質の低い入力は質の低い結果を生む

AIを知りたい
先生、「ゴミを入れたらゴミが出てくる」って、人工知能の分野でよく聞くんですけど、どういう意味ですか?

AIエンジニア
いい質問だね。人工知能、特に機械学習では、学習させるデータの質が結果に大きく影響するんだよ。質の低いデータ、つまり「ゴミ」のようなデータを使って学習させると、出てくる結果も「ゴミ」になってしまう。これが「ゴミを入れたらゴミが出てくる」という意味だよ。
AIを知りたい
なるほど。つまり、良い結果を得るには、良いデータが必要ってことですね。
AIエンジニア
その通り!だから、人工知能を開発したり利用したりする際には、データの質に気を配ることがとても重要なんだ。
Garbage In, Garbage Outとは。
人工知能に関連することばで「ゴミを入れたら、ゴミが出てくる」という意味の『ガーベジ・イン、ガーベジ・アウト』というものがあります(機械学習の分野では「ガーベジ・イン、ガーベジ・アウト」を縮めて「ギゴ」と呼ぶこともあります)。これは、人工知能に質の低いデータを入力すれば、質の低い結果しか得られないということを示しています。
はじめに

機械学習は、多くの情報から学び、未来を予測したり、物事を判断したりする力を持った技術です。情報の質が良いほど、機械学習の精度は上がり、より正確な予測や判断ができます。しかし、質の低い情報を与えてしまうと、その結果は使い物にならないものになってしまいます。これは「ゴミを入力すれば、ゴミが出てくる」という格言の通りです。この格言は、情報科学の分野では「ゴミ入りゴミ出し」とも呼ばれています。
たとえ、素晴らしい道具や方法を用いても、材料となる情報が粗悪であれば、良い結果は得られません。料理で例えるなら、新鮮な材料を使わなければ、どんなに腕の良い料理人でも美味しい料理は作れません。同じように、機械学習でも、質の高い情報を入力として与えることが何よりも大切です。
質の低い情報とは、例えば、誤りや不正確な情報、偏った情報、古くなった情報などが挙げられます。このような情報を使って機械学習を行うと、現実とはかけ離れた結果が出てしまい、誤った判断につながる可能性があります。そのため、機械学習を行う際には、情報の質を常に意識し、正確で最新の情報を使うように心がける必要があります。情報の収集方法や整理方法、情報の信頼性を確認する方法などをしっかりと理解し、実践することが重要です。
情報の質を高めるためには、様々な工夫が必要です。例えば、情報を集める際には、複数の情報源から集め、情報を比較検討することで、情報の正確性を高めることができます。また、情報を整理する際には、情報の重複や矛盾を取り除き、情報を分かりやすく整理することが大切です。そして、情報の質を常に確認し、必要に応じて情報を更新していくことで、より精度の高い機械学習を実現できます。
データの質の重要性

機械学習の精度は、学習に用いるデータの質に大きく左右されます。これは、人間の学習プロセスに例えることができます。例えば、生徒が教師から学ぶ際に、教師が誤った知識を教えれば、生徒も当然誤った知識を習得してしまいます。これと同様に、機械学習モデルも質の低いデータで学習すると、誤った予測や判断を行うようになります。
具体的な例として、画像認識モデルの学習を考えてみましょう。もし、学習に用いる画像データに誤ったラベル(例えば、猫の画像に「犬」というラベルが付いている)が付与されていると、モデルは猫を犬として認識することを学習してしまいます。結果として、このモデルは猫の画像を見せられても「犬」と誤って判断するようになります。
また、学習データに偏りがある場合も問題となります。例えば、顔認識システムの学習データに特定の人種や性別のデータが偏って多く含まれている場合、そのシステムは特定の人種や性別に対して高い認識精度を示す一方で、それ以外の人種や性別に対しては認識精度が低くなる可能性があります。これは、システムが学習データの偏りを反映した結果を出力するためです。
このようなデータの偏りは、社会的な不平等につながる可能性があります。例えば、採用選考に偏りのある顔認識システムが用いられると、特定の人々が不当に不利な立場に置かれる可能性があります。
高精度で公平な機械学習システムを実現するためには、質の高いデータを用いることが不可欠です。質の高いデータとは、正確なラベルが付けられており、かつ特定の属性に偏りのない、バランスの取れたデータのことです。このようなデータを用意することで、機械学習モデルは正確で公平な予測や判断を行うことができるようになります。
| 問題点 | 具体例 | 結果 | 対策 |
|---|---|---|---|
| 学習データの質が低い | 画像認識モデルで、猫の画像に「犬」というラベルが付いている | モデルが猫を犬と誤認識する | 質の高いデータを用いる(正確なラベル、特定の属性に偏りのないデータ) |
| 学習データに偏りがある | 顔認識システムの学習データに特定の人種や性別のデータが偏って多く含まれている | 特定の人種や性別以外への認識精度が低くなる。社会的な不平等につながる可能性もある。 |
質の高いデータとは

