未知データへの対応:汎化性能

AIを知りたい
『汎化性能』って、よく聞くけど、実際にどういう意味ですか?

AIエンジニア
そうだね。『汎化性能』とは、学習したことをもとに、初めて見るデータに対してもきちんと対応できる能力のことだよ。たとえば、犬の種類をたくさん写真で学習したAIが、初めて見る犬種の写真でも「これは犬だ」と判断できるかどうか、それが汎化性能だ。
AIを知りたい
なるほど。初めて見るデータにきちんと対応できる能力のことですね。じゃあ、この能力を高めることが大切なんですか?
AIエンジニア
その通り!AIを作る目的は、まさにこの汎化性能を高めることにあると言えるんだ。未知のデータにも対応できるAIを作ることで、初めて出会う状況にも対応できるAIを作ることができるんだよ。
汎化性能とは。
人工知能に関する言葉で「広く使える能力」というものがあります。これは、まだ見たことのないデータに対してもきちんと対応できる力のことで、この能力が高い人工知能を作ることが機械学習の大きな目標とも言えます。この広く使える能力を正しく評価するには、学習に使うデータとテストに使うデータをきちんと分けて、学習や実験をすることが大切です。
汎化性能とは

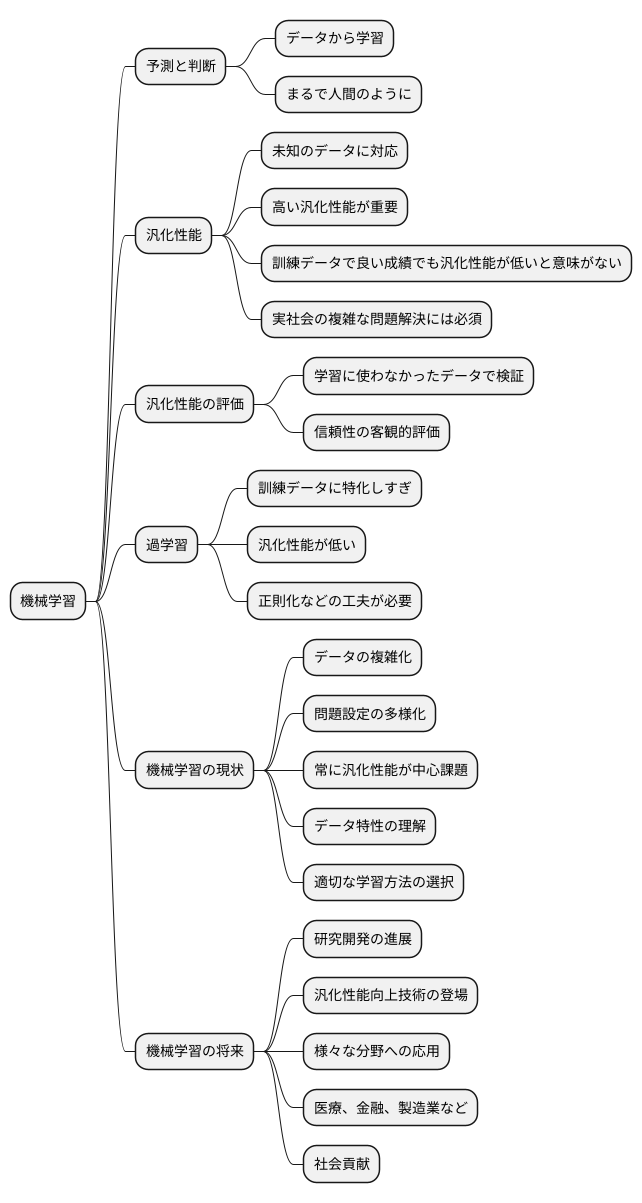
学習をさせた機械には、初めて見る情報にもうまく対応できる能力が求められます。この能力のことを汎化性能と呼びます。汎化性能とは、学習に使っていないデータに対して、機械がどれくらい正確に予測や分類ができるかを示す指標です。
たとえば、たくさんの猫の絵を使って機械に猫を覚えさせた後、初めて見る猫の絵を見せたときに、機械がそれをきちんと猫だと判断できるかどうかが重要になります。学習に使った猫の絵だけを完璧に覚えたとしても、それだけでは現実世界で役に立つ機械とは言えません。なぜなら、現実世界には学習に使ったものとは少し違う猫の絵もたくさん存在するからです。機械が、学習したことをもとに、初めて見る猫の絵にも対応できる、これが汎化性能の高さにつながります。
汎化性能の低い機械は、学習に使ったデータに過剰に適応してしまい、それ以外のデータには対応できなくなってしまいます。これは、まるで特定の猫の絵だけを暗記してしまい、他の猫の絵を猫だと認識できないようなものです。このような状態を過学習と呼びます。過学習が起きると、見たことのないデータに対しては、まるで役に立たない機械になってしまいます。
反対に、汎化性能の高い機械は、学習したデータから本質的な特徴を捉え、それを新しいデータにも応用することができます。たとえば、猫の耳の形や目の形、ひげの本数といった特徴を学習することで、様々な種類の猫を猫だと正しく判断できるようになります。
機械学習では、この汎化性能を高めることが非常に重要です。そのため、学習データの選び方や学習方法を工夫し、未知のデータにも対応できる、本当に役立つ機械を作ることが目指されています。
なぜ汎化性能が重要か

