
深層強化学習:基礎と進化

AIを知りたい
先生、深層強化学習って難しそうですが、基本的な考え方ってどんな感じですか?

AIエンジニア
そうだね、深層強化学習は、簡単に言うと、コンピュータに試行錯誤を通して学習させる方法なんだ。ゲームでいうと、最初は下手だけど、何度もプレイすることで上手くなっていく、そんなイメージだよ。
AIを知りたい
なるほど。DQNって、その試行錯誤をどうやって実現しているんですか?
AIエンジニア
DQNは、今の状態と行動の良し悪しを数値で表す「Q値」というのを使って学習するんだ。どの行動をすれば、将来どれくらい良い結果になるかを予測して、Q値が最大になる行動を選ぶようにするんだよ。そして、実際に試してみて、その結果を元にQ値を修正していくんだ。ゲームでいうと、点数が高い行動ほどQ値が高くなるように学習していくイメージだね。
深層強化学習の基本的な手法と発展とは。
人工知能に関わる言葉である「深層強化学習の基礎的なやり方とその進展」について説明します。深層強化学習とは、強化学習と深層学習を組み合わせたものです。基本的なやり方として、ディー・キュー・エヌと呼ばれるものがあります。これは、「状態」と「行動」それぞれに、どのくらい良いかを表すキュー値を付けて、表を作成し、学習を通してその表をより良いものにしていく方法です。さらに進んだ方法として、ダブル・ディー・キュー・エヌというものがあります。これは、行動を選ぶための仕組みと、キュー値を決めるための仕組みを別々の仕組みで行うようにすることで、ディー・キュー・エヌが持っていた、キュー値を高く見積もりすぎてしまうという問題を解決しました。
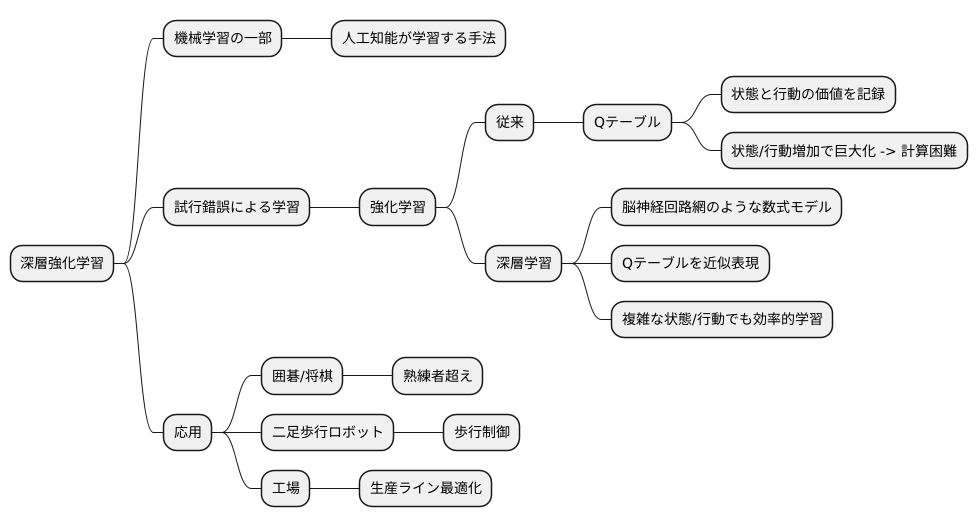
深層強化学習とは

