
データセットサイズとモデル性能

AIを知りたい
先生、「データセットのサイズ」って、大きいほどいいんですよね?でも、記事によると、データが足りなくなるかもしれないって書いてあるんですけど、どういうことですか?

AIエンジニア
そうだね、基本的にはデータセットは大きいほど、AIの性能は良くなる傾向にある。特に最近は、AIの規模を大きくすると性能が上がるという法則が見つかっているから、より多くのデータが必要になっているんだ。しかし、世界中で使えるデータの量は限られているため、AIの学習に使えるデータが足りなくなる可能性があると言われているんだよ。
AIを知りたい
なるほど。でも、インターネット上にはたくさんの情報があると思うんですが、それでも足りないんですか?
AIエンジニア
確かにインターネット上にはたくさんの情報があるけど、AIの学習に使えるように整理されたデータはそれほど多くないんだ。それに、AIの規模がどんどん大きくなっているから、データの増加よりもAIの学習に必要なデータの増加の方が速く、結果的にデータが足りなくなる可能性があるんだよ。特に日本語のデータは英語に比べて圧倒的に少ないから、高性能なAIを作るのが難しいんだ。
データセットのサイズとは。
人工知能に関する言葉である「学習データの量」について説明します。近年、大規模言語モデルは、規模を大きくすればするほど性能が上がるという法則に基づき、さらに巨大化が進んでいます。この法則によれば、学習データの量を増やすほど、モデルの性能が向上します。そのため、より多くのデータを収集することが重要になります。学習に使うデータは、コンピュータで扱える形式である必要があります。そのため、インターネット上のデータがよく使われます。しかし、学習データの増加の方が、インターネット上のデータの増加よりも速いため、将来的には学習データが不足すると予想されています。また、日本語のモデルを作る場合、学習データの量が英語と比べて圧倒的に少ないため、規模の大きなモデルを作る際に、学習データの量の観点から性能を向上させるのが難しいです。
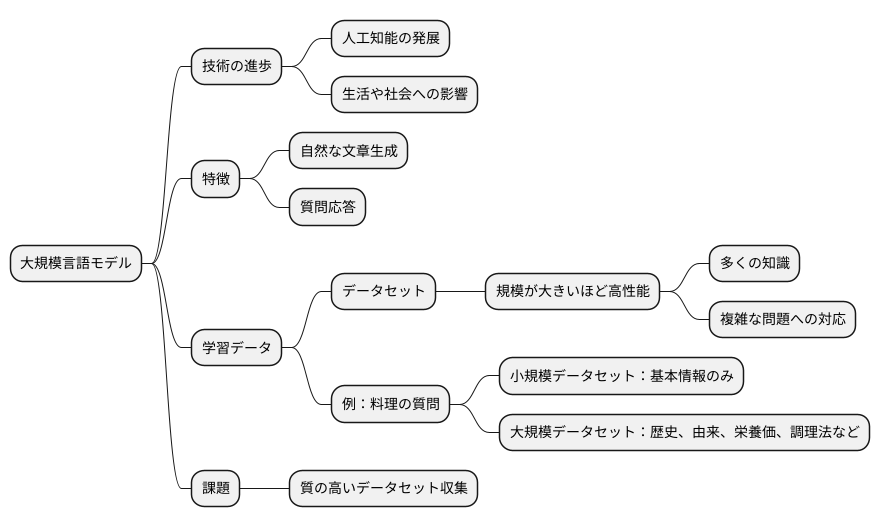
はじめに

