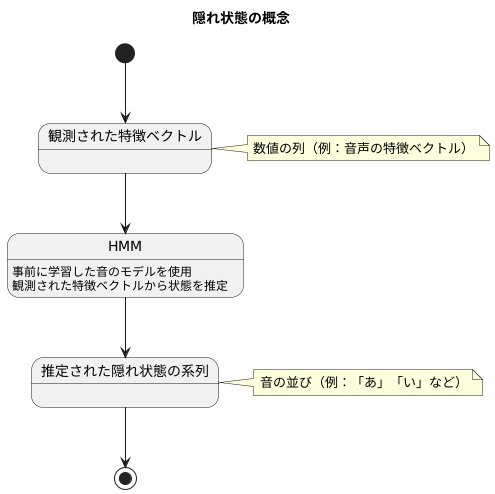
「隠れ状態」とは、直接目には見えない内部の状態を表す言葉です。例として、音声認識を考えてみましょう。人が話す言葉を機械に認識させるためには、まず音声を分析し、特徴を捉えた数値の列に変換する必要があります。この数値の列を「特徴ベクトル」と呼びます。しかし、この特徴ベクトルを見ただけでは、どの音に対応しているのかはすぐには分かりません。例えば、「あ」という音と「い」という音は、似たような特徴ベクトルを持つ場合があります。
ここで「隠れ状態」の考え方が重要になります。音声認識では、音声を「あ」や「い」といった音の並びとして理解するために、隠れマルコフモデル(HMM)という統計モデルがよく使われます。HMMは、目に見える特徴ベクトルの背後に、目に見えない「状態」の系列があると仮定します。この状態は、例えば「あ」の状態、「い」の状態といった音に対応する状態です。HMMは、事前に学習した音のモデルと、観測された特徴ベクトルの系列から、最も可能性の高い状態の系列を推定します。つまり、特徴ベクトルという手がかりをもとに、隠れた状態を推理するのです。
「隠れ」という言葉が使われているのは、どの状態からどの特徴ベクトルが生成されたのかが直接的には分からないからです。HMMは、観測された特徴ベクトルから、隠れた状態を確率的に推定することで、音声認識を実現しています。これは、宝探しゲームで、宝のありかを示すヒントを手がかりに、宝の場所を推測するようなものです。ヒントは宝の場所を直接的には示していませんが、推測の手がかりとなります。隠れ状態も同様に、直接目には見えませんが、観測された特徴ベクトルを通して推測することができます。
今後の展望

これまで、隠れマルコフモデル(以下、隠れた繋がり模型とする)は、音声の聞き取りの分野で目覚ましい成果を上げてきました。隠れた繋がり模型を使うことで、人の声を文字に変換する作業が格段に正確になりました。しかし、その一方で、いくつかの解決すべき課題も残されています。
例えば、周囲の騒音や、話す人によって声色が変わることに対する対応力の強化は、重要な課題の一つです。騒がしい場所でも、あるいは話す人が変わっても、正確に音声を聞き取れるようにすることが求められます。また、より自然で滑らかな音声の合成も実現する必要があります。機械が作り出す音声はまだぎこちなく、人間の声と聞き比べると不自然さが残ります。より人間に近い、自然で聞き取りやすい音声を作り出すことが、今後の課題と言えるでしょう。
これらの課題を解決するために、様々な研究開発が行われています。隠れた繋がり模型の仕組みを拡張したり、深層学習といった新しい技術と組み合わせたりすることで、隠れた繋がり模型の性能をさらに高める試みが続けられています。深層学習は、人間の脳の仕組みを模倣した技術で、大量のデータから複雑なパターンを学習することができます。この技術を隠れた繋がり模型と組み合わせることで、より高度な音声認識が実現すると期待されています。
今後の研究開発によって隠れた繋がり模型はさらに進化し、より高度な音声の聞き取り技術の実現に貢献していくと考えられます。そして、音声の聞き取り技術の進化は、人間と機械の意思疎通をより円滑にし、私たちの生活をより便利で豊かなものにしてくれるでしょう。音声で機械を操作したり、情報を簡単に得たりすることが当たり前になる未来も、そう遠くないかもしれません。
| 項目 | 内容 |
|---|---|
| 成果 | 音声認識の精度向上 |
| 課題 | 騒音や声色の変化への対応力の不足、自然で滑らかな音声合成の困難さ |
| 解決策 | 隠れた繋がり模型の拡張、深層学習との組み合わせ |
| 展望 | より高度な音声認識、人間と機械の円滑な意思疎通、生活の利便性向上 |