深層強化学習は、機械学習という大きな枠組みの中の、人工知能が自ら学習していくための方法の一つです。この学習方法は、まるで人間が試行錯誤を繰り返しながら物事を覚えていく過程によく似ています。深層強化学習は、この試行錯誤による学習を「強化学習」と呼び、人間の脳の仕組みを真似た「深層学習」と呼ばれる技術を組み合わせたものと言えます。
従来の強化学習では、「状態」とそれに対応する「行動」の組み合わせによって得られる価値を、表の形にして記録していました。この表はQテーブルと呼ばれています。しかし、この方法は状態や行動の種類が増えると、表が巨大になりすぎてしまい、計算が難しくなるという欠点がありました。例えば、ゲームで言えば、ゲーム画面の状態やコントローラーの操作の種類が膨大になると、Qテーブルが大きくなりすぎてしまうのです。
そこで登場するのが深層学習です。深層学習を使うことで、巨大なQテーブルの代わりに、脳の神経回路網のように複雑な繋がりを持った数式モデルを作り、Qテーブルの中身を近似的に表現することができます。これが深層強化学習の核心です。この方法によって、状態や行動の種類が多く複雑な場合でも、効率的に学習を進めることが可能になりました。
深層強化学習は、複雑な判断を必要とする場面で特に力を発揮します。例えば、囲碁や将棋といった、状況に応じて様々な戦略を立てる必要があるゲームでは、既に人間の熟練者を超えるほどの強さを示しています。さらに、二足歩行ロボットの歩行制御や、工場の生産ラインをスムーズに動かすための最適化など、現実世界の問題解決にも役立ち始めています。深層強化学習は、これからますます発展していくと期待されており、様々な分野で広く活用されることが見込まれています。
基本的手法:DQN

深層強化学習という分野において、基本となる手法の一つにディー・キュー・エヌがあります。これは、キュー学習という、もととなる強化学習の手法を、ディープラーニングという技術で拡張したものです。
まず、キュー学習について説明します。キュー学習では、ある状態と行動の組み合わせが良いか悪いかを数値で表します。これをキュー値と呼び、状態と行動の組み合わせごとに、対応するキュー値を記録した表を作成します。この表はキュー表と呼ばれます。
しかし、扱う状態や行動の種類が非常に多い場合、キュー表は巨大になり、管理が難しくなります。そこで、ディー・キュー・エヌでは、このキュー表の代わりに、ニューラルネットワークを用いるという工夫をしています。ニューラルネットワークは、現在の状態を入力すると、それぞれの行動に対するキュー値を出力するように学習されます。これにより、状態や行動の種類が多くても、効率的に学習を進めることができます。
ディー・キュー・エヌの学習は、試行錯誤を通して行われます。学習を行う主体であるエージェントは、実際に環境の中で行動し、その結果として得られた経験を基に、ニューラルネットワークの繋がり方を調整していきます。具体的には、行動によって得られた報酬や、次の状態のキュー値などを考慮して、現在の状態における行動の価値をより正確に予測できるように、ネットワークを修正していきます。
ディー・キュー・エヌは、アタリの様々なゲームで優れた成績を収め、深層強化学習の発展に大きく寄与しました。しかし、ディー・キュー・エヌにはキュー値を実際よりも高く見積もってしまうという欠点も知られており、その後の研究では、この問題を解決するための改良が行われています。
| 手法 | 説明 | 利点 | 欠点 |
|---|---|---|---|
| キュー学習 | 状態と行動の組み合わせの良さをキュー値という数値で表し、キュー表に記録する。 | – | 状態や行動の種類が多い場合、キュー表が巨大になり管理が難しい。 |
| ディー・キュー・エヌ (DQN) | キュー学習をディープラーニングで拡張。キュー表の代わりにニューラルネットワークを用いて、状態を入力すると行動ごとのキュー値を出力する。 | 状態や行動の種類が多くても効率的に学習できる。アタリの様々なゲームで優れた成績を収めた。 | キュー値を実際よりも高く見積もってしまうことがある。 |
過大評価の問題とDouble DQN