近頃は、技術の進歩が目覚ましく、様々な分野で革新が起きています。中でも、人工知能の分野は目を見張るほどの発展を遂げており、私たちの生活や社会に大きな影響を与え始めています。この進歩の立役者と言えるのが、大規模言語モデルです。
大規模言語モデルとは、人間が書いた膨大な量の文章や会話、書籍などを学習させることで、まるで人間のように自然な文章を作り出したり、様々な質問に答えたりすることができる技術です。まるで人が書いたかのような文章を生成したり、難しい質問にも答えられるのは、学習データの量によるところが大きいのです。この学習データは「データセット」と呼ばれ、データセットの規模が大きければ大きいほど、モデルは多くのことを学び、より複雑な事柄も理解できるようになります。まるで人が多くの経験を積むことで賢くなるように、大規模言語モデルも多くのデータを学習することで賢くなるのです。
例えば、ある料理について質問したとします。小さなデータセットで学習したモデルは、基本的な情報しか知らないため、材料や作り方を簡単に説明するだけかもしれません。しかし、大きなデータセットで学習したモデルは、その料理の歴史や由来、栄養価、様々な調理方法、さらには地域ごとのバリエーションなど、より深く幅広い知識を提供することができます。つまり、データセットの規模は、モデルがどれだけ多くの知識を蓄え、どれだけ複雑な問題に対応できるかを左右する重要な要素なのです。そのため、大規模言語モデルの開発においては、質の高いデータセットをいかに多く集めるかが大きな課題となっています。このデータセットの規模こそが、大規模言語モデルの性能を大きく左右する鍵と言えるでしょう。
規模拡大の法則

規模拡大の法則は、近年の大規模言語模型の進歩を支える重要な考え方です。この法則は、模型の性能が、学習に使う資料の量、模型の大きさ(部品の数)、そして計算量の増加と共に高まることを示しています。言い換えれば、より多くの資料を与え、より多くの部品を持つ大きな模型を作り、より多くの計算資源を使うことで、模型はより賢くなるのです。
まず、学習に使う資料の量は、模型が学べる知識の量に直接関係します。まるで人が多くの本を読むことで多くの知識を得るように、模型も多くの資料から多くの知識を学び取ります。そのため、高性能な模型を作るためには、膨大な量の資料が必要です。
次に、模型の大きさは、模型がどれだけ複雑な情報を扱えるかを左右します。模型の部品一つ一つは、人間の脳細胞のように、情報を処理する役割を担っています。部品の数が増えるほど、模型はより複雑な情報処理が可能になり、より高度な課題をこなせるようになります。
最後に、計算量は、模型が学習に使える時間を決めます。多くの資料を学習し、複雑な計算を行うには、多くの時間が必要です。十分な計算資源を投入することで、模型はより多くの資料からより多くの知識を効率的に学ぶことができます。
近年の技術発展により、大規模な資料を集め、巨大な模型を動かすための計算資源が利用可能になりました。この規模拡大の法則に基づき、研究者たちは模型の規模を拡大し続け、より高度な課題をこなせる模型の開発に成功しています。今後、さらに大規模な模型が登場することで、人工知能はますます私たちの生活に役立つものになると期待されています。
学習データの源

言葉を操る人工知能、大規模言語モデルは、その賢さを磨くために莫大な量の学習データを必要とします。まるで人間がたくさんの本を読んで知識を蓄えるように、人工知能も大量の文章を読み込んで学習します。現状では、その学習データの大部分はインターネット上に公開されている情報、つまりウェブデータから得られています。ホームページや個人が発信するブログ記事、誰もが気軽に書き込むソーシャルメディアへの投稿など、インターネット上には様々な種類の文章データが溢れており、これらが人工知能の学習に役立てられています。しかし、人工知能の性能は学習データの量に大きく左右されるため、より高度な人工知能を開発するためには、これまで以上に大量の学習データが必要になります。ところが、人工知能の学習に必要なデータ量は増え続ける一方で、インターネット上のデータ量の増加ペースは追いついていません。このままでは、近い将来、人工知能の学習に使えるデータが不足する事態に陥る可能性があり、データ不足は人工知能の性能向上を妨げる大きな壁となることが懸念されています。人工知能がより賢く、より役に立つ存在になるためには、このデータ不足という問題を解決しなければなりません。そのためには、インターネット以外の新たなデータ源を探し出す必要があるでしょう。たとえば、書籍や新聞、論文など、従来からある出版物や、企業や研究機関が保有するデータなども貴重な情報源となり得ます。また、限られたデータから効率的に学習する方法を研究することも重要です。人工知能の未来は、学習データの確保にかかっていると言っても過言ではありません。人工知能がさらに進化し、私たちの生活をより豊かにしていくために、新たなデータ源の開拓と効率的なデータ活用方法の確立が急務となっています。
日本語データの課題

