
過学習を防ぐ早期終了

AIを知りたい
先生、「早期終了」ってどういう意味ですか?なんか難しそうでよくわからないです。

AIエンジニア
そうだね、少し難しいけど、料理に例えて説明してみよう。例えば、カレーを作る時、スパイスを入れすぎると辛すぎて美味しくなくなってしまうよね?機械学習も同じで、学習させすぎると、特定のデータにだけ最適化されてしまい、新しいデータではうまく機能しなくなるんだ。これを「過学習」と言うんだよ。早期終了は、この過学習になる前に学習を止めることなんだ。
AIを知りたい
なるほど。カレーのスパイスの入れすぎと同じように、学習させすぎも良くないってことですね。じゃあ、どのタイミングで学習を止めればいいんですか?
AIエンジニア
良い質問だね。実際に使っていないデータで、時々カレーの味見をするように、学習にも使っていないデータで性能をチェックしながら、一番性能が良いところで学習を止めるんだ。そうすることで、新しいデータでもうまく機能するようになるんだよ。
早期終了とは。
人工知能の言葉で「早めに学習を終える」ということについて説明します。「早めに学習を終える」とは、人工知能が学習しすぎないようにするための方法です。学習しすぎると、知っているデータはうまく扱えるようになるけれど、知らないデータはうまく扱えなくなることがあります。これは、まるで教科書の文章は覚えたけれど、テストの問題が解けないような状態です。通常、人工知能の学習には練習用のデータを使います。この練習データに対する正答率を「練習での誤り率」と呼びます。一方で、練習では使っていない、初めて見るデータに対する正答率を「テストでの誤り率」と呼びます。学習が進むと、「練習での誤り率」は下がりますが、「テストでの誤り率」は上がることがあります。つまり、練習しすぎると、初めて見るデータにうまく対応できなくなるのです。「早めに学習を終える」とは、「テストでの誤り率」が一番低い時に学習をやめるという考え方です。
早期終了とは

機械学習では、未知のデータに対しても正確な予測ができるように、たくさんのデータを使って学習を行います。この学習のことを訓練と言い、訓練を通して学習の成果である予測精度を高めることが目標です。しかし、訓練をしすぎると、過学習という問題が発生することがあります。
過学習とは、訓練データに特化しすぎてしまい、新しいデータに対してうまく対応できなくなる現象です。例えるなら、試験勉強で過去問だけを完璧に覚え、似た問題しか解けなくなるような状態です。これでは、試験本番で初めて見る問題に対応できず、良い点数が取れません。機械学習でも同様に、過学習が起きると、未知のデータに対する予測精度が落ちてしまいます。
この過学習を防ぐための有効な手段の一つが早期終了です。早期終了とは、文字通り、訓練を早めに終わらせることです。訓練の過程では、検証データと呼ばれる、訓練には使っていないデータを使って定期的にモデルの性能をチェックします。検証データに対する予測精度が上がり続けているうちは、モデルは順調に学習していると考えられます。しかし、検証データに対する予測精度が頭打ちになり、その後低下し始めたら、それは過学習の兆候です。早期終了では、検証データに対する予測精度が最も高くなった時点で訓練を中断します。これにより、過学習を防ぎ、未知のデータに対しても高い予測精度を維持することができます。
早期終了は、比較的簡単な手法でありながら、過学習抑制に効果的です。そのため、様々な機械学習モデルで広く利用されています。最適な学習状態を維持し、より良い予測モデルを作るためには、早期終了は欠かせない技術と言えるでしょう。
過学習の兆候

