
決定木:データ分析の羅針盤

AIを知りたい
先生、『決定木』って、どういうものですか?なんだか木みたいに分かれるっていうのはなんとなくわかるんですけど…

AIエンジニア
そうだね。決定木は、名前の通り木のような構造で、上から下に枝分かれしていくことで答えを導き出す方法だよ。例えば、果物を分類するとしよう。最初の分岐で『赤いかどうか』で分け、赤いグループを『丸いかどうか』で分けると、リンゴやイチゴなどに分類できるよね。これが決定木のイメージだよ。
AIを知りたい
なるほど!最初の『赤いかどうか』や『丸いかどうか』が質問でいう『特徴量』で、リンゴやイチゴが『葉ノード』にあたるんですね!でも、どんな質問をすればいい感じに分類できるんですか?
AIエンジニア
良い質問だね!多くの場合、コンピュータがデータから適切な特徴量と分岐点を見つけるんだ。たくさんのデータから、一番うまく分類できる質問と分岐点を自動的に探してくれるんだよ。
決定木とは。
人工知能で使われる「決定木」という用語について説明します。決定木は、色々なものの特徴や値を順番に見ていくことで、枝分かれする道筋を作り、最終的に一つの結果を予測する方法です。木の根っこにあたる「根ノード」から、条件によって枝分かれし、木の葉にあたる「葉ノード」にたどり着くと、数値や種類などの結果が出ます。それぞれの枝分かれは、ある特徴について「もし~ならば」という形で表されるので、出来上がった予測の仕組みが理解しやすいという利点があります。
決定木の基礎

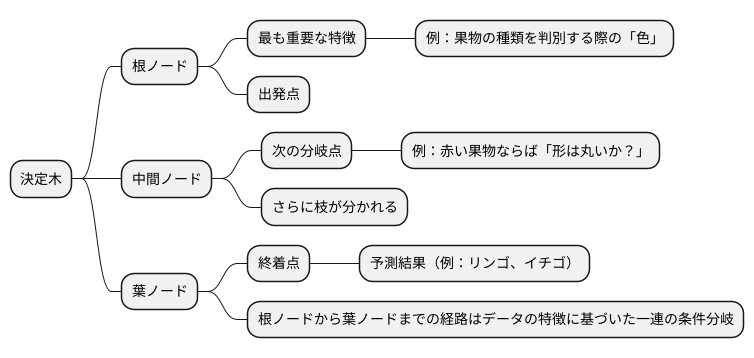
決定木は、多くの情報から規則性を見つけて予測を行う手法で、例えるなら宝の地図のようなものです。この地図は、様々な道しるべによって宝へと導いてくれます。決定木も同様に、データの特徴を手がかりに、段階的に答えを絞り込んでいきます。
まず、出発点を根ノードと呼びます。根ノードには、最も重要な特徴が置かれます。例えば、果物の種類を判別する場合、「色は何か?」が最初の分岐点となるかもしれません。赤、緑、黄色など、色の種類に応じて枝が分かれます。
次に、分岐した枝の先には、中間ノードと呼ばれる次の分岐点があります。ここでも、別の特徴に基づいてさらに枝が分かれます。例えば、赤い果物であれば、「形は丸いか?」という問いが次の分岐点になるかもしれません。丸い場合はリンゴ、そうでない場合はイチゴというように、さらに絞り込みが進んでいきます。
このように、分岐を繰り返すことで、最終的に葉ノードと呼ばれる終着点にたどり着きます。葉ノードには、予測結果が表示されます。例えば、「リンゴ」や「イチゴ」といった具体的な果物の名前が書かれています。つまり、根ノードから葉ノードまでの経路は、データの特徴に基づいた一連の条件分岐を表しており、その結果として最終的な予測が得られます。
このように、決定木は、複雑なデータを分かりやすく整理し、予測を行うための羅針盤のような役割を果たします。たくさんのデータの中から隠れた関係性を見つけ出し、将来の予測や判断に役立てることができます。まさに、データの迷宮を照らす灯台のような存在と言えるでしょう。
分岐の仕組み

