ゲームAIの進化:深層強化学習の力

AIを知りたい
先生、深層強化学習ってゲームAIと相性がいいって聞いたんですけど、どうしてですか?

AIエンジニア
いい質問だね。ゲームには明確な「勝ち負け」あるいは「点数」といった評価基準があるよね。深層強化学習は、この評価基準を報酬として学習を進めることができるから、ゲームAIと相性がいいんだ。たとえば、囲碁AIのAlpha碁は「勝利」を報酬として、強くなっていくんだよ。
AIを知りたい
Alpha碁はどうやって強くなっていくんですか?
AIエンジニア
Alpha碁は、最初はプロ棋士の棋譜を学習してある程度の強さを身につける。その後、自分自身と何度も対戦を繰り返すことで、さらに強くなっていくんだ。この自己対戦を通じて、より良い手を探索し、勝利に繋がる戦略を学習していくんだよ。Alpha碁Zeroはさらにすごい。教師データなしで、自己対戦だけでAlpha碁を超える強さを身につけたんだよ。
深層強化学習とゲーム AIとは。
人工知能に関わる言葉である「深層強化学習とゲームで使う人工知能」について説明します。深層強化学習とゲームというのはとても相性が良く、ディープマインド社が作った「アルファ碁」という人工知能が2016年に世界のトップレベルの囲碁の先生を打ち負かし、世界中の人々に驚きを与えました。アルファ碁はまず、プロの棋士の打ち方を手本として学習しました。その後、「勝ち」を目標として、自分自身と何度も何度も対戦を繰り返すことで、プロの棋士よりも強い力を手に入れました。アルファ碁は盤面の状態を画像認識の技術で把握し、次にどこに石を置くかを、モンテカルロ法という計算方法を使って探します。さらに、後継のアルファ碁ゼロは、プロの棋士の打ち方を手本にすることなく、自分自身との対戦だけでアルファ碁よりも強くなりました。
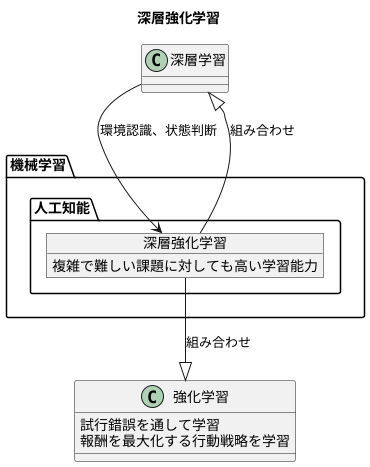
深層強化学習とは

深層強化学習は、機械学習という大きな枠組みの中にある、人工知能が賢くなるための一つの方法です。まるで人間が新しいことを学ぶように、試行錯誤を通して何が良くて何が悪いかを自ら学習していく点が特徴です。従来の強化学習という手法に、深層学習という技術を組み合わせることで、複雑で難しい課題に対しても、以前より遥かに高い学習能力を実現しました。
人工知能は、ある行動をとった時に、それに応じて得られる報酬をできるだけ大きくしようとします。そして、報酬を最大化する行動を見つけ出すために、最適な行動の戦略を自ら学習していくのです。この学習の進め方は、人間がゲームをしながら上手くなっていく過程によく似ています。例えば、新しいゲームを始めたばかりの時は、どうすれば良いかわからず、適当にボタンを押したり、キャラクターを動かしたりするしかありません。しかし、何度も遊ぶうちに、上手くいった行動と失敗した行動を徐々に理解し始めます。そして最終的には、まるで熟練者のように高度な技を使いこなし、ゲームを攻略できるようになるでしょう。
深層強化学習では、深層学習という技術が、主に周りの環境を認識したり、今の状態が良いか悪いかを判断したりするために使われます。例えば、ゲームの画面に映っているたくさんの情報の中から、重要な部分を見つけ出したり、複雑なゲームの状態を分かりやすく整理したりするのに役立ちます。このように、深層学習は、人工知能が複雑な状況を理解し、適切な行動を選択する上で重要な役割を担っているのです。
ゲームAIへの応用

近年の人工知能技術の進歩は目覚ましく、特にゲームの分野においては、深層強化学習と呼ばれる手法が大きな成果を上げています。この技術は、試行錯誤を通じて学習する強化学習に、人間の脳を模した深層学習を組み合わせたもので、複雑な状況における最適な行動を自ら獲得することができます。
その代表例として、グーグル傘下のディープマインド社が開発したアルファ碁が挙げられます。囲碁は、盤面の状態の数が膨大であるため、従来のコンピュータでは人間の熟練者に勝つことは困難でした。しかし、アルファ碁は深層強化学習を用いることで、膨大な数の対局データを学習し、プロ棋士をも凌駕するほどの強さを身につけました。これは、人工知能が複雑なゲームにおいても高度な戦略を学習できることを示す画期的な出来事であり、世界中に大きな衝撃を与えました。
アルファ碁の成功は、他のゲーム開発にも大きな影響を与えました。将棋やチェスといった伝統的なゲームだけでなく、複雑なルールや状況判断が求められるビデオゲームなど、様々な分野で深層強化学習が活用されています。これらのゲームにおいても、人工知能は既に人間と同等、あるいはそれ以上の能力を発揮するようになってきており、ゲーム体験の向上や新しい遊び方の創造に貢献しています。
深層強化学習は、ゲーム分野だけでなく、自動運転やロボット制御、創薬など、様々な分野への応用が期待されています。今後、更なる技術革新によって、私たちの生活を大きく変える可能性を秘めていると言えるでしょう。
| 技術 | 説明 | 代表例 | 応用分野 |
|---|---|---|---|
| 深層強化学習 | 試行錯誤を通じて学習する強化学習に、人間の脳を模した深層学習を組み合わせた手法。複雑な状況における最適な行動を自ら獲得できる。 | アルファ碁(囲碁AI、Google DeepMind開発) | ゲーム(囲碁、将棋、チェス、ビデオゲーム)、自動運転、ロボット制御、創薬など |
Alpha碁の学習方法