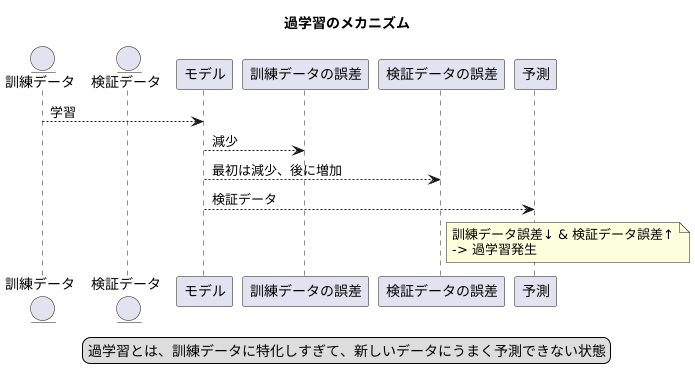
機械学習を行う上で、「過学習」は避けて通れない問題です。過学習とは、学習に用いるデータに特化しすぎてしまい、新しいデータに対してうまく予測できない状態のことを指します。まるで、教科書の例題は完璧に解けるのに、応用問題は全く解けない生徒のようなものです。
この過学習を見つけるには、いくつかの方法があります。その中でも重要なのが、訓練データと検証データの誤差の動きを比べることです。訓練データとは、モデルを作るために使うデータのことです。検証データとは、作ったモデルの性能を測るために使うデータで、訓練データとは別のデータを使います。
モデルが学習するにつれて、訓練データに対する誤差はどんどん小さくなっていきます。これは、モデルが訓練データをうまく説明できるようになっていることを示しています。しかし、同時に検証データに対する誤差も観察する必要があります。もし、訓練データの誤差は小さくなっているのに、検証データの誤差が大きくなり始めたら、それは過学習の兆候です。
これは、モデルが訓練データの特徴を細部まで覚え込みすぎて、新しいデータにうまく対応できなくなっていることを意味します。例えるなら、テストに出る問題の答えだけを丸暗記して、問題の意味を理解していない状態です。このような状態では、少し問題の出し方が変わると、途端に解けなくなってしまいます。
過学習を防ぐためには、この兆候を早期に捉え、学習を適切なタイミングで止めることが重要です。学習を続けすぎると、モデルはますます訓練データに特化し、汎化性能が失われてしまいます。ちょうど、詰め込み学習を続けると、他のことが頭に入らなくなってしまうのと同じです。
このように、訓練データと検証データの誤差の動きを注意深く観察することで、過学習の兆候を早期に発見し、より精度の高いモデルを作ることができます。
早期終了の実施方法

機械学習のモデル訓練において、学習時間を短縮し、過学習を防ぐ効果的な手法として早期終了があります。この手法は、比較的簡単な手順で実施できます。
まず、モデルの訓練は、訓練データと検証データの二つに分けて行います。訓練データは、モデルのパラメータ調整に用い、検証データは、調整されたモデルの性能評価に用います。訓練中は、一定の間隔で、訓練データで学習させたモデルを検証データに適用し、その誤差を計測します。この誤差を検証誤差と呼び、モデルの汎化性能の指標となります。
理想的なモデルは、訓練データだけでなく、未知のデータに対しても高い精度で予測できるモデルです。しかし、訓練を長く続けすぎると、モデルは訓練データの特徴を過度に学習し、未知のデータに対する予測精度が低下する現象、すなわち過学習が発生します。
早期終了は、この過学習を防ぐために、検証誤差に着目します。訓練が進むにつれて、検証誤差は最初は減少しますが、過学習が始まると増加に転じます。そこで、検証誤差が最小値を更新しなくなってから、一定の期間、訓練を継続し、それでも改善が見られない場合は訓練を中断します。この一定の期間を「忍耐のエポック」と呼びます。ここで、エポックとは、訓練データ全体を学習させた回数のことです。
忍耐のエポックの適切な値は、扱う問題の複雑さやデータの量、モデルの構造などによって変化します。そのため、様々な値を試して、最適な値を実験的に決定する必要があります。一般的には、数エポックから数十エポック程度の値が用いられます。適切に設定することで、過学習を抑制し、より汎化性能の高いモデルを構築できます。
早期終了の利点

機械学習の世界では、学習しすぎという困った問題によく直面します。これは、まるで試験勉強で過去問ばかり解きすぎて、新しい問題に対応できなくなるようなものです。この問題を解決する有効な手段の一つが「早期終了」です。
早期終了の最大の利点は、この学習しすぎを防ぎ、未知のデータに対しても高い精度で予測できる能力、つまり汎化性能を向上させることです。学習データにあまりにも適応しすぎると、新しいデータにうまく対応できなくなってしまいます。早期終了は、この過剰な適応を未然に防ぐ役割を果たします。丁度、料理の塩加減と同じで、入れすぎるとしょっぱくなって美味しくなくなってしまうように、学習もやりすぎると汎化性能が落ちてしまうのです。早期終了はこの塩加減を調整する大切な技術と言えるでしょう。
また、早期終了は学習にかかる時間を短縮するのにも役立ちます。学習しすぎの状態になるまで学習を続けるよりも、適切な時点で学習を止めることで、無駄な時間を省くことができます。これは、限られた時間の中で効率的に作業を進める上で非常に重要です。
さらに、早期終了は、学習の様々な設定を調整する作業を簡単にする効果もあります。例えば、学習の速さや複雑さを調整する設定項目があるのですが、早期終了を使うことで、学習しすぎを防ぎつつ、これらの設定を効率よく見つけることができます。色々な設定を試して最適な値を見つける作業は、時間と手間がかかる大変な作業ですが、早期終了はこの作業を効率化し、負担を軽減してくれるのです。
このように、早期終了は、過剰な学習を防ぎ、新しいデータへの対応力を高め、時間と手間を省く、機械学習にとって非常に有用な技術と言えるでしょう。
| 早期終了の利点 | 説明 | 例え |
|---|---|---|
| 汎化性能の向上 | 学習しすぎを防ぎ、未知のデータに対しても高い精度で予測できる能力を高める。 | 試験勉強で過去問ばかり解きすぎて、新しい問題に対応できなくなるのを防ぐ。 |
| 学習時間の短縮 | 適切な時点で学習を止めることで、無駄な学習時間を省く。 | – |
| 設定調整の効率化 | 学習の速さや複雑さを調整する設定項目の最適値を効率よく見つけることができる。 | 料理の塩加減を調整するように、最適な学習度合いを見つける。 |
早期終了と正則化