日本語を扱う大規模言語モデルの開発においては、学習に用いるデータの量が英語に比べてはるかに少ないことが大きな問題となっています。このデータ量の不足は、モデルの性能向上を阻む深刻な要因となっています。
近年の研究では、モデルの規模を大きくすることで性能が向上することが示されています(スケーリング則)。英語圏では、豊富なデータ量を背景に、大規模モデルの開発が活発に進められており、実際に高い性能を達成しています。しかし、日本語圏では、このスケーリング則を十分に活用することができていません。データ量が限られているため、モデルの規模を大きくしても、英語圏で見られるような劇的な性能向上は期待できないのです。
日本語のデータが少ない理由はいくつか考えられます。まず、日本語の書き言葉は、漢字、ひらがな、カタカナといった複数の文字体系を使用するため、データ処理の複雑さが増し、コストがかかります。また、日本語の文法は英語に比べて複雑であり、高品質なデータを作成するには、高度な言語処理技術が必要となります。さらに、著作権や個人情報保護などの観点から、日本語データの公開・共有が制限されている場合も少なくありません。
この状況を改善するためには、日本語データの収集と整備を積極的に進める必要があります。例えば、著作権に配慮したデータ収集方法の開発や、高品質なデータアノテーションのためのツールの開発などが重要です。また、研究機関や企業間でのデータ共有を促進するための枠組み作りも必要となるでしょう。これらの取り組みを通じて、日本語の大規模言語モデル開発を加速させ、日本語情報処理技術の進歩に貢献することが期待されます。
| 問題点 | 要因 | 解決策 |
|---|---|---|
| 日本語を扱う大規模言語モデルの開発において、学習データ量が不足している。 |
|
|
今後の展望

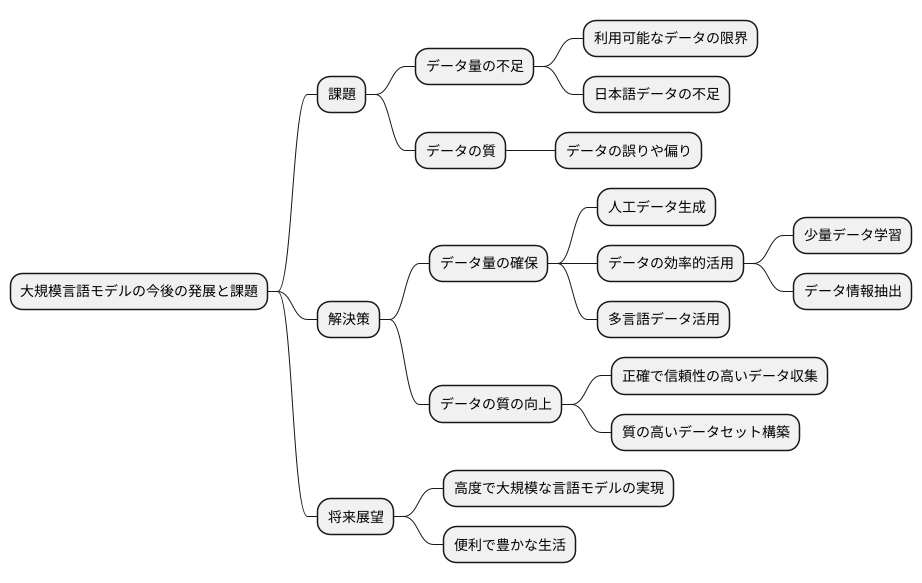
近年の技術革新により、大規模言語モデルは目覚ましい発展を遂げてきました。今後、更なる性能向上を目指す上で、学習データの規模拡大は避けて通れない重要な要素です。しかし、現状ではいくつかの課題に直面しています。例えば、インターネット上の利用可能なデータは限りがあり、既に多くのデータが活用されているため、新たなデータを獲得することが難しくなってきています。加えて、日本語のデータは英語などのデータと比較すると量的に不足しており、日本語に特化した高性能なモデル開発の足枷となっています。
これらの課題を解決するために、様々な取り組みが進行中です。まず、人工的にデータを生成する技術の研究が進められています。実在しない文章を大量に作り出すことで、データ不足を補う試みです。また、既に存在するデータをより効果的に活用する手法も研究されています。少量のデータからでも効率的に学習できるモデルの開発や、データの持つ情報を最大限に引き出す技術などが挙げられます。さらに、多言語のデータを活用する研究も盛んです。異なる言語のデータを組み合わせて学習させることで、各言語のモデル性能を向上させる効果が期待されています。
データの量だけでなく質の向上も重要な課題です。いくら大量のデータを集めても、データの内容に誤りや偏りがあれば、モデルの性能に悪影響を及ぼします。正確で信頼性の高いデータを集め、質の高いデータセットを構築することで、より高性能なモデルの開発が可能となります。これらの研究開発が進むことで、データ量の不足といった課題が克服され、より高度で大規模な言語モデルが実現すると期待されます。これにより、私たちの生活はより便利で豊かになるでしょう。
まとめ