決定木は、まるで枝分かれした木のような構造でデータを分類したり予測したりする方法です。この木をたどることで、最終的な結果にたどり着きます。その木の分かれ道を作る仕組みが、まさに分岐です。
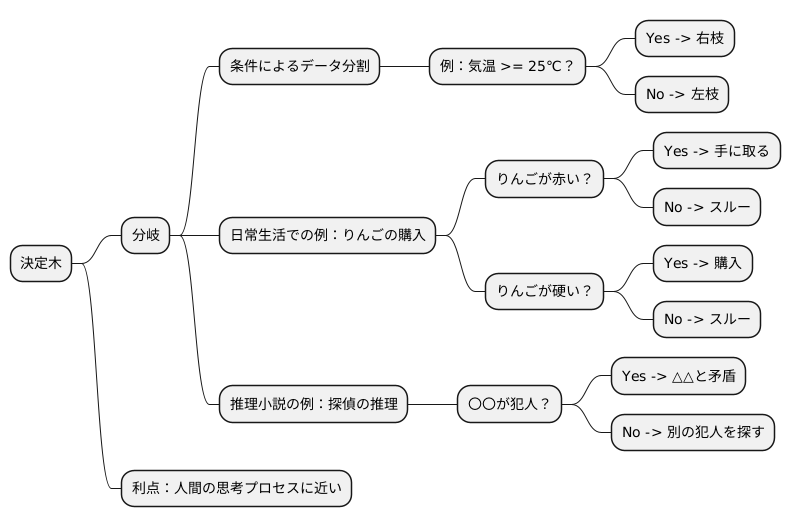
分岐は、データが持つ様々な特徴一つ一つに着目し、「もし~ならば」という形で条件を設定することで行われます。例として気温を考えましょう。「もし気温が25度以上ならば」という条件を設定した場合、気温が25度以上のデータは右の枝へ、25度未満のデータは左の枝へと振り分けられます。このように、各分岐点でデータの特徴に基づいた条件分岐を繰り返すことで、データは適切な葉(最終的な結果)へと導かれるのです。
この分岐の仕組みは、私たちの普段の考え方とよく似ています。例えば、りんごをスーパーで買うとしましょう。まず、りんごの色をチェックします。「もしりんごが赤いならば」手に取ってみます。次に、りんごの硬さを確認します。「もしりんごが硬いならば」買います。このように、私たちは無意識のうちに様々な条件で判断し、最終的な決定を下しています。決定木における分岐もこれと同じように、段階的にデータを絞り込んでいくことで、最終的な予測や分類を行います。
決定木の分岐は、推理小説の探偵が謎を解く過程によく似ています。探偵は、様々な手がかりに基づいて推理を進め、真実に迫っていきます。「もし〇〇が犯人ならば、△△という証拠と矛盾する」といったように、一つ一つの手がかりが分岐点となり、最終的な犯人特定へとつながります。決定木も同様に、データの特徴という手がかりを一つ一つ検証することで、最終的な結論、つまり予測結果へとたどり着くのです。このように、決定木は、人間の思考プロセスに近い方法で予測を行うため、その仕組みが理解しやすいという利点があります。
解釈の容易さ

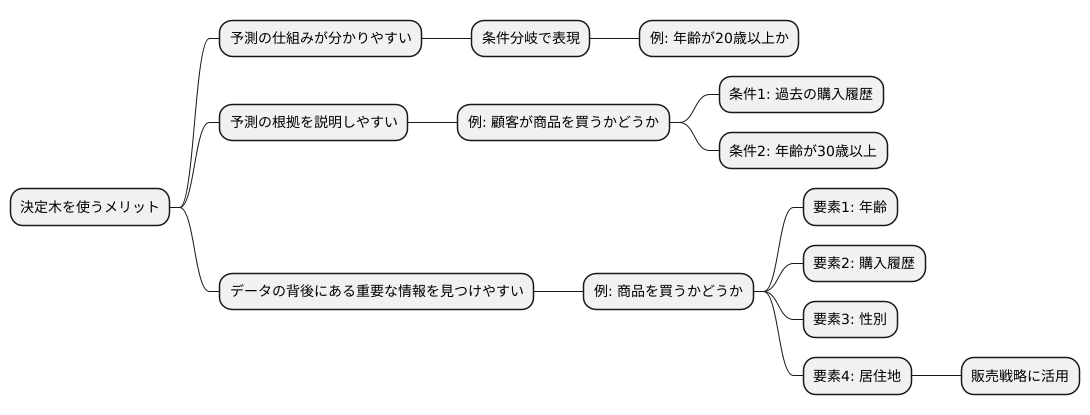
決定木を使う一番のメリットは、出来上がった予測の仕組みがとても分かりやすいことです。他の機械学習の方法では、予測の仕組みが複雑で分かりにくいことがよくありますが、決定木は違います。まるで樹木の枝のように、予測に至るまでの過程が条件分岐で示されます。それぞれの分岐は、例えば「年齢が20歳以上かそうでないか」といった簡単な条件で表されるため、誰でも理解しやすいのです。
この分かりやすさは、予測の根拠を説明する必要がある場面で特に重要になります。例えば、顧客が商品を買うかどうかを予測する場面を考えてみましょう。決定木を使うと、「過去の購入履歴があり、かつ年齢が30歳以上である顧客は商品を買う可能性が高い」といった予測結果が得られます。この結果を、なぜこの顧客が商品を買う可能性が高いのかという理由と共に説明することができます。これは、複雑な計算式で予測を行う他の方法では難しいことです。
さらに、決定木はデータの背後にある重要な情報を見つけ出すのにも役立ちます。商品を買うかどうかを予測する例で言えば、年齢や購入履歴以外にも、性別や居住地など様々な情報が影響を与えているかもしれません。決定木は、これらの情報の中から、予測に特に重要な情報を選び出し、分かりやすい形で示してくれます。どの情報が商品購入に大きな影響を与えているのかが分かれば、より効果的な販売戦略を立てることができます。例えば、過去の購入履歴が重要な要素だと分かれば、顧客一人ひとりの購入履歴に基づいたおすすめ商品を提示するといった戦略が考えられます。このように、決定木は予測だけでなく、データ分析を通して、より良い意思決定を支援してくれるのです。
応用例

