機械学習の鍵、特徴量設計とは?

AIを知りたい
先生、特徴量設計って難しそうですね。具体的にどういうことですか?

AIエンジニア
そうだね、少し難しいけど、簡単に言うと、コンピュータにわかるような数字で物の特徴を表すことだよ。例えば、りんごとみかんを区別するために、りんごとみかんの『色』『大きさ』『重さ』を数字で表すようなものだね。
AIを知りたい
なるほど。でも、りんごとみかんだったら簡単にできそうですが、画像とかだと難しそうですね。
AIエンジニア
その通り!画像だと、りんごとみかんのように分かりやすい特徴を人が見つけて数字にするのは大変なんだ。でも、最近のAI技術であるディープラーニングのおかげで、AIが自分で画像の特徴を見つけて数字にできるようになってきたんだよ。
特徴量設計とは。
人工知能に関係する言葉である「特徴量設計」について説明します。特徴量設計とは、データの特徴をコンピュータが分かる数字に変換することです。人工知能のこれまでの歴史では、人間が特徴量設計を行っていました。例えば、コンビニの売上データなどは簡単にできますが、画像データなどはとても難しい作業です。しかし、深層学習という技術が登場したことで、人工知能が学習データの特徴を自分で学習できるようになりました。
特徴量設計とは何か

計算機に学習させるためには、元の情報を計算機が理解できる形に変換する必要があります。この変換作業こそが特徴量設計と呼ばれるもので、機械学習の成否を大きく左右する重要な工程です。
具体的に言うと、特徴量設計とは、私たち人間が見て理解できる情報から、計算機が理解できる数値データを作り出す作業です。例えば、顧客の買い物記録を例に考えてみましょう。記録には、顧客の年齢や性別、購入した商品の種類や金額、購入日時などが含まれています。これらの情報は人間には理解できますが、計算機はそのままでは理解できません。そこで、これらの情報を計算機が扱える数値データに変換する必要があります。
顧客の年齢や購入金額は、そのまま数値として使えます。しかし、性別や商品の種類のように、数値ではない情報は工夫が必要です。例えば、性別は男性を0、女性を1といった数値で表すことができます。商品の種類は、商品のカテゴリごとに番号を割り振ることで数値化できます。このように、様々な方法を用いて情報を数値データに変換します。
変換された数値データが「特徴量」と呼ばれ、計算機はこの特徴量を使って学習を行います。つまり、特徴量の質が学習の成果、ひいては機械学習モデルの精度に直結するのです。良い特徴量を設計できれば、計算機は効率的に学習を進め、精度の高い予測を行うことができます。逆に、特徴量が不適切であれば、計算機はうまく学習できず、精度の低い結果しか得られません。
効果的な特徴量設計は、機械学習の成功に欠かせない要素と言えるでしょう。そのため、データの性質を深く理解し、適切な変換方法を選択することが重要です。様々な手法を試し、最適な特徴量を探し出す地道な作業が、高精度な機械学習モデルを実現するための鍵となります。
| 情報の種類 | 人間が理解できる形 | 計算機が理解できる形(特徴量) | 変換方法 |
|---|---|---|---|
| 顧客情報 | 年齢 | 数値(例:30) | そのまま使用 |
| 顧客情報 | 性別 | 数値(例:男性:0, 女性:1) | 数値への置き換え |
| 購買情報 | 商品の種類 | 数値(例:カテゴリごとに番号を割り当て) | カテゴリごとの数値化 |
| 購買情報 | 購入金額 | 数値(例:1000) | そのまま使用 |
| 購買情報 | 購入日時 | 数値(例:タイムスタンプ) | 数値表現への変換(例:エポック秒) |
従来の特徴量設計