深層強化学習という分野において、DQNは画期的な手法として登場しました。しかし、このDQNには行動の価値、つまりQ値を過大評価してしまうという問題がありました。それでは、なぜQ値の過大評価が起こってしまうのでしょうか。
Q値の推定にはどうしても避けられない不確かさ、つまりノイズが含まれます。このノイズが原因で、実際よりも大きなQ値がたまたま出てしまうことがあり、その結果、本来よりも良い行動だと誤って判断されてしまうのです。これは、たくさんの候補の中から一番大きな数を選ぼうとした時に、たまたま大きなノイズが含まれた数を選んでしまうようなものです。この過大評価は、学習の効率を悪くし、最終的に最適な行動を見つけることを妨げてしまう可能性がありました。
この過大評価問題を解決するために、Double DQNという改良版が開発されました。Double DQNの鍵となるのは、行動の選択とQ値の評価を別々のネットワークで行うという点です。DQNでは一つのネットワークで両方の役割を担っていましたが、Double DQNでは二つのネットワークを使うことで、より正確なQ値の推定を可能にしています。
具体的には、まず行動を選択するネットワークを使って、どの行動が最も良いかを判断します。そして、選ばれた行動の真の価値は、Q値を評価する別のネットワークを使って計算します。このように役割を分担することで、ノイズの影響を減らし、過大評価を抑えることができるのです。例えるなら、ある商品を買うかどうか迷っている時に、友達にどれが良いか選んでもらい(行動の選択)、別の友達にその商品の本当の価値を評価してもらう(Q値の評価)ようなものです。
Double DQNは、DQNよりも安定した学習を実現し、多くの課題でDQNを上回る性能を示しました。つまり、より正確なQ値の推定によって、より良い行動を学習できるようになったということです。この手法は現在、深層強化学習における過大評価問題への対策として広く使われています。
更なる発展

深層強化学習は「二重ディーキューエヌ」以外にも、様々な発展を遂げています。その発展は多岐に渡り、様々な角度から学習効率の向上や新たな応用を目指した研究が行われています。
まず、「優先順位付き経験再生」という手法は、過去の経験の中から特に学習に重要な経験を優先的に再生することで、学習の効率を高めます。通常の学習では、すべての経験を平等に扱いますが、この手法では、より大きな学習効果が得られる経験を重点的に学習することで、無駄を省き、より速く、より効果的に学習を進めることができます。
次に、「二重化構造ネットワーク」は、「状態の価値」と「行動の優位性」を分けて考えることで、より精密な学習を可能にする手法です。従来の「キュー値」は、ある状態である行動をとった時の価値を表す一つの数値でしたが、この手法では、状態そのものの価値と、その状態において各行動がどれだけ優れているかを別々に評価します。これにより、様々な状況における行動の価値をより正確に把握することができ、より適切な行動を選択できるようになります。
これらの手法に加え、深層強化学習は様々な分野へ応用され、成果を上げています。例えば、機械の動きを自動で制御する「ロボット制御」、人間が運転しなくても車が安全に走行できる「自動運転」、病気の状態をコンピュータで判断する「医療診断」など、幅広い分野で活用されています。これらの分野では、深層強化学習によって、従来の方法では難しかった複雑な問題を解決できる可能性があり、更なる発展が期待されています。
このように深層強化学習は、様々な手法の開発や多様な分野への応用を通して、日々進化を続けています。今後も、更なる技術革新と、より広範な分野への応用が期待される、大変将来性のある分野と言えるでしょう。
| 手法名 | 概要 | 効果 |
|---|---|---|
| 優先順位付き経験再生 | 過去の経験の中から学習に重要な経験を優先的に再生する。 | 学習の効率を高め、より速く、より効果的に学習を進める。 |
| 二重化構造ネットワーク | 「状態の価値」と「行動の優位性」を分けて考える。 | 様々な状況における行動の価値をより正確に把握し、より適切な行動を選択できる。 |
| 応用分野 | 概要 |
|---|---|
| ロボット制御 | 機械の動きを自動で制御する |
| 自動運転 | 人間が運転しなくても車が安全に走行できるようにする |
| 医療診断 | 病気の状態をコンピュータで判断する |
深層強化学習の将来

