
本番環境での機械学習モデル運用

AIを知りたい
先生、「本番環境での実装・運用」って、作ったAIを実際に使う段階のことですよね?具体的に何をすればいいんでしょうか?

AIエンジニア
そうだね。作ったAIを実際に使う段階のことだよ。まず大切なのは、AIの「監視」だ。実際に世の中で使ってみると、学習の時とは違う動きをすることが多いんだ。だから、きちんと動いているか、精度が落ちたりしていないかを常にチェックする必要があるんだよ。
AIを知りたい
なるほど。でも、もしうまく動かなかったり、精度が落ちたりしたらどうするんですか?
AIエンジニア
そういう時は、実際に使っている中で得られたデータを使ってAIをもう一度学習させるんだ。世の中の状況が変われば、AIもそれに合わせて成長させる必要があるからね。それと、AIを作る人と使う人が違う場合は、作った時の説明をしっかり残しておくことも大切だよ。後で困らないようにね。
本番環境での実装・運用とは。
人工知能に関わる言葉である「実際に運用するために準備して動かすこと」(学習し終えた模型の開発が終わって、実際に運用するために準備して動かす時に考えなければならないことがあります。まず必要なことは、様子をみることです。実際に運用する時は現実世界の情報を使って予測するので、学習時とは違う動きになることがよくあります。この違いにすぐ気づいて対策するために、正しさの監視といった作業を行う必要があります。また、運用していく中で実際に手に入れた情報を使って模型をもう一度学習させることもあります。周りの環境が変わった場合も、説明に使う情報の追加や模型の再学習が必要です。準備するチームと運用するチームが同じ場合は問題ないのですが、違う場合はプログラムの意図が分かりにくいこともあるので、開発の時点で分かりやすいプログラムを書くこと、チーム間で説明し合うことを徹底する必要があります。)について
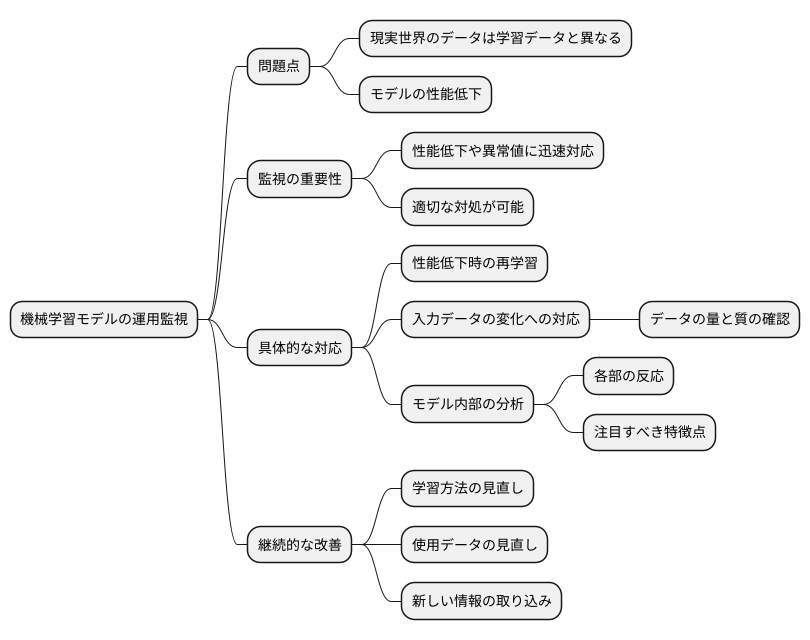
監視の重要性

機械学習の模型を実際に使う場面では、作った時とは違う情報に触れることになります。私たちが普段扱う情報は、模型を作る時に使った学習用の情報とは性質が違うことが多く、模型が思った通りに動かないこともよくあります。このような問題に早く対応するには、模型の正しさなど、色々な尺度を常に見ておくことがとても大切です。見守る仕組みを作っておくことで、予想外の性能低下や変な値が出てきた時にすぐ気づき、適切な対応ができます。
例えば、模型の予測の正しさが下がった場合、もう一度学習し直す必要があるかもしれません。また、入力される情報の性質が変わってきた場合、模型が想定外の情報にさらされている可能性があり、なぜそうなっているのかを調べる必要があります。原因を探るには、まず入力データそのものを見直す必要があります。情報の量に偏りがないか、質が以前と変わっていないかなどを確認することで、問題点が見えてくることがあります。
もし原因が特定できない場合は、模型の中身についてより深く調べる必要があるでしょう。模型の各部分がどのように情報に反応しているか、注目すべき特徴点は何かを分析することで、性能低下のより具体的な原因が見えてきます。
さらに、常に変化する現実世界の状況に合わせて、模型の学習方法や使う情報も見直すことが重要です。新しい情報を取り入れて模型を更新することで、予測精度を高く保ち、より良い結果を得ることができます。このように、常に気を配り、見守ることは、模型を安定して使えるようにする上で欠かせないことと言えるでしょう。
再学習の必要性