質の高いデータとは、目的に適い、間違いがなく、欠けがなく、矛盾がなく、新しい情報を含んでいるデータです。このようなデータは、様々な分析や意思決定を支える上で欠かせません。
まず、データが分析の目的に合っていることが重要です。例えば、商品の売れ行きを予測したいのに、生産量の情報しか集めていないと、正確な予測はできません。売れ行きを予測するためには、過去の販売データや顧客の購買動向、競合商品の情報など、目的に合ったデータを集める必要があります。
次に、データは正確である必要があります。入力ミスや測定誤差などでデータに誤りが含まれていると、分析結果の信頼性が損なわれます。データの正確性を確保するためには、入力時の確認やデータクリーニングといった作業が不可欠です。
また、データに欠けている部分がないことも重要です。必要な情報が欠けていると、全体像を把握することができず、誤った結論を導き出す可能性があります。例えば、顧客満足度調査で一部の回答が欠けていると、全体の満足度を正しく評価できません。欠けているデータを補完したり、分析対象から除外したりするなどの対応が必要です。
さらに、データ同士に矛盾がないようにする必要があります。異なる時期や異なる部署から集めたデータに矛盾があると、分析結果が混乱します。例えば、同じ顧客の住所が複数のデータで異なっている場合、顧客一人ひとりの購買履歴を正しく追跡できません。データの矛盾を解消するためには、データの入力規則を統一したり、データ同士を照合したりする作業が必要です。
最後に、データは新しいものであるほど有用です。社会情勢や経済状況は常に変化しているため、古いデータは現在の状況を反映していない可能性があります。例えば、数年前の市場調査データは現在の市場動向を予測する上で役に立たないかもしれません。常に最新のデータを取得し、分析に利用することが重要です。
| 質の高いデータの特性 | 説明 | 例 | 対策 |
|---|---|---|---|
| 目的に適っている | 分析の目的に合ったデータであること | 商品の売れ行き予測に生産量の情報は不適切 | 過去の販売データ、顧客の購買動向、競合商品の情報などを収集 |
| 間違いがない | 入力ミスや測定誤差などがないこと | 入力ミス、測定誤差 | 入力時の確認、データクリーニング |
| 欠けがない | 必要な情報が欠けていないこと | 顧客満足度調査で一部の回答が欠けている | 欠けているデータを補完、分析対象から除外 |
| 矛盾がない | データ同士に矛盾がないこと | 同じ顧客の住所が複数のデータで異なる | データの入力規則を統一、データ同士を照合 |
| 新しい情報を含んでいる | データが最新であること | 数年前の市場調査データ | 常に最新のデータを取得し、分析に利用 |
データの前処理