深層強化学習は、人工知能の中でも特に注目されている技術です。機械が試行錯誤を通じて学習する強化学習に、人間の脳の仕組みを模倣した深層学習を組み合わせたこの技術は、様々な分野で大きな可能性を秘めています。
例えば、自動運転の分野では、深層強化学習によって、複雑な交通状況の中で安全かつ効率的な運転を機械に学習させることができます。人間のように状況を判断し、適切な行動を選択できる自動運転車は、交通事故の減少や渋滞の緩和に貢献すると期待されています。また、ロボット制御の分野でも、深層強化学習は革新をもたらすと考えられています。工場の生産ラインなどで活躍する産業用ロボットだけでなく、介護や家事といった日常生活を支援するロボットの開発にも役立つでしょう。さらに、医療診断の分野でも、深層強化学習は期待されています。画像診断や検査データの解析を通じて、医師の診断を支援したり、新たな治療法の開発に繋がったりする可能性があります。
このように様々な応用が期待される一方で、深層強化学習には克服すべき課題も残されています。一つは、学習に大量のデータが必要という点です。機械に望ましい行動を学習させるためには、膨大な量のデータを入力する必要があります。もう一つは、学習の不安定さです。学習の過程で、機械の行動が不安定になり、期待通りの結果が得られない場合もあります。これらの課題を解決するために、より効率的な学習方法の開発や、学習の安定性を高めるための技術の研究が盛んに行われています。
深層強化学習は、まだ発展途上の技術ですが、その潜在能力は計り知れません。今後、研究開発が進むにつれて、私たちの生活はますます豊かになり、様々な社会問題の解決にも貢献してくれることでしょう。深層強化学習の将来に、大きな期待が寄せられています。
| 分野 | 応用例 | 期待される効果 |
|---|---|---|
| 自動運転 | 複雑な交通状況での安全かつ効率的な運転 | 交通事故の減少、渋滞の緩和 |
| ロボット制御 | 産業用ロボット、介護・家事支援ロボット | 生産性向上、生活支援 |
| 医療診断 | 画像診断、検査データ解析 | 診断支援、新治療法開発 |
| 課題 | 詳細 |
|---|---|
| 学習データ | 大量のデータが必要 |
| 学習の不安定さ | 期待通りの結果が得られない場合がある |
まとめ

深層強化学習は、機械学習の一種である強化学習と、人間の脳の仕組みを模倣したディープラーニングを組み合わせた、強力な技術です。コンピュータが試行錯誤を通じて学習する強化学習に、複雑なデータを扱う能力を持つディープラーニングを組み合わせることで、従来の方法では難しかった高度なタスクをこなせるようになりました。
その始まりと言えるのが、ディープラーニングを用いたQ学習であるDQNです。DQNの登場は深層強化学習における大きな転換点となり、その後の研究に多大な影響を与えました。しかし、DQNには行動の価値であるQ値を過大評価してしまうという問題点がありました。この問題を解決するために、行動の選択と評価を分離するDouble DQNが登場し、より安定した学習を可能にしました。
深層強化学習はゲームのプレイにおいて優れた成績を収めているだけでなく、現実世界の問題解決にも応用されています。例えば、ロボットの制御や自動運転など、複雑で変化の多い状況に対応する必要があるタスクにおいても、目覚ましい成果を上げています。
さらに、過去の経験の中から重要なものを優先的に学習するPrioritized Experience Replayや、行動の価値と状態の価値を分けて学習するDueling Network Architectureなどの技術が登場しました。これらの技術は、学習の効率を向上させ、より複雑な環境への対応を可能にしました。
深層強化学習は今もなお発展を続けており、人工知能の発展を大きく推進しています。今後、様々な分野への応用が期待される、非常に有望な技術と言えるでしょう。
| 技術 | 説明 | 課題 | 解決策 |
|---|---|---|---|
| 深層強化学習 | 強化学習とディープラーニングを組み合わせた技術 | – | – |
| DQN | ディープラーニングを用いたQ学習 | Q値の過大評価 | Double DQN |
| Double DQN | 行動の選択と評価を分離 | – | – |
| Prioritized Experience Replay | 重要な経験を優先的に学習 | – | – |
| Dueling Network Architecture | 行動の価値と状態の価値を分けて学習 | – | – |