生成AIの公平性:偏見のない未来へ

AIを知りたい
先生、「公平性」っていう言葉の意味がよくわからないんですけど…教えてもらえますか?

AIエンジニア
ああ、人工知能の「公平性」ね。簡単に言うと、人工知能がみんなにとって平等であるべきってことだよ。例えば、人工知能が男性だけを優遇したり、特定の地域の人たちを差別したりするようなことがあってはいけないんだ。
AIを知りたい
なるほど。でも、どうして人工知能が差別するようになるんですか?
AIエンジニア
それはね、人工知能は人間が作ったデータから学ぶからなんだ。もし、そのデータに差別的な情報がたくさん含まれていたら、人工知能も差別を覚えてしまうんだよ。だから、データの偏りをなくすことが大切なんだね。
公平性とは。
人工知能に関する言葉で「公平さ」というものがあります。これは、人工知能で作られたものが、様々な人や集団に対して、かたよりなく作られているかどうかを意味します。人工知能は現実のデータから学ぶため、現実にある差別をそのまま反映してしまうおそれがあります。例えば、性別や人種、年齢、性的指向、障がいの有無などによって、不公平な結果が出てしまわないようにしなければなりません。公平さを保つためには、データのかたよりや、人工知能の判断の理由が分かりやすいかどうかなどに気をつけ、慎重に人工知能を作り、学習させていく必要があります。
はじめに

近ごろ、驚くほどの速さで進歩している生成人工知能という技術は、文章や絵、音楽など、様々な種類の作品を生み出すことができるようになりました。この画期的な技術は、私たちの暮らしをより便利で楽しいものにする大きな力を持っています。しかし、同時に、公平さに関する問題も抱えています。生成人工知能は、学習のために使うデータに含まれている偏りや差別を、そのまま作品に反映させてしまうことがあるからです。たとえば、ある特定の属性を持つ人物を、好ましくない形で描写してしまうといったことが考えられます。このようなことが起こると、社会的な不平等を助長したり、特定の人々を傷つけたりする可能性があります。このため、生成人工知能を使う際には、慎重な配慮が欠かせません。
生成人工知能が公平さを欠く原因の一つに、学習データの偏りがあります。インターネット上のデータなどを大量に学習させることで、生成人工知能は様々な表現方法を習得します。しかし、もし学習データの中に、特定の性別や人種、国籍などに対して偏った情報が多く含まれていた場合、生成人工知能もまた、そのような偏った考え方を学習してしまうのです。また、生成人工知能の開発者や利用者の無意識の偏見も、問題を複雑にしています。開発者自身が特定の価値観を持っていると、意図せずとも、その価値観が人工知能の設計に影響を与える可能性があります。同様に、利用者の偏見も、人工知能が出力する結果に影響を及ぼす可能性があります。
誰もが平等に扱われる社会を実現するためには、生成人工知能の公平性について、真剣に考える必要があります。学習データの偏りをなくすための技術的な工夫や、開発者や利用者に対する教育、そして、生成人工知能が社会に与える影響についての継続的な議論が必要です。生成人工知能は、正しく使えば、私たちの社会をより良くする力を持っています。だからこそ、公平性の問題を解決し、すべての人にとって有益な技術として発展させていく必要があるのです。
| 項目 | 内容 |
|---|---|
| 生成AIの特徴 | 文章、絵、音楽など様々な作品を生成できる。生活を便利で楽しくする可能性がある一方、公平性の問題も抱えている。 |
| 公平性を欠く原因 | 学習データの偏り(特定の属性への偏った情報を含むデータで学習すると、AIも偏った考え方を学習する) 開発者や利用者の無意識の偏見 |
| 公平性確保のための対策 | 学習データの偏りをなくす技術的工夫 開発者・利用者への教育 AIの社会への影響についての継続的議論 |
公平性とは何か