学習を繰り返すほど、訓練データに対する精度は上がりますが、未知のデータに対する精度は下がることがあります。これが過学習と呼ばれる現象で、複雑すぎるモデルが訓練データの特徴を細かすぎるまで捉えてしまうことが原因です。この過学習を防ぐための有効な方法として、早期終了と正則化という二つの手法があります。
早期終了とは、訓練データの精度が上がり続ける中で、検証データの精度が改善しなくなった時点で学習を打ち切る手法です。検証データとは、訓練データとは別に用意した、モデルの性能を評価するためのデータです。学習初期は訓練データと検証データの精度は共に上昇しますが、過学習が始まると訓練データの精度は上がり続ける一方、検証データの精度は頭打ちになり、やがて低下し始めます。この時点で学習を止めることで、過学習を防ぎ、未知のデータに対しても良い性能を発揮するモデルを構築できます。
一方、正則化は、モデルの複雑さに罰則を加えることで過学習を抑制する手法です。複雑なモデルは、多くの係数を持つことが多く、これらの係数の値が大きくなると、モデルは訓練データの些細な変化にも過剰に反応するようになります。正則化は、これらの係数の大きさを抑えることで、モデルを滑らかにし、過学習を防ぎます。正則化には、係数の絶対値の和に罰則を加えるものや、係数の二乗和に罰則を加えるものなど、様々な種類があります。
早期終了と正則化は、それぞれ異なる仕組みで過学習を防ぐため、組み合わせて使うことで、より効果的に過学習を防ぐことができます。例えば、正則化によってモデルの複雑さをある程度制限した上で、早期終了を用いて最適な学習のタイミングを決定することで、より頑健で、未知のデータに対しても高い性能を発揮するモデルを構築することが可能です。早期終了は計算量を削減する効果もあり、正則化と組み合わせることで、より効率的なモデル構築が可能になります。
様々な場面での活用

色々な場面で使える便利な技術に「早期終了」というものがあります。これは、機械学習の世界で、まるで料理における「味見」のような役割を果たします。
料理を作る時、味見をしてちょうど良い塩梅になったら火を止めますよね。早期終了もこれと同じで、学習の途中でモデルの出来具合を確かめ、丁度良い状態になったら学習を止めるのです。
この早期終了は、色々な種類の機械学習モデルで使うことができます。例えば、人間の脳の仕組みを真似た「ニューラルネットワーク」はもちろんのこと、データの繋がりを樹形図のように整理して予測する「決定木」や、データを高次元空間に配置して分類する「サポートベクターマシン」など、様々なモデルで応用できます。
早期終了が活躍する分野も多岐にわたります。写真や絵の内容を理解する「画像認識」、人の言葉を理解する「自然言語処理」、人の声を文字に変換する「音声認識」など、様々な分野で利用されています。
特に、最近の流行である「深層学習」では、早期終了はなくてはならない技術となっています。深層学習は複雑なモデルであるがゆえに、まるで物事を覚えすぎて応用が効かなくなる人間の「過学習」状態に陥りやすいという欠点があります。
早期終了を使うことで、この過学習を防ぎ、モデルの能力を最大限に引き出すことが可能になります。丁度良いところで学習を止めることで、より正確な予測をできるようになるのです。
このように、早期終了は様々な機械学習の課題において、積極的に使っていくべき重要な技術と言えるでしょう。
| 項目 | 説明 |
|---|---|
| 早期終了の役割 | 機械学習におけるモデルの学習を適切なタイミングで終了させる技術。料理の味見のように、丁度良い状態になったら学習を止める。 |
| 対応モデル | ニューラルネットワーク、決定木、サポートベクターマシンなど、様々な機械学習モデルで使用可能。 |
| 応用分野 | 画像認識、自然言語処理、音声認識など、多岐にわたる分野で利用されている。 |
| 深層学習との関係 | 深層学習では過学習を防ぐために必要不可欠な技術。 |
| メリット | 過学習を防ぎ、モデルの能力を最大限に引き出し、より正確な予測を可能にする。 |