決定木は、様々な場面で活用できる便利な道具として、多くの分野で役立っています。特に、医療診断やお金に関するリスクの評価、顧客の行動を調べる時など、色々な場面で使われています。
医療診断では、患者の様子や検査の結果から病気を診断する際に、決定木が役立ちます。例えば、熱があるかないか、咳が出るかどうかといった症状を木の枝のように分岐させていくことで、どの病気が疑われるかを絞り込んでいくことができます。これは、お医者さんが多くの情報を整理し、診断の手がかりを得るのに役立ちます。
お金に関するリスク評価では、お金を貸すかどうか、利息をどのくらいにするかなどを決める際に、決定木が使われます。例えば、過去の借り入れの状況や収入、仕事の内容などを基に、リスクの高さを判断します。これは、貸し倒れのリスクを減らすために重要な役割を果たします。
顧客の行動を調べる時にも、決定木は役立ちます。顧客が過去に何を買ったか、どんな商品をインターネットで見ているかといった情報から、顧客がどんな物を欲しがっているのか、どんなことに興味を持っているのかを調べることができます。この情報を利用することで、お店は顧客に合った商品を勧めることができます。また、新しい商品の開発にも役立ちます。
このように、決定木はデータに基づいて物事を判断するための強力な道具として、様々な分野で利用されています。今後も、ますます多くの分野で活用されていくことでしょう。
| 分野 | 決定木の活用例 |
|---|---|
| 医療診断 | 患者の症状(熱、咳など)や検査結果から病気を診断する。 |
| お金に関するリスク評価 | 借り入れ状況、収入、仕事内容などから貸し倒れリスクを判断し、融資の可否や利率を決定する。 |
| 顧客行動分析 | 過去の購買履歴やWeb閲覧履歴から顧客のニーズや興味を分析し、商品推薦や新商品開発に役立てる。 |
過学習への対処