囲碁プログラム「アルファ碁」は、高度な学習方法によって驚くべき強さを手に入れました。その学習は大きく分けて二つの段階で行われました。最初の段階では、教師あり学習という方法を用いました。これは、過去のプロ棋士たちの棋譜データを使って学習する方法です。数多くの棋譜をコンピュータに読み込ませることで、アルファ碁は、まるで熟練の棋士が弟子に教えるように、様々な打ち方や戦術を学びました。いわば、過去の棋士たちの知恵を吸収していく段階と言えるでしょう。これにより、アルファ碁は、人間が何年もかけて学ぶような囲碁の基礎知識や定石を、短期間で身につけることができました。
次の段階では、強化学習という方法が使われました。これは、アルファ碁自身と対局を繰り返すという学習方法です。この自己対局では、「勝利」することが目標として設定されています。アルファ碁は、ひたすら自分自身と対局を繰り返し、勝利につながる打ち手を試行錯誤しながら探っていきます。まるで、一人二役で練習試合を繰り返すかのように、より良い打ち手を学習していくのです。この段階で重要なのは、人間が一切介入しないという点です。アルファ碁は、自らの対局結果だけを頼りに、独自の戦術や戦略を築き上げていくのです。この強化学習こそが、アルファ碁が人間を超える力を得る上で、非常に重要な役割を果たしました。膨大な数の自己対局を通じて、アルファ碁は時に人間では考えつかないような独創的な打ち手を発見し、その能力を飛躍的に向上させていったのです。
| 学習段階 | 学習方法 | 学習内容 | 結果 |
|---|---|---|---|
| 第一段階 | 教師あり学習 | 過去のプロ棋士の棋譜データから、様々な打ち方や戦術を学ぶ | 囲碁の基礎知識や定石を短期間で習得 |
| 第二段階 | 強化学習 | 自身との対局を繰り返し、勝利につながる打ち手を試行錯誤しながら探る | 人間を超える力、独創的な打ち手を獲得 |
Alpha碁Zeroの登場