従来の特徴量設計は、人の手によって行われてきました。それぞれの分野に精通した専門家が、蓄積された知識や経験を活かし、データの中から目的に合致する重要な特徴を選び出していました。そして、その特徴を数値に変換することで、機械学習モデルが理解できる形に整えていました。
例えば、コンビニエンスストアの売上予測を考えると、売上に影響を与える要素を様々な角度から検討します。商品の種類や価格設定はもちろんのこと、販売された日時や曜日、お店の立地や周辺の人口、天候なども重要な要素となるでしょう。専門家はこれらの要素を数値化し、例えば商品の値段をそのまま数値として使ったり、販売日時を曜日や時間帯といった区分に分けたり、立地を緯度経度で表したりすることで、売上予測モデルが学習できるデータを作成していました。
しかし、画像や音声、自然言語といった複雑なデータを取り扱う場合、人による特徴量の設計は非常に困難でした。例えば、画像に写っている物体を認識する場合、色や形、模様といった様々な視覚的特徴が複雑に絡み合っています。これらの特徴を人間が一つ一つ数値化していく作業は、膨大な時間と労力を必要としました。また、どのような特徴が重要なのかを判断すること自体が難しく、専門家であっても完璧な特徴量を設計することは容易ではありませんでした。音声や自然言語データについても同様で、音の高低や強弱、単語の意味や文脈といった複雑な情報を適切に数値化することは、大きな課題となっていました。このように、従来の特徴量設計は、機械学習の適用範囲を広げる上で大きな障壁となっていたのです。
| 特徴量設計 | 従来の方法 | 課題 |
|---|---|---|
| 手法 | 人手による設計 専門家の知識・経験に基づき、重要な特徴を選択・数値化 |
|
| 例:コンビニ売上予測 |
|
– |
| 例:画像認識 |
|
|
| 例:音声・自然言語 |
|
|
深層学習と特徴量設計

近年の情報処理技術の進歩において、深層学習という技術は大きな注目を集めています。この技術は、従来の機械学習とは異なり、データの特徴を人間が設計するのではなく、計算機が自ら学習するという画期的な仕組みを持っています。この仕組みにより、特徴の設計にかかる手間や専門知識の必要性が大幅に軽減され、様々な分野への応用が可能となりました。
従来の機械学習では、例えば画像認識を行う場合、画像の輪郭や模様といった特徴を人間が抽出し、数値データに変換する必要がありました。この作業は特徴設計と呼ばれ、認識精度を左右する重要な工程でした。しかし、専門知識が必要な上、多くの時間と労力を要するという課題がありました。深層学習では、大量の画像データを計算機に与えることで、計算機が自ら特徴を学習し、高精度な認識を実現します。これは、人間が特徴を設計する負担を大幅に減らすだけでなく、人間では見つけにくい隠れた特徴を発見できる可能性も秘めています。
例えば、猫の画像認識を例に考えてみましょう。従来の方法では、耳の形や目の色といった特徴を人間が定義し、計算機に教えていました。しかし、深層学習では、大量の猫の画像を計算機に与えるだけで、計算機は猫の特徴を自ら学習します。この学習過程で、人間が気づかなかった、猫特有の毛並み模様やひげの生え方といった特徴を計算機が発見するかもしれません。このように、深層学習は、人間の能力を超えた特徴抽出を可能にし、機械学習の適用範囲を大きく広げているのです。深層学習は、特徴設計の自動化という点で、機械学習の進化に大きく貢献したと言えるでしょう。
さらに、深層学習は、音声認識や自然言語処理といった分野にも大きな変革をもたらしました。音声認識では、音声データから音の高低や強弱といった特徴を自動的に学習し、高精度な音声認識を可能にしています。自然言語処理では、文章の構造や単語の意味関係といった複雑な特徴を学習し、文章の理解や生成といった高度な処理を実現しています。このように、深層学習は様々な分野で活用され、私たちの生活をより便利で豊かにする技術として期待されています。
| 項目 | 従来の機械学習 | 深層学習 |
|---|---|---|
| 特徴設計 | 人間が設計(例:画像の輪郭、模様など) 専門知識が必要 時間と労力がかかる |
計算機が自動学習 専門知識不要 隠れた特徴を発見可能 |
| 例(猫の画像認識) | 耳の形、目の色などを人間が定義 | 大量の猫画像から自動で特徴学習(例:毛並み模様、ひげの生え方など) |
| メリット | – | 特徴設計の自動化 人間の能力を超えた特徴抽出 機械学習の適用範囲拡大 |
| 応用分野 | – | 画像認識 音声認識 自然言語処理 |
深層学習の限界