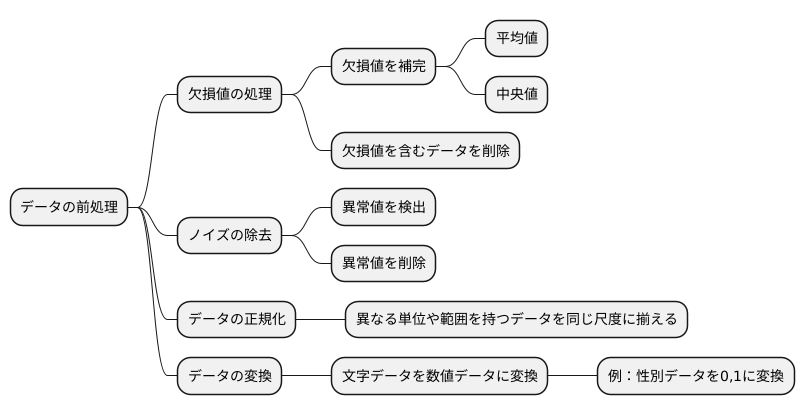
機械学習の精度は、学習に用いるデータの質に大きく左右されます。そのため、質の高いデータを得るためには、データの前処理が非常に重要になります。データの前処理とは、集めたままのデータを機械学習モデルが学習しやすい形に整える一連の作業です。 この作業を丁寧に行うことで、モデルの精度向上に繋がります。
データの前処理には、大きく分けていくつかの種類があります。まず、欠損値の処理です。欠損値とは、データに値が入っていない箇所のことです。欠損値が多いと、モデルが正しく学習できません。そこで、欠損値を何らかの値で補完したり、欠損値を含むデータ自体を削除したりする処理が必要です。例えば、平均値や中央値で欠損値を補完する方法がよく使われます。状況に応じて、最も適切な方法を選択することが大切です。
次に、ノイズの除去です。ノイズとは、データに含まれる誤りや異常値のことです。ノイズも、モデルの学習に悪影響を与えます。ノイズを除去するために、統計的な手法を用いて異常値を検出し、削除します。どのデータをノイズと判断するかは、データの特性や分析の目的に合わせて慎重に判断する必要があります。
さらに、データの正規化も重要な前処理です。異なる単位や範囲を持つデータを、同じ尺度に揃える処理です。例えば、ある特徴量は0から100の範囲、別の特徴量は0から1の範囲で変動する場合、そのままではモデルが正しく学習できません。正規化によって、これらの特徴量を同じ尺度に揃えることで、モデルの学習を安定させ、精度を向上させることができます。
最後に、データの変換です。これは、データの形式を変更する処理です。例えば、文字で表現されたカテゴリデータを数値データに変換することで、機械学習モデルが理解しやすくなります。「男」「女」のような性別データを、0と1に変換するなどが一例です。
このように、データの前処理には様々な手法があります。それぞれのデータの特性や、使用する機械学習モデルに合わせて、適切な前処理を行うことで、データの質を向上させ、より精度の高いモデルを構築することが可能になります。
質の高いデータの収集

良いデータを集めることは、役に立つ成果を得るためにとても大切です。データを集めるやり方次第で、データの質が決まると言っても良いでしょう。集めたデータが、本当に役に立つものなのか、しっかりと使えるものなのかを見極めるためには、集め方から気を配らなければなりません。
まず、集めたデータが正しいかどうかを確認することが重要です。数字が間違っていたり、情報が古かったりすると、正しい結果が得られません。データを入力する際に、タイプミスなどの間違いを防ぐ仕組みを作ることは有効な手段の一つです。例えば、入力欄に決まった形式でしか入力できないようにしたり、入力された値が妥当かどうかを自動でチェックする機能を設けることで、間違いを減らすことができます。
データが全部揃っているかどうかも確認が必要です。必要な情報が一部欠けていると、分析結果に偏りが出てしまう可能性があります。データを集める前に、どんな情報が必要なのかを明確にして、漏れがないように集める必要があります。また、集めたデータが矛盾なく繋がっているかどうかも大切です。異なる場所から集めたデータ同士が食い違っていると、どれが正しい情報なのか分からなくなってしまいます。データを集める際には、それぞれのデータの出どころを確認し、必要に応じて修正することで、データの信頼性を高めることができます。
最後に、個人情報などの大切な情報を扱う場合は、細心の注意が必要です。情報が漏れたり、悪用されたりすることがないよう、安全な方法で保管し、取り扱う必要があります。関係者以外が情報にアクセスできないように、パスワードを設定したり、アクセス権限を適切に管理したりするなど、セキュリティ対策をしっかりと行うことが重要です。
| 項目 | 説明 | 対策 |
|---|---|---|
| データの正確性 | 数字の間違いや古い情報が含まれていないか | 入力時のチェック機能、妥当性検証 |
| データの完全性 | 必要な情報が全て揃っているか、矛盾がないか | 必要な情報の事前定義、データの出どころ確認、修正 |
| データの安全性 | 個人情報など、大切な情報の保護 | 安全な保管方法、アクセス制限、セキュリティ対策 |
まとめ