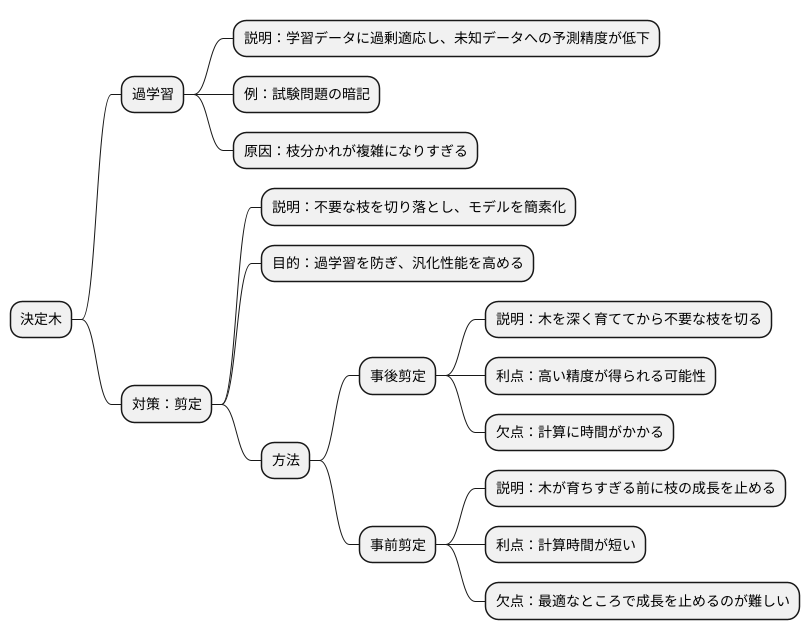
決定木は、学習に使ったデータに過剰に適応してしまう過学習という問題を起こしやすい性質があります。この過学習とは、学習データにぴったりと合いすぎてしまい、まだ知らないデータに対する予測の正しさが落ちてしまう現象です。例えるなら、試験勉強で過去の試験問題をただ暗記しただけで、実際の試験で初めて見る問題に対応できないようなものです。決定木では、枝分かれが複雑になりすぎることで過学習が起きやすくなります。
この問題への対策として、剪定という方法が使われます。剪定とは、不要な枝を切り落とすことで、模型を簡単にして、過学習を防ぐ方法です。庭師が木を剪定して美しい形に整えるように、データ分析でも剪定は模型をより良いものにするために欠かせません。適切な剪定を行うことで、模型の汎化性能を高めることができます。汎化性能とは、まだ知らないデータに対しても高い予測精度を保つ力のことで、剪定はこの汎化性能を高めるために重要な役割を果たします。
剪定には大きく分けて二つの方法があります。一つは、木を深く育ててから不要な枝を切る「事後剪定」です。もう一つは、木が育ちすぎる前に枝の成長を止める「事前剪定」です。どちらの方法にも利点と欠点があり、扱うデータや目的によって使い分けられます。例えば、事後剪定は計算に時間がかかる一方、事前剪定より高い精度が得られる可能性があります。反対に、事前剪定は計算時間が短いですが、最適なところで木の成長を止めるのが難しいという側面があります。このように、剪定は決定木の精度を保つための重要な作業であり、データ分析には欠かせない工程です。適切な剪定を行うことで、より精度の高い予測を可能にし、データ分析の効果を高めることができます。
他の手法との連携

決定木は、それ自体で予測モデルとして使われるだけでなく、他の機械学習の手法と組み合わせることで、より強力な分析ツールとなります。その代表例として、複数の決定木を組み合わせた「ランダムフォレスト」があります。ランダムフォレストは、多数の決定木を生成し、それぞれの予測結果を集約することで、最終的な予測を行います。例えるなら、専門家集団による会議のようなものです。一人の専門家の意見だけでは偏りが生じる可能性がありますが、複数の専門家の意見を総合的に判断すれば、より精度の高い結論に至ることができます。
ランダムフォレストも同様に、個々の決定木の予測のばらつきを抑え、全体として安定した予測を実現します。決定木は、学習データの特徴に合わせて枝分かれしていくため、データの些細な違いに過剰反応してしまうことがあります。これを「過学習」といいます。過学習が起きると、学習データにはよく適合しますが、未知のデータに対する予測精度が低下します。ランダムフォレストでは、複数の決定木を使うことで、この過学習の影響を軽減できます。それぞれの木が異なるデータで学習し、異なる構造を持つため、一つの木が過学習を起こしても、他の木がそれを補正する役割を果たすからです。
このように、ランダムフォレストは、決定木の持つ「解釈しやすい」という利点を保ちつつ、その弱点である「過学習しやすい」という点を克服しています。そのため、様々な分野で、高い予測精度と安定性が求められる場面で広く活用されています。さらに、決定木は、他の手法と組み合わせるための土台としても役立ちます。例えば、「勾配ブースティング」と呼ばれる手法では、決定木を弱学習器として用い、段階的に精度を高めていくことで、非常に高い予測性能を実現します。このように、決定木は単体での利用だけでなく、他の手法と連携することで、より高度なデータ分析を可能にする重要な要素となっています。
| 手法 | 説明 | 利点 | 欠点 | 対策 |
|---|---|---|---|---|
| 決定木 | データの特徴に合わせて枝分かれしていく予測モデル | 解釈しやすい | 過学習しやすい | ランダムフォレスト、勾配ブースティング |
| ランダムフォレスト | 複数の決定木を生成し、それぞれの予測結果を集約する | 過学習の影響を軽減、安定した予測 | ||
| 勾配ブースティング | 決定木を弱学習器として用い、段階的に精度を高める | 非常に高い予測性能 |