人が持つ感覚の一つに、公平さというものがあります。これは、誰に対しても同じように接し、えこひいきをしないということです。人工知能の世界でも、この公平さはとても大切な考え方です。人工知能が、特定のグループに有利なように、あるいは不利なように働くことはあってはなりません。例えば、人工知能が人の顔を見て、男か女か、若いのか年寄りなのかを判断するとします。そこで、男の人には優しく、女の人には冷たく接するようなことがあってはならないのです。肌の色や生まれた国、宗教、体の特徴など、どんな違いがあっても、人工知能はすべての人に対して平等に接するべきです。
人工知能は、たくさんの情報から物事を学ぶため、学ぶ情報に偏りがあると、その偏った考え方を覚えてしまいます。例えば、ある人工知能に、ほとんど男の人の顔だけを見せて学習させた場合、その人工知能は女の人の顔をうまく認識できないかもしれません。これは、学習に使った情報に偏りがあったことが原因です。人工知能を公平なものにするためには、学ぶ情報が偏っていないか、様々な角度から確認する必要があります。データを集める段階から、あらゆる人やものごとを平等に含めるように、細心の注意を払わなければなりません。
さらに、人工知能がどのように考えて答えを出したのかを、人が理解できるように説明することも大切です。人工知能の判断が、なぜそのような結果になったのかが分からなければ、その判断が本当に公平なのかどうかを確かめることができません。人工知能の思考過程を透明化することで、偏見や差別がないかを確認し、より公平な人工知能を作ることができるのです。人工知能が社会にとってより良いものとなるためには、公平性の確保が不可欠です。
| 項目 | 説明 |
|---|---|
| 公平性の定義 | 人工知能において、特定のグループに有利あるいは不利に働くことなく、誰に対しても平等に接すること。性別、年齢、肌の色、国籍、宗教、身体的特徴など、あらゆる違いにかかわらず平等であるべき。 |
| 公平性の重要性 | 人工知能が社会にとってより良いものとなるためには、公平性の確保が不可欠。 |
| 偏りの問題 | 人工知能は学習データに偏りがあると、偏った考え方を学習してしまう。例えば、男性の顔データだけで学習したAIは、女性の顔を認識できない可能性がある。 |
| 公平性確保のための対策 | 学習データの偏りをなくすために、データ収集段階からあらゆる人や物事を平等に含める必要がある。また、AIの思考過程を透明化し、判断理由を説明できるようにすることで、偏見や差別がないかを確認し、より公平なAIを作ることができる。 |
偏見の生まれる背景

人工知能が持つとされるものの見方の歪み、これは学習に使われた情報に潜む、社会の偏った考え方や差別が主な原因と考えられています。過去の情報には、歴史に刻まれた差別や社会的な不平等が反映されていることが少なくありません。そうした情報を学習した人工知能は、悪気がなくても差別的な結果を生み出す可能性があります。
例えば、過去の採用活動の情報に性差別的な傾向が含まれていたとしましょう。これを学習した人工知能は、女性の応募者を男性よりも低く評価するかもしれません。また、犯罪に関する過去の情報に人種差別的な要素が含まれていた場合、特定の人種の人々を犯罪者と結びつけてしまう可能性も考えられます。このような問題は、採用や犯罪捜査だけでなく、融資の審査や病気の診断など、様々な場面で起こり得ます。人工知能が社会の様々な場所で活用されるようになりつつある現在、その判断が偏見に基づいているとしたら、深刻な問題を引き起こす可能性があります。
こうした人工知能の偏見を取り除くためには、様々な対策が必要です。まず、学習に使う情報の偏りを修正することが重要です。具体的には、偏った情報を取り除いたり、公平な情報を追加したりすることで、人工知能がバランスの取れた情報を学習できるように工夫します。また、人工知能の仕組み自体を改良することも必要です。偏見を生まないような学習方法を開発したり、人工知能の判断過程を人間が理解しやすくすることで、偏見が生じた際に修正しやすくするといった取り組みが考えられます。さらに、人工知能が出した結果をそのまま鵜呑みにするのではなく、人間が常に注意深く監視し、必要に応じて修正していくことも重要です。人工知能は便利な道具ですが、完璧ではありません。道具を使う人間側の責任として、人工知能の偏見を認識し、適切に対処していく必要があります。
| 問題点 | 原因 | 例 | 対策 |
|---|---|---|---|
| 人工知能のものの見方の歪み、差別的判断 | 学習データに含まれる社会の偏見や差別(過去の差別や不平等) | 性差別的な採用データ学習→女性応募者を低評価 人種差別的な犯罪データ学習→特定人種を犯罪者扱い |
学習データの偏り修正(偏った情報の除去、公平な情報の追加) AIの仕組み改良(偏見を生まない学習方法、判断過程の可視化) AIの判断結果の監視と修正 |
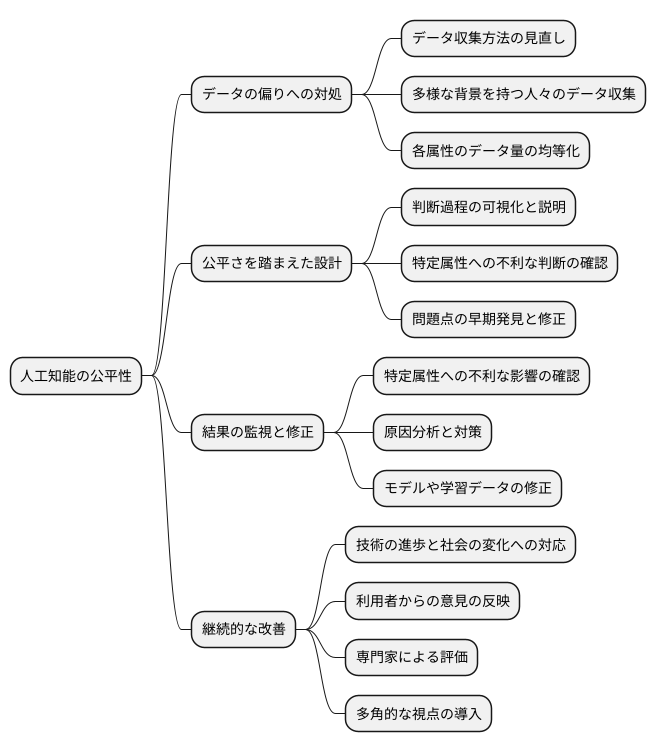
公平性を確保するための対策