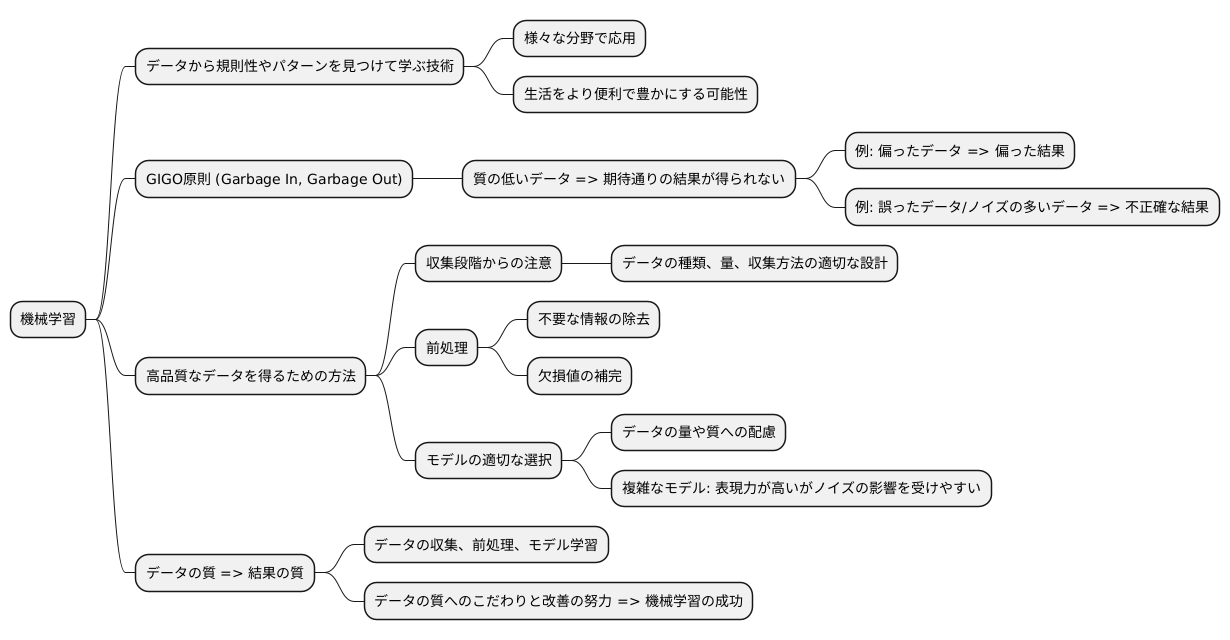
機械学習は、まるで人間の学習のように、データから規則性やパターンを見つけて学ぶ技術です。この技術は、様々な分野で応用され、私たちの生活をより便利で豊かにする可能性を秘めています。しかし、機械学習の成功は、学習に用いるデータの質に大きく左右されるという重要な点があります。これを「ゴミを入れたらゴミが出てくる」という意味の「GIGO(Garbage In, Garbage Out)原則」と呼びます。
どんなに優れた学習方法や高性能な計算機を用いても、質の低いデータを使って学習させれば、期待通りの結果は得られません。例えば、偏ったデータで学習させた場合、その偏りを反映した結果しか得ることができず、現実世界の問題を正しく解決することはできません。また、誤ったデータやノイズの多いデータで学習させれば、学習結果自体が不正確なものになってしまいます。まるで、間違った知識を教え込まれた生徒が、誤った解答を導き出してしまうようなものです。
高品質なデータを得るためには、データの収集段階から注意深く行う必要があります。収集するデータの種類や量、収集方法などを適切に設計することで、目的に合った質の高いデータを確保できます。さらに、収集したデータは、そのまま使えるとは限りません。不要な情報を取り除いたり、欠損値を補完したりするなど、前処理と呼ばれる作業を通して、データの質を高めることが重要です。そして、学習に用いるモデルも、データの特性に合わせて適切に選択する必要があります。複雑なモデルは表現力が高い反面、ノイズの影響を受けやすいという欠点もあります。データの量や質に応じて、適切なモデルを選択することが重要です。
このように、機械学習においては、データの質が結果の質を決定づけるといっても過言ではありません。データの収集から前処理、モデルの学習に至るまで、データの質にこだわり、常に改善していく努力が、機械学習の成功の鍵となります。高品質なデータを適切に活用することで、機械学習は真価を発揮し、様々な分野で革新的な成果をもたらすことができるでしょう。