機械学習の目的は、世の中にある実際の問題を解くための模型を作ることです。しかし、現実の世界では常に新しい情報が生み出され、状況は変化し続けています。そのため、学習に使った情報だけにうまく対応できる模型では十分ではありません。まだ見ぬ情報に対しても正しく動く、つまり応用力の高い模型でなければ、実際には役に立ちにくいと言えるでしょう。
例えば、病気の診断を助ける仕組みを作るとします。学習に使った症例にしか対応できない仕組みでは、新しい症例や変化した病気には対応できず、誤った診断につながるかもしれません。本当に患者さんを助けるためには、未知の症例にもきちんと対応できる応用力の高い仕組みが必要です。
もう少し具体的に考えてみましょう。犬と猫を見分ける模型を作るとします。学習データにたくさんの犬と猫の画像を使い、それぞれの見分け方を模型に覚えさせます。しかし、学習データにチワワの画像が一枚もなかったとしましょう。この模型は、初めてチワワの画像を見せられたとき、正しく犬だと判断できるでしょうか?もし、この模型が犬の種類ごとの特徴を覚えるのではなく、学習データにある特定の犬と猫の特徴だけを暗記していたら、チワワを犬だと認識できないかもしれません。
このように、特定の情報にだけ対応するのではなく、様々な情報に対応できる能力が汎化性能です。そして、この汎化性能こそが、機械学習の模型を現実世界で役立つものにするために必要不可欠な要素なのです。様々な分野で機械学習の模型が活用されるようになっている中で、応用力の大切さはますます高まっていると言えるでしょう。
汎化性能の評価方法

機械学習モデルの真価は、未知データへの対応能力、すなわち汎化性能で決まります。この汎化性能を正しく測るには、学習に使うデータと、評価に使うデータをきちんと分けておくことが肝心です。具体的には、集めたデータを訓練データとテストデータの二つに分割します。訓練データは、いわば教科書のようなもので、モデルはこのデータを使って学習します。テストデータは、学習後のモデルの実力を試すための試験のようなものです。モデルはテストデータの内容を事前に知りません。
まずは、訓練データだけを使ってモデルを学習させます。この過程は、人間が教科書を読んで勉強するのと似ています。モデルは訓練データからパターンや規則性を学び取ります。学習が完了したら、いよいよテストです。学習済みモデルにテストデータを入力し、結果を予測させます。この予測結果と、実際の正解を比較することで、モデルがどれだけ未知データにうまく対応できるか、つまり汎化性能を評価できます。
もし、モデルが訓練データの内容を丸暗記するような学習をしてしまうと、テストデータでは良い結果が出ません。これは、教科書の例題だけを暗記して、応用問題が解けない生徒のような状態です。このような現象を過学習と呼びます。過学習が起きると、モデルは訓練データでは高い精度を示すものの、未知データへの対応能力が低いため、汎化性能が低下します。
適切な評価方法を用いることで、この過学習のような問題を早期に発見し、対策を講じることができます。例えば、訓練データの一部を検証データとして更に分割し、モデルの学習過程を監視する手法も有効です。検証データを用いて定期的にモデルの性能をチェックすることで、過学習の兆候を早期に捉え、学習を調整することができます。このように、適切な評価方法を踏まえることで、より汎化性能の高い、真に役立つ機械学習モデルを開発することが可能になります。
汎化性能を高めるための工夫

