
ファインチューニングで精度向上

AIを知りたい
先生、この『ファインチューニング』って、どういう意味ですか?なんだか楽器の調律みたいですが…

AIエンジニア
そうだね、楽器の調律と似ているところがあるよ。AIの学習では、まず大量のデータで学習させて、大まかな『型』を作るんだ。これを『事前学習』と呼ぶ。その後に、特定の目的に合わせて、より細かい調整を行うのが『ファインチューニング』だよ。
AIを知りたい
つまり、最初にざっくり学習させて、その後で細かい調整をするってことですね。でも、なぜ最初から細かい調整をしないのですか?
AIエンジニア
最初から細かい調整をしようとすると、大量のデータと時間がかかるんだ。事前学習である程度『型』を作ってから細かい調整をする方が、効率よく学習できるんだよ。楽器の調律も、最初に全体を合わせてから、細かい音を調整するよね。それと似ているんだよ。
ファインチューニングとは。
人工知能の分野でよく使われる「ファインチューニング」という言葉について説明します。これは機械学習の一つで、すでに学習済みのモデルを、新しいデータや目的に合わせてさらに調整することを指します。この調整を行う際、学習の進み具合を左右する「学習率」という数値を小さく設定するのが一般的です。これは、すでに最適化されているモデルのパラメータに大きな変更を加えないようにするためです。小さな変更を積み重ねることで、モデルの性能をより細かく調整していくイメージです。
はじめに

近ごろ、人工知能の研究開発が盛んになり、暮らしの様々な場面で活用されるようになってきました。この進歩を支える技術の一つに機械学習があり、膨大な量の情報を処理し、そこから規則性やパターンを学ぶことで、様々な問題を解決することができます。
機械学習の中でも、特に注目されているのがファインチューニングと呼ばれる技術です。これは、既に学習を終えたモデルを新たな課題に適用させる手法です。まるで職人が刃物を研ぎ澄ますように、既存の知識を土台に、より特定の目的に特化した性能を引き出すことができます。
例えば、画像認識の分野で、猫を認識するよう訓練されたモデルがあるとします。このモデルを、今度は犬の種類を判別する新たな課題に活用したい場合、一からモデルを作り直すのは大変な手間がかかります。ファインチューニングを用いれば、既に猫の認識で学習した知識を活かし、犬の種類を判別する能力を効率的に学習させることができます。
ファインチューニングの利点は、学習にかかる時間と労力を大幅に削減できることです。ゼロから学習する場合に比べて、必要なデータ量も少なく、高い精度を達成しやすいという利点もあります。また、少ないデータでも効果を発揮するため、データ収集が難しい場合にも有効な手段となります。このように、ファインチューニングは、人工知能の発展を加速させる重要な技術として、様々な分野で応用が期待されています。
| 技術 | 説明 | 利点 | 例 |
|---|---|---|---|
| 機械学習 | 膨大な量の情報を処理し、そこから規則性やパターンを学ぶことで、様々な問題を解決する技術。 | 様々な問題解決に役立つ | – |
| ファインチューニング | 既に学習を終えたモデルを新たな課題に適用させる手法。既存の知識を土台に、より特定の目的に特化した性能を引き出す。 | 学習時間と労力の大幅削減、必要なデータ量が少ない、高い精度を達成しやすい、データ収集が難しい場合にも有効 | 猫を認識するよう訓練されたモデルを、犬の種類を判別する課題に適用。 |
ファインチューニングとは

既に学習を済ませた人工知能モデルを、特定の用途に合わせてさらに改良する技術のことを、ファインチューニングと言います。これは、まるで熟練の職人が作った刃物を、自分の手に馴染むように研ぎ直すような作業です。ゼロから刃物を作るよりも、ずっと早く、かつ高い性能を持つ刃物を手に入れられるのと同じように、ファインチューニングも、人工知能の性能向上に大きく貢献します。
たとえば、膨大な数の写真を見て、何が写っているかを理解する能力を持つ人工知能があるとします。この人工知能は、既に様々な物体を識別できるように学習されていますが、特定の物体をより正確に見分けるためには、追加の学習が必要です。例えば、この人工知能に、数百枚の犬の写真を学習させることで、犬種を判別する専門家へと育て上げることができます。これがファインチューニングです。
ファインチューニングの利点は、学習にかかる時間とデータ量の両方を節約できることです。ゼロから人工知能を作る場合、膨大な量のデータと長い学習時間が必要になります。しかし、既に学習済みのモデルを土台とするファインチューニングでは、比較的少量のデータと短い学習時間で、目的の性能を達成できます。これは、既に基礎知識を持っている人に、専門知識を教える方が、何も知らない人に一から教えるよりも簡単であることと同じ理屈です。
ファインチューニングは、画像認識だけでなく、文章の理解や音声認識など、様々な分野で活用されています。例えば、大量の文章データで学習した人工知能を、特定の分野の文章を要約する専門家へと育成したり、様々な人の声を認識できる人工知能に、特定の話者の声をより正確に聞き取る能力を付加したりすることができます。このように、ファインチューニングは、人工知能を様々な用途に適応させるための強力な手法として、広く利用されています。
| ファインチューニングとは | 例 | 利点 | 応用分野 |
|---|---|---|---|
| 学習済みのAIモデルを特定用途に改良する技術 | 汎用画像認識AI → 犬種判別AI | 学習時間とデータ量の節約 | 画像認識、文章理解、音声認識など |
| 熟練の職人が作った刃物を自分の手に馴染むように研ぎ直すような作業 | 数百枚の犬の写真を追加学習 | ゼロからAIを作るより効率的 | 特定分野の文章要約、特定話者の音声認識など |
学習済みモデルの活用

