データセットの質:機械学習成功の鍵

AIを知りたい
先生、「データセットの質」って、結局どういうことですか? たくさんデータを集めればいいってもんじゃないんですよね?

AIエンジニア
そうだね。データは量だけでなく質も大切なんだ。質の悪いデータは、モデルの性能を悪くしてしまうこともある。たとえば、間違った情報や偏った情報を含むデータで学習すると、モデルも間違った答えを出したり、偏った考え方をしたりするようになるんだよ。
AIを知りたい
なるほど。じゃあ、具体的にどんなデータが「質が悪い」データなんですか?
AIエンジニア
いくつか例を挙げると、まず、明らかに間違った情報を含んでいるデータ。それから、特定の意見に偏っているデータ。その他にも、関係のない情報ばかりで必要な情報が少ないデータなどだね。このようなデータを取り除いたり、質の高いデータを選んで学習させることで、より良い結果が得られるんだよ。
データセットの質とは。
人工知能に関わる言葉で「学習用データの質」というものがあります。人工知能の性能を良くするには、学習用データの量を増やすことが大切だということは、既に知られています。しかし、データの量を増やせば必ず性能が上がるとは限りません。データの量と同時に、データの質も大切になります。質の悪いデータは、人工知能の性能を下げてしまう可能性があります。間違った情報を含むデータを使うと、人工知能が間違ったことを覚えてしまい、その結果、間違った予測や判断をしてしまうことになります。また、偏ったデータを使うと、人工知能が特定の集団や出来事に対して偏った考えを持つようになる可能性があります。さらに、雑音の多いデータを使うと、人工知能が重要な情報と関係のない情報を区別する能力が下がります。ですから、このような質の悪いデータを取り除いて、学習用データを作る必要があります。また、上記のような問題のあるデータ以外にも、性能に大きく影響するデータそうでないデータがあります。質の高いデータを選び、うまく処理することで、データ量の増加以上に性能が向上することもあります。
はじめに

機械学習は、まるで人間の学習と同じように、多くの情報を与えれば与えるほど賢くなります。この情報をデータセットと呼び、近年、データセットの規模を大きくすることで、機械学習モデルの性能が向上することが分かってきました。これは、まるで多くの経験を積んだ人が、より的確な判断を下せるようになるのと同じです。
データセットの規模が大きくなるほど、モデルは様々なパターンを学習できます。例えば、猫を認識するモデルを学習させる場合、たくさんの猫の画像データがあれば、様々な毛色や模様、ポーズの猫を認識できるようになります。結果として、初めて見る猫の画像でも、正確に猫だと判断できるようになるのです。これは、多くの猫を見てきた人が、少し変わった猫でも猫だと見分けられるのと同じです。
しかし、データの量が多ければ良いというわけではありません。学習に使うデータの質も非常に大切です。例えば、猫の画像データの中に犬の画像が混ざっていたり、画像がぼやけていたりすると、モデルは正しく学習できません。これは、間違った情報やあいまいな情報で学習すると、誤った判断をしてしまうのと同じです。
高品質なデータセットは、正確で関連性の高いデータで構成されています。猫の認識モデルであれば、鮮明な猫の画像だけが含まれているべきです。さらに、様