人工知能が誰もにとって公平であるようにするには、様々な方法を組み合わせて取り組む必要があります。何よりもまず、学習させるデータに偏りがないかを調べ、修正することが大切です。データを集める方法を見直し、様々な背景を持つ人々のデータを集めることで、偏りを少なくすることができます。集めたデータの量も、それぞれの属性で均等になるように調整する必要があります。
人工知能を作る際にも、公平さを踏まえた設計が欠かせません。人工知能がどのように判断しているのかを分かりやすく示し、説明できるようにすることで、偏った考えがないかを確認しやすくなります。例えば、人工知能が特定の属性の人々を不利に扱うような判断をしていないかを、判断の根拠とともに明らかにすることで、問題点を早期に発見し、修正することができます。
さらに、人工知能が出した結果を常に監視し、必要に応じて修正していくことも大切です。人工知能が出した結果が、特定の属性の人々に不利な影響を与えていないかを継続的に確認する必要があります。もし問題があれば、その原因を分析し、人工知能のモデルや学習データの修正など、適切な対策を講じる必要があります。公平さを保つためには、一度対策をすれば終わりではなく、常に改善を続ける必要があるのです。技術の進歩や社会の変化に合わせて、人工知能の公平性についても継続的に見直し、より良いものにしていく努力が求められます。そのためには、利用者からの意見や専門家による評価なども参考にしながら、多角的な視点を取り入れることが重要です。人工知能が社会にとってより良いものとなるよう、たゆまぬ努力が必要です。
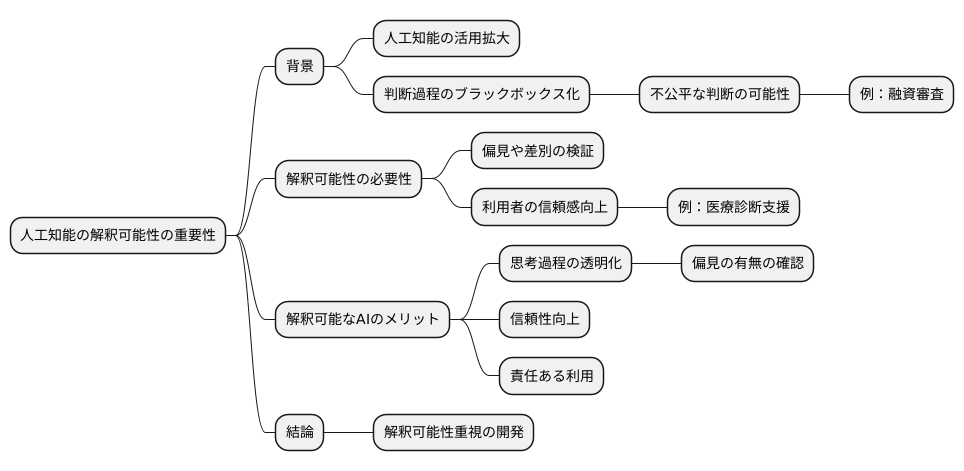
解釈可能性の重要性