近年、人工知能の分野では、学習済みモデルを活用した技術が注目を集めています。学習済みモデルとは、大量のデータを使って既に学習を終えた人工知能モデルのことを指します。これらのモデルは、画像認識や文章理解といった特定の作業について、高度な能力を身につけています。
学習済みモデルを活用する大きな利点は、開発の手間と時間を大幅に削減できることです。一から人工知能モデルを開発するには、膨大な量のデータ収集と学習が必要となります。しかし、学習済みモデルを利用すれば、既に学習済みの知識を土台として、新たな作業に特化した調整を行うだけで済みます。この調整のことを、ファインチューニングと呼びます。ファインチューニングでは、比較的少量のデータで、モデルを特定の目的に合わせてカスタマイズできます。
学習済みモデルは、様々な種類が公開されており、目的に合ったモデルを選択することが重要です。例えば、画像認識に特化したモデルや、日本語の文章理解に優れたモデルなど、多様な選択肢があります。公開されているモデルを利用することで、開発コストを抑えつつ、高性能な人工知能システムを構築することが可能になります。
ファインチューニングの手順は、まず、公開されている学習済みモデルを選びます。そして、そのモデルを、利用したい作業に合わせた少量のデータで再学習させます。再学習の過程では、モデルが持つ既存の知識を維持しつつ、新たなデータの特徴を学習させます。これにより、モデルは特定の作業に特化した性能を発揮できるようになります。例えば、犬の種類を識別する人工知能を開発する場合、既に画像認識を学習済みのモデルを選び、様々な犬種の画像データでファインチューニングを行います。
学習済みモデルの登場により、人工知能開発の敷居は大きく下がりました。誰でも手軽に高度な人工知能技術を活用できるようになったことで、様々な分野での応用が期待されています。今後も、より高性能な学習済みモデルが開発され、私たちの生活をより豊かにしてくれることでしょう。
学習率の調整

学習の速さを決める大切な値に、学習率というものがあります。これは、機械学習モデルが新たな情報を学ぶ際に、どの程度大きく変化するかを決めるものです。ちょうど、人が新しい技術を習得する際に、一度に大きく変えるか、少しずつ変えるかを決めるようなものです。
特に、既に学習済みのモデルを特定の目的に合わせて微調整する「ファインチューニング」を行う際には、この学習率の調整が非常に重要になります。学習済みのモデルは、既に多くの知識を蓄えています。この知識を活かしつつ、新たな目的に合わせて調整するためには、急激な変化を避ける必要があります。そのため、ファインチューニングでは一般的に小さな学習率が用いられます。
もし学習率が大きすぎると、既に学習した大切な知識を忘れてしまい、うまく調整できないことがあります。これは「過学習」と呼ばれる現象につながり、新しいデータにうまく対応できなくなってしまいます。逆に、学習率が小さすぎると、学習の速度が遅くなり、なかなか目的の性能に達しないことがあります。ちょうど、人が新しい技術を学ぶ際に、変化が大きすぎると混乱し、小さすぎると上達しないのと同じです。
最適な学習率は、扱うデータやモデルによって異なります。そのため、色々な値を試してみて、最も良い結果が得られる学習率を見つけることが重要です。この試行錯誤は、高精度なモデルを作るために欠かせない作業です。地道な作業ではありますが、適切な学習率を見つけることで、モデルの性能を最大限に引き出すことができます。色々な学習率を試して、モデルの反応を見ながら、最適な値を見つけるようにしましょう。
| 学習率 | 説明 | 結果 |
|---|---|---|
| 大きい | 一度に大きく変化、急激な学習 | 過学習:既存知識喪失、新規データ対応不可 |
| 小さい | 少しずつ変化、緩やかな学習 | 学習速度低下、目標性能到達遅延 |
| 最適 | データ・モデルに最適化された学習率 | モデル性能最大化 |
具体的な手順