機械学習の模型は、まるで生き物のように、常に変化する周りの状況に合わせ、学び続ける必要があります。一度学習を終えただけでは、すぐに時代の流れに取り残されてしまうのです。このため、模型に新たな知識を教え込む「再学習」が欠かせません。
私たちの周りの世界は絶えず変化しています。流行の移り変わり、経済の変動、新しい技術の登場など、データの様相は刻一刻と変わっていきます。最初に学習させた時のデータは、時間の経過とともに古くなり、現実を反映しなくなってしまうのです。このような古い知識に基づいて判断を下すと、誤った結果を導き出す可能性が高まります。まるで、昔の地図を頼りに現代の街を navigate するようなものです。
再学習は、模型に最新の情報を注入し、変化への対応力を高めるための手段です。新しいデータを与えることで、模型は現状をより正確に理解し、より精度の高い予測や判断を行うことができるようになります。これは、地図を最新版に更新するようなものです。
再学習の頻度は、状況に合わせて調整する必要があります。めまぐるしく変化する金融市場の予測など、変化の激しい分野では頻繁な再学習が必要です。一方、比較的安定したデータを用いる画像認識などは、それほど頻繁に再学習する必要はありません。
大切なのは、適切な再学習の計画を立て、模型の状態を常に管理することです。適切なタイミングで再学習を行うことで、模型の性能を維持し、常に最良の結果を得ることができるのです。
| 項目 | 説明 |
|---|---|
| 機械学習モデルの性質 | 常に変化する状況に適応し、学び続ける必要がある。一度の学習では不十分。 |
| 再学習の必要性 | データは時間とともに変化するため、古いデータに基づく判断は誤りやすい。 |
| 再学習の効果 | モデルに最新情報を注入し、変化への対応力を高める。より正確な予測や判断が可能になる。 |
| 再学習の頻度 | 状況に合わせて調整が必要。変化の激しい分野では頻繁に、安定した分野ではあまり必要ない。 |
| 再学習の重要性 | 適切な計画と管理により、モデルの性能を維持し、最良の結果を得られる。 |
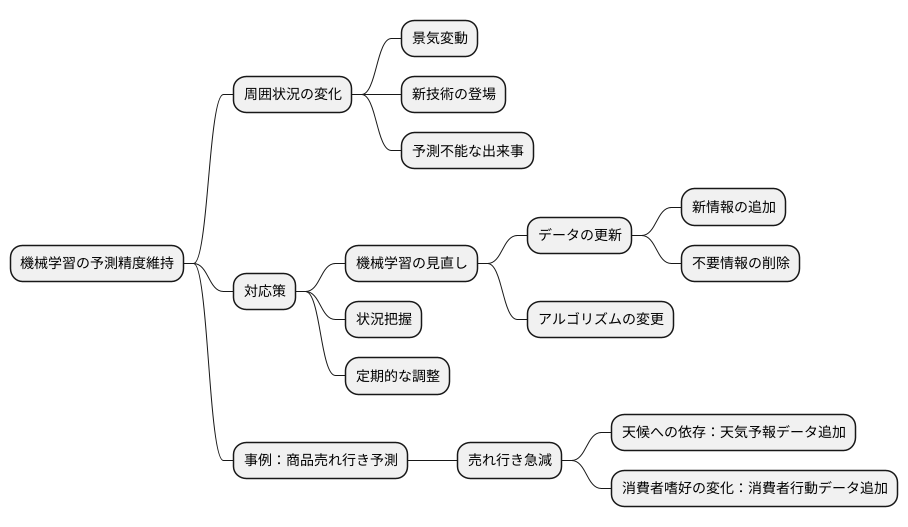
環境変化への対応

近頃、周りの状況がめまぐるしく変わっていく中で、機械学習の予測もその変化の影響を大きく受けています。例えば、景気が良くなったり悪くなったり、今までにない新しい技術が生まれたりといった、予測できない様々な出来事が、機械学習の正しさを左右するのです。
このような変化に素早く対応するには、機械学習の仕組みや使うデータを見直す必要があります。状況によっては、予測に役立つ新しい情報を加えたり、今までの情報の中から不要なものを取り除いたりする必要も出てくるでしょう。場合によっては、機械学習の仕組みそのものを作り直し、新しい計算方法を使うことも考えられます。
周りの状況を常に把握し、必要に応じて機械学習の内容を調整することで、変化の激しい状況でも変わらずに使えるようにしなければなりません。例えば、商品の売れ行きを予測する機械学習を考えてみましょう。ある商品が急に売れなくなったとします。もし、この商品の売れ行きが天候に左右されると分かれば、天気予報のデータを追加することで、予測の精度を上げることができるかもしれません。また、消費者の好みが変化したことで売れ行きが落ちているのであれば、消費者の行動に関する新しいデータを取り入れる必要があるでしょう。
このように、周りの変化にきちんと対応していくことは、機械学習を長くうまく使い続けるために欠かせないと言えるでしょう。周りの変化を常に感じ取り、必要に応じて機械学習を調整することで、常に正しい予測を続けられるように努力していくことが大切です。
チーム間の連携