機械学習の目的は、未知のデータに対して正確な予測を行うことです。この能力は汎化性能と呼ばれ、モデルの良し悪しを測る重要な指標となります。この汎化性能を高めるためには、様々な工夫が必要です。
まず、過学習を防ぐことが重要です。過学習とは、訓練データに過度に適合しすぎてしまい、未知のデータに対する予測精度が低下する現象です。これを防ぐための有効な手段の一つが正則化です。正則化とは、モデルの複雑さを抑制する技術です。具体的には、モデルのパラメータの値が大きくなりすぎないように制限を加えます。これにより、訓練データの些細なノイズにまで過剰に反応することを防ぎ、より滑らかで汎化性能の高いモデルを学習させることができます。
次に、データ拡張も有効な手法です。限られた訓練データしか用意できない場合でも、人工的にデータのバリエーションを増やすことで、モデルがより多くのパターンを学習し、汎化性能を向上させることができます。例えば、画像認識のタスクでは、既存の画像を回転させたり、反転させたり、明るさを調整したりすることで、新たな画像データを生成できます。このように、データ拡張は実質的なデータ量を増やし、モデルの学習をより効果的に行うことを可能にします。
最後に、適切なモデル選択も重要です。モデルが複雑すぎると、過学習を起こしやすくなります。一方、モデルが単純すぎると、データの持つ複雑な関係性を十分に捉えられず、予測精度が低下します。扱うデータの性質や予測したい事柄の複雑さなどを考慮し、適切な複雑さのモデルを選択する必要があります。
これらの技術を適切に組み合わせることで、より高い汎化性能を持つ、つまり未知のデータに対しても高い予測精度を持つ機械学習モデルを構築することが可能になります。そして、より信頼性の高い予測結果を得ることができるようになります。

まとめ

機械学習は、まるで人間のようにデータから学習し、未来を予測したり判断したりする技術です。この技術の肝となるのが、未知のデータに対してもきちんと対応できる能力、すなわち汎化性能です。いくら訓練データで良い成績を収めても、新しいデータにうまく対応できなければ、実社会の複雑な問題を解決することはできません。ですから、高い汎化性能を持つモデルを作ることが、機械学習開発の最重要課題と言えるでしょう。
汎化性能を測るには、学習に使わなかったデータでモデルの精度を確かめることが重要です。この検証作業を正しく行うことで、モデルの信頼性を客観的に評価できます。また、過学習のように、訓練データに特化しすぎて汎化性能が低くなる現象にも注意が必要です。このような事態を防ぐには、正則化などの様々な工夫が不可欠です。
機械学習を取り巻く環境は日々変化しており、扱うデータも複雑さを増し、問題設定も多様化しています。このような状況下でも、汎化性能は常に機械学習開発の中心的な課題であり続けるでしょう。より良いモデルを作るためには、データの特性を理解し、適切な学習方法を選択する必要があります。
機械学習の研究開発は目覚ましいスピードで進んでいます。今後、汎化性能を向上させるためのより効果的な技術が次々と生まれてくるでしょう。そして、これらの技術は医療、金融、製造業など、様々な分野で機械学習の応用を促進し、私たちの社会をより豊かにしていくと考えられます。だからこそ、汎化性能という概念を深く理解し、その向上に努めることが、機械学習の発展、ひいては社会貢献に繋がるのです。