近年の技術革新において、深層学習は目覚ましい成果を上げており、様々な分野で応用されています。画像認識や音声認識、自然言語処理など、多くの領域で従来の手法を凌駕する性能を示し、私たちの生活にも大きな変化をもたらしています。しかし、深層学習は万能な解決策ではなく、いくつかの重要な限界も抱えています。
まず、深層学習モデルは膨大な量の学習データを必要とします。人間であれば少数の例から学習できますが、深層学習モデルの場合は、質の高いデータを大量に与えなければ、望ましい性能に到達しません。そのため、データの入手が困難な分野や、データ量が限られている状況では、深層学習の適用が難しい場合があります。特に、特殊な専門知識が必要な分野では、質の高いデータを集めることが大きな課題となります。
次に、学習データに偏りがある場合、モデルが偏った学習をしてしまう可能性があります。例えば、特定の人種や性別のデータが多く含まれる学習データで訓練された顔認識システムは、その他の属性を持つ人々に対して、認識精度が低下するといった問題が発生する可能性があります。これは公平性の観点からも重要な問題であり、深層学習モデルを開発・運用する際には、学習データの偏りを慎重に考慮する必要があります。
さらに、深層学習モデルはブラックボックスと呼ばれることもあり、なぜ特定の結果を出力したのかを説明することが難しいという課題があります。モデル内部の複雑な計算過程は人間にとって理解しづらく、その判断根拠を明確に示すことが困難です。医療診断など、人命に関わる意思決定に深層学習を適用する場合には、モデルの出力結果だけでなく、その根拠を理解することが不可欠です。そのため、説明可能な人工知能(説明可能AI)と呼ばれる、モデルの判断根拠を説明できる技術の開発が重要な研究テーマとなっています。
このように、深層学習は大きな可能性を秘めている一方で、いくつかの限界も抱えています。深層学習を効果的に活用するためには、これらの限界を理解し、データの量と質、モデルの解釈可能性といった点に注意深く配慮する必要があります。
| 深層学習のメリット | 深層学習のデメリット |
|---|---|
|
|
今後の展望

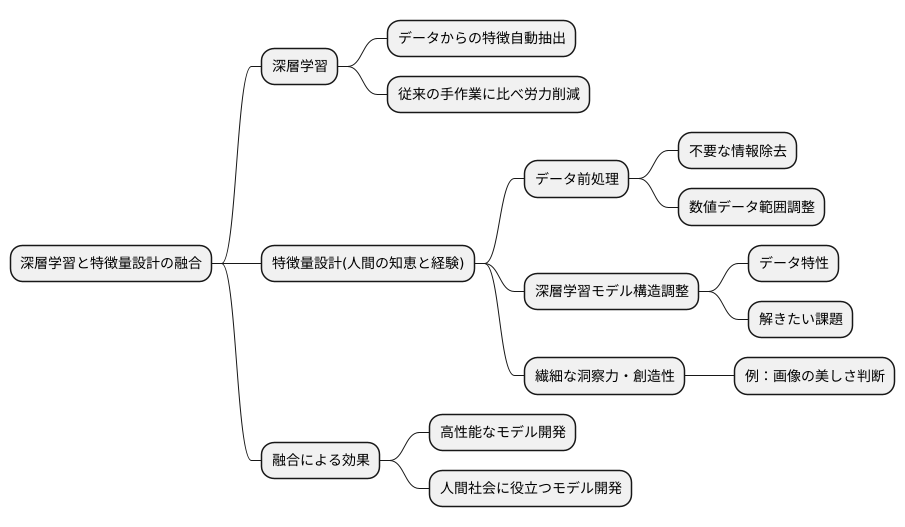
近年の技術革新により、機械学習分野では深層学習が著しい発展を遂げてきました。この画期的な手法は、データから特徴を自動的に抽出することを可能にし、従来の手作業による特徴量の設計に比べて、多大な労力を省くことができます。しかしながら、深層学習だけで全てが解決できるわけではありません。現状では、人間の知恵と経験に基づく特徴量設計の重要性は依然として高く、むしろ深層学習をより効果的に活用するために必要不可欠です。
例えば、集めたデータをそのまま深層学習モデルに与えるのではなく、目的に合わせて適切な前処理を行うことが重要です。不要な情報を取り除いたり、数値データの範囲を調整したりすることで、モデルの学習効率を向上させることができます。これは人間の専門知識に基づいた判断が必要となる場面です。また、深層学習モデルの構造自体も、データの特性や解きたい課題に合わせて調整する必要があります。適切な構造を選択することで、モデルの精度を向上させることができます。これもまた、人間の経験と洞察力が重要な役割を果たします。
さらに、深層学習モデルは大量のデータからパターンを学習することに長けていますが、人間の持つ繊細な洞察力や創造性までは再現できません。例えば、ある画像に写っている物体が「美しい」かどうかを判断する場合、深層学習モデルは画素のパターンを学習できますが、美しさの本質を理解することはできません。このような場面では、人間が持つ感性に基づいた特徴量設計が重要となります。
つまり、今後の機械学習の発展においては、深層学習と人間による特徴量設計の融合が鍵となります。それぞれの長所を活かすことで、より高性能で、より人間社会に役立つモデルを開発することが期待されます。人工知能技術の進歩とともに、特徴量設計の手法も進化を続け、様々な分野で応用されていくでしょう。そして、この技術の進歩は、私たちの暮らしをより便利で豊かなものにしていくと確信しています。