近頃、様々な分野で人工知能が活用されるようになってきました。それと同時に、人工知能の判断がどのように行われているのかを理解すること、つまり解釈可能性の重要性がますます高まっています。
人工知能、特に深層学習と呼ばれる技術は、複雑な計算を通して結果を導き出します。しかし、その計算過程がブラックボックス化されている場合、なぜそのような結果になったのかを人間が理解することは困難です。例えば、ある人工知能が融資の審査を行うと想像してみてください。もし審査に落ちてしまったとしても、その理由が分からなければ納得できないばかりか、不公平な扱いを受けている可能性も考えられます。人工知能が人種や性別といった要素で差別的な判断をしているとは知らず知らずのうちに行われているかもしれません。このような事態を防ぐためには、人工知能の判断過程を明らかにし、偏見や差別がないかを検証する必要があります。これが解釈可能性の重要性です。
解釈可能な人工知能を開発することで、人工知能の思考過程を透明化することができます。これは、まるでガラス張りの箱の中で人工知能が考えている様子を見ることができるようなものです。どのように情報が処理され、最終的な判断に至るのかが分かれば、偏見の有無を確かめることができます。また、利用者も人工知能の判断の根拠を理解することで、人工知能に対する信頼感を高めることができます。例えば、医療診断支援を行う人工知能であれば、医師がその診断根拠を理解することで、人工知能の判断をより適切に活用できるようになります。
解釈可能性は、単に公平性を確保するだけでなく、人工知能の信頼性を高め、責任ある利用にも繋がります。人工知能が社会にとってより良い存在となるためには、解釈可能性を重視した開発を進めていく必要があると言えるでしょう。
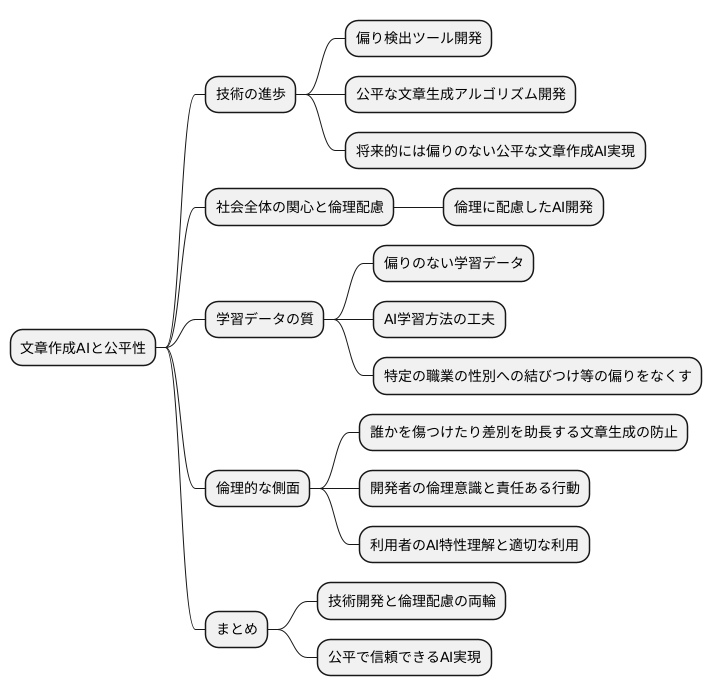
今後の展望

文章を創作する人工知能技術は、近年、目覚ましい発展を遂げています。それと同時に、人工知能が作り出す文章に偏りがないか、公平性をどう確保するかという研究も盛んに行われています。たとえば、人工知能が書いた文章に潜む偏りを探し出す道具や、より公平な文章が作れるようにする計算方法などが開発されています。
こうした技術がさらに進化し、実際に使えるようになれば、偏りのない、公平な文章を作る人工知能が実現するでしょう。これは大いに期待できることです。しかし、技術の進歩だけでは問題は解決しません。人工知能が作る文章の公平性について、社会全体で関心を高め、倫理に配慮した人工知能開発を進めていく必要があります。
人工知能は膨大な量の情報を学習します。もし学習データに偏りがあれば、人工知能が作る文章にも偏りが出てしまう可能性があります。たとえば、特定の職業を男性か女性に結び付けて考えてしまうような文章を生成するかもしれません。このような偏りをなくすためには、学習データの質を高めるだけでなく、人工知能の学習方法自体も工夫する必要があります。
また、人工知能が作り出した文章が、誰かを傷つけたり、差別を助長したりするようなことがあってはなりません。人工知能を開発する人たちは、倫理的な側面を常に意識し、責任ある行動をとる必要があります。同時に、利用者も人工知能の特性や限界を理解し、適切に使うことが大切です。
人工知能が社会にとって本当に役立つものとなるためには、技術開発と倫理的な配慮の両方が欠かせません。技術の進歩と社会の意識向上、この両輪によって、公平で信頼できる人工知能の実現を目指していく必要があるでしょう。