近年の技術革新により、大規模言語モデルは目覚ましい発展を遂げてきました。この発展を支える大きな要因の一つが、学習に用いるデータセットの規模です。一般的に、データセットの規模が大きければ大きいほど、モデルはより多くの知識を習得し、複雑なタスクにも対応できるようになります。これを裏付けるものとして、データセットの規模とモデルの性能の関係性を示す「スケーリング則」と呼ばれる法則も提唱されています。この法則に従えば、データセットの規模を大きくすることで、モデルの性能は向上していくと考えられます。
しかし、大規模言語モデルの開発において、データセットに関するいくつかの課題も浮き彫りになってきています。一つは、インターネット上の利用可能なデータ、いわゆるウェブデータの枯渇です。モデルの学習には膨大なデータが必要となるため、既に利用可能なデータが不足してきているのです。特に、日本語は英語に比べて利用可能なデータが少ないため、日本語の大規模言語モデル開発においては、データ不足が深刻な問題となっています。また、データの質も重要な要素です。質の低いデータで学習させると、モデルの性能が低下する可能性があります。そのため、質の高いデータを効率的に収集、選別する技術の開発も重要な課題となっています。
これらの課題を克服するために、様々な研究開発が行われています。例えば、質の高いデータを自動生成する技術や、少ないデータでも効率的に学習できる手法の開発などが進められています。また、複数の言語のデータを組み合わせて学習させる多言語学習といったアプローチも注目されています。これらの技術革新により、データセットの規模や質に関する課題が解決され、今後さらに高度な大規模言語モデルが実現されることが期待されます。そして、これらの高性能なモデルは、機械翻訳、文章生成、質問応答システムなど、様々な分野で応用され、私たちの社会に大きな変革をもたらす可能性を秘めています。今後の更なる技術革新、そしてそれによってもたらされる社会への影響に、引き続き注目していく必要があるでしょう。
| 項目 | 内容 |
|---|---|
| 大規模言語モデルの発展 | 近年の技術革新により目覚ましい発展を遂げている。学習データセットの規模が大きな要因。 |
| スケーリング則 | データセットの規模とモデルの性能は比例する。 |
| データセットの課題 | ウェブデータの枯渇、データの質の確保。日本語データは特に不足。 |
| 課題への対策 | 質の高いデータ自動生成技術、少ないデータでの効率的学習手法、多言語学習。 |
| 今後の展望 | 更なる技術革新により高性能なモデルが実現され、様々な分野で応用、社会に大きな変革をもたらす可能性。 |