機械学習の模型を開発する組と、それを実際に動かす組が別々の場合、両組がうまく連携をとることがとても大切です。それぞれの組がそれぞれの役割をきちんと果たし、こまめに情報をやり取りすることで、模型を安定して動かし、より良いものへと磨き上げていくことができます。
まず、模型を作る開発組は、作った模型の設計図や中身、書いた命令の細かな意味などを、動かす組に分かりやすく説明する必要があります。模型がどのように作られ、どのような仕組みで動くのかを伝えることで、動かす組は模型の特徴を正しく理解し、適切に扱うことができます。例えば、模型の弱点や、特別な扱いを必要とする部分などを伝えることで、後々の問題発生を防ぐことに繋がります。
次に、模型を動かす運用組は、模型が実際にどのように動いているのか、何か問題が起きたのかといった情報を、開発組に伝える必要があります。模型の動きを常に監視し、予想外の挙動や性能の低下などを見つけた場合は、すぐに開発組に報告することで、早期の発見と対策が可能になります。また、日々の運用の中で得られた知見や改善案なども伝えることで、模型の改良に役立ちます。
両組の情報共有は密に行うほど効果的です。例えば、運用組が模型の精度が落ちていることに気づいたとします。この情報をすぐに開発組に共有することで、原因の調査と対策が迅速に進められます。もし情報共有が遅れれば、問題の発見も遅れ、その分対策にも時間がかかってしまいます。
円滑な連携のために、日頃から情報交換しやすい仕組みを作っておくことも重要です。例えば、定期的に会合を開いたり、共通の記録帳を活用したりすることで、気軽に情報共有できる環境を作ることができます。こうした工夫によって、両組が同じ目標に向かって協力し、機械学習模型をより良いものへと育てていくことができます。
| 役割 | 責任 | 情報共有内容 |
|---|---|---|
| 開発組 | 模型の開発 |
|
| 運用組 | 模型の運用、監視 |
|
情報共有の例:
- 運用組が模型の精度低下に気づき、開発組に報告することで迅速な原因調査と対策が可能になる。
円滑な連携のための工夫:
- 定期的な会合
- 共通の記録帳の活用
分かりやすい資料作成

機械学習の模型を組み立てる際には、計算手順を記した文書だけでなく、関係する資料も読みやすく整えることが肝心です。模型の設計思想や、計算方法を選んだわけ、細かい設定を決めた理由など、開発の過程での判断をはっきりと記録しておくことで、後々の操作や修理を滞りなく進めることができます。資料は、開発担当者と運用担当者の情報共有を円滑にするだけでなく、新しく加わった担当者の学習の手間を減らすのにも役立ちます。
例えば、模型の正しさの評価に用いた尺度や情報群、評価結果などを細かく記録しておくことで、運用担当者は模型の性能を正しく把握し、適切な監視体制を整えることができます。また、評価に用いた情報群の選定基準や前処理方法を記録しておくことで、後から評価方法を再検討したり、別の情報群で再評価したりする際に役立ちます。さらに、模型の限界や注意点についても資料にまとめておくことで、運用担当者が誤った使い方をしたり、過大な期待を抱いたりすることを防ぐことができます。
計算手順を記した文書には、処理内容を丁寧に書き込むことも大切です。これは、手順書の読みやすさを高め、修正のしやすさを向上させる上で重要です。各処理の目的、入力と出力、使用している計算方法などを具体的に書き込むことで、他の人が手順書を理解しやすく、修正もしやすくなります。読みやすい資料作成は、機械学習模型の長期間にわたる運用を支える上で欠かせない要素です。計算手順を記した文書だけでなく、関連資料も読みやすく整え、開発担当者と運用担当者がスムーズに連携できる環境を整えることが、機械学習模型の成功につながります。
| 資料の種類 | 記載内容 | 目的/効果 |
|---|---|---|
| 模型設計書 | 設計思想、計算方法の選定理由、詳細設定の根拠、開発過程での判断 | 後々の操作や修理の円滑化、開発担当者と運用担当者の情報共有、新規担当者の学習コスト削減 |
| 模型評価記録 | 評価尺度、使用データ、評価結果、データ選定基準、前処理方法 | 模型性能の正確な把握、適切な監視体制構築、評価方法の再検討、別データでの再評価 |
| 模型限界/注意点 | 模型の限界、注意点 | 誤った使い方や過大な期待の防止 |
| 計算手順書 | 各処理の目的、入力と出力、使用している計算方法 | 手順書の読みやすさと修正のしやすさの向上 |