囲碁という盤上遊戯の世界に、人工知能(AI)が大きな変革をもたらしました。その名をアルファ碁ゼロといいます。アルファ碁という名の、既に名高い囲碁AIの後継として登場したアルファ碁ゼロは、画期的な学習方法を備えていました。それは「教師なし学習」と呼ばれるもので、人の手を借りずに自ら学ぶ方法です。 これまでの囲碁AIは、過去の棋譜データ、つまり人が指した打ち方の記録を教師として、そこから学習をしていました。しかし、アルファ碁ゼロは違います。過去の棋譜データという人の知識に頼らず、全く白紙の状態から学習を始めたのです。具体的には、自分自身と何度も対戦を繰り返す「自己対局」という方法で、試行錯誤を繰り返しながら、徐々に強くなっていきました。驚くことに、この方法でアルファ碁ゼロは、人間の棋譜データを学習したpredecessorであるアルファ碁を凌駕する実力を身につけたのです。この成果は、深層強化学習という技術の秘めた可能性を示すだけにとどまりません。人が与えた知識に頼らなくても、AIが独自に成長し、進化を遂げられることを明らかにした、画期的な出来事でした。アルファ碁ゼロの成功は、AI研究における大きな進歩であり、これからのAI開発に多大なる影響を及ぼすことは間違いありません。人の知恵を超えたAIの誕生は、様々な分野で新たな機会を生み出すと期待される一方、未知の問題を私たちに突きつけていると言えるでしょう。
| 項目 | 内容 |
|---|---|
| AIの名前 | アルファ碁ゼロ |
| 前任AI | アルファ碁 |
| 学習方法 | 教師なし学習(自己対局) |
| 従来の学習方法 | 教師あり学習(過去の棋譜データ) |
| 成果 | アルファ碁を超える実力 |
| 意義 | AIが人の知識なしで成長できることを示した |
| 技術的背景 | 深層強化学習 |
| 将来への影響 | AI開発に大きな影響、様々な分野での新機会創出と未知の問題提起 |
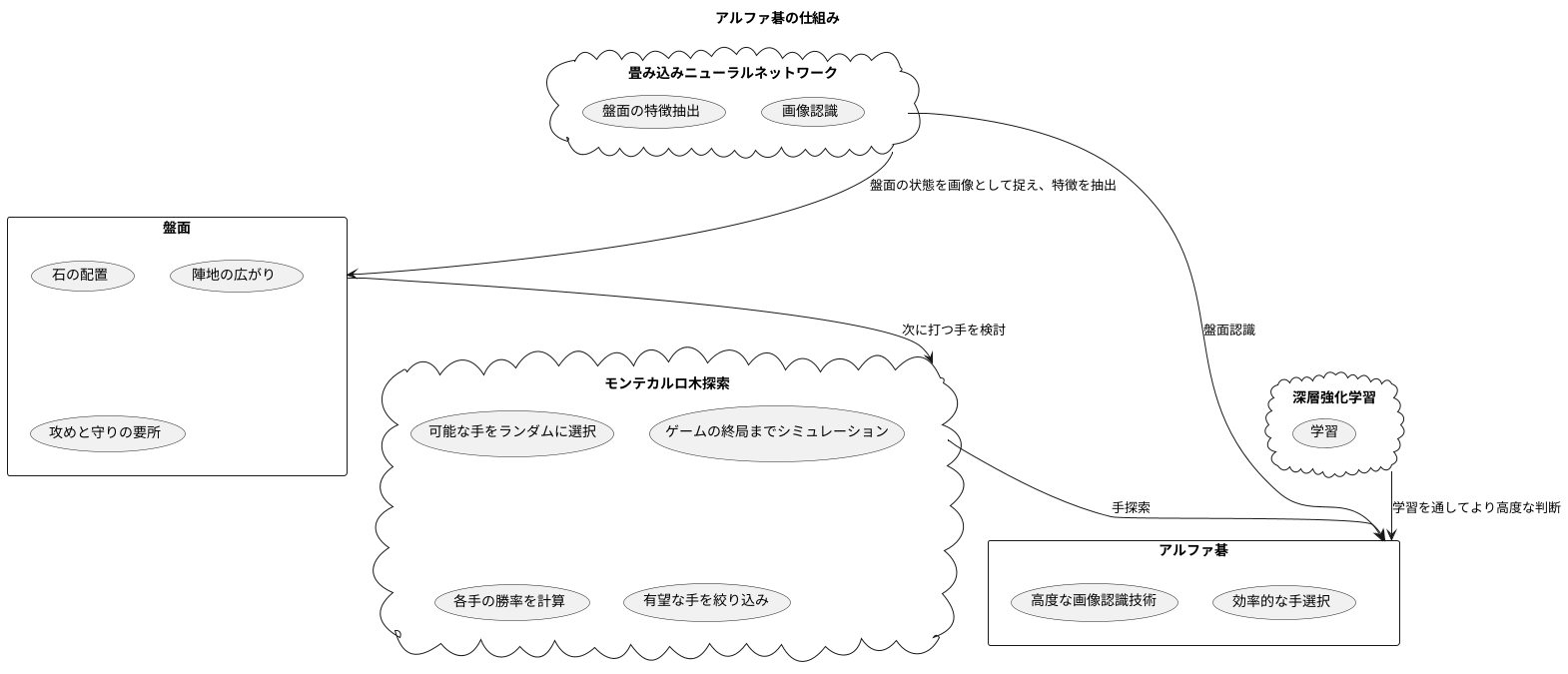
盤面認識と手探索

囲碁は、盤上の配置が複雑で、可能な手の数が膨大であるため、コンピュータにとって難しいゲームだと考えられてきました。しかし、盤面認識と手探索における技術革新により、人工知能は人間を凌駕する強さを手に入れました。その代表例がアルファ碁です。
アルファ碁は、まず盤面の状態を画像として捉え、その特徴を抽出します。このために用いられるのが、畳み込みニューラルネットワークという技術です。この技術は、人間の視覚のように、画像の中から重要な特徴を段階的に捉えることができます。例えば、石の配置や陣地の広がり、攻めと守りの要所など、盤面の複雑な情報を正確に読み取ることができます。これにより、アルファ碁は人間のように盤面を理解することができます。
次に、アルファ碁はモンテカルロ木探索という手法を用いて、次に打つ手を検討します。この手法は、盤面から可能な手をランダムに選び、ゲームの終局までシミュレーションを何度も繰り返します。そして、各手の勝率を計算することで、より良い手を見つけ出します。膨大な数の可能な手を全て検討するのではなく、統計的な手法を用いて有望な手を絞り込むことで、効率的に探索を行います。まるで未来を予測するように、どの手が勝利に繋がるかを検討します。
アルファ碁の強さは、盤面認識と手探索の組み合わせにあります。高度な画像認識技術によって盤面の状態を正確に把握し、モンテカルロ木探索によって最善の手を効率的に選択します。これらの技術は深層強化学習という枠組みの中で統合され、互いに影響を与えながら学習を進めることで、より高度な判断が可能になります。まるで熟練の棋士のように、盤面の全体像を把握し、最善の一手を打つことができるのです。