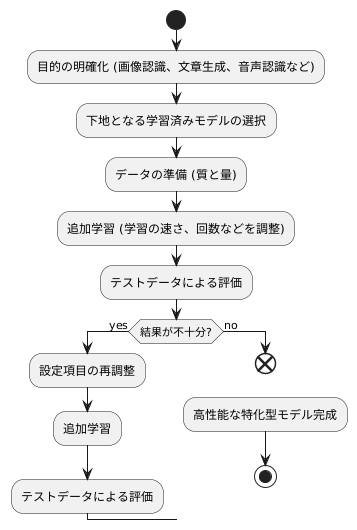
機械学習モデルを特定の用途に合わせるための調整作業は、いくつかの工程を経て行われます。まず初めに、どのような目的でモデルを使うのかを明確にする必要があります。例えば、画像認識なのか、文章生成なのか、音声認識なのかによって、適した下地となる学習済みモデルの種類が違ってきます。目的が定まったら、その目的に合った下地となる学習済みモデルを選びます。数多くの種類があるので、それぞれの特徴を理解し、どれが最適かを見極めることが大切です。
次に、新たに集めたデータを使って、選んだモデルに追加学習をさせます。この学習データは、モデルの性能を大きく左右するため、データの質と量が重要です。質の高いデータとは、偏りなく、目的とするタスクに関連性の高いデータのことです。量については、多ければ多いほど良いですが、学習にかかる時間も考慮する必要があります。追加学習を行う際には、学習の速さや回数などを調整する様々な設定項目があります。これらの設定項目を調整することで、モデルの性能を最大限に引き出すことができます。適切な設定を見つけるためには、試行錯誤が必要となる場合もあります。
最後に、テスト用のデータを使って、モデルがどの程度正確に動作するのかを評価します。この評価結果を見て、設定項目を再度調整する必要があるかどうかを判断します。もし結果が不十分であれば、前の工程に戻り、設定項目を調整して、追加学習と評価を繰り返します。こうして、納得のいく性能が得られるまで、根気強く調整を続けます。これらの工程を丁寧に行うことで、高性能な特化型モデルを作り上げることができます。
利点と応用

既に学習済みの模型を少しだけ調整する手法、すなわち微調整は、人工知能の様々な分野で応用され、技術の進歩を支える重要な役割を担っています。その利点としてまず挙げられるのは、学習時間の大きな短縮です。全く新しい模型を作るのに比べて、既に基礎が備わっている模型を調整する方が、はるかに短い時間で済みます。これは、開発期間の短縮、ひいては費用削減にも繋がります。
二つ目の利点として、必要な学習データの量が少なくて済むことが挙げられます。一般的に、人工知能の模型を作るには膨大なデータが必要ですが、微調整では、既に大量のデータで学習済みの模型を使うため、追加で必要なデータは少量で済みます。データ収集にかかる時間と労力を大幅に削減できるため、手軽に高性能な模型を作ることができます。
そして三つ目の利点として、高い精度を実現できることが挙げられます。微調整を用いることで、特定の課題に特化した高精度な模型を効率的に作り出すことができます。例えば、画像認識の分野では、一般的な画像認識の模型を微調整することで、特定の種類の物体を高い精度で認識する模型を構築できます。
これらの利点から、微調整は様々な分野で活用されています。医療の分野では、レントゲン写真やCT画像から病気を診断する際に、微調整を用いることで、少量のデータでも高精度な診断模型を構築できます。また、ものづくりの分野では、製品の欠陥を見つける検査や品質を管理する場面で、微調整が活用されています。その他、言葉を扱う人工知能や音声を扱う人工知能など、様々な分野で微調整技術が応用され、成果を上げています。
| 利点 | 説明 | 適用例 |
|---|---|---|
| 学習時間の短縮 | 既に基礎が備わっている模型を調整する方が、全く新しい模型を作るのに比べてはるかに短い時間で済む。開発期間の短縮、ひいては費用削減にも繋がる。 | – |
| 必要な学習データ量の削減 | 既に大量のデータで学習済みの模型を使うため、追加で必要なデータは少量で済む。データ収集にかかる時間と労力を大幅に削減できる。 | – |
| 高い精度の実現 | 特定の課題に特化した高精度な模型を効率的に作り出すことができる。 | 画像認識:特定の種類の物体を高い精度で認識する。 |
| 活用例 | ||
| 医療 | レントゲン写真やCT画像から病気を診断する際に、少量のデータでも高精度な診断模型を構築できる。 | – |
| ものづくり | 製品の欠陥を見つける検査や品質を管理する。 | – |
| その他 | 言葉を扱う人工知能や音声を扱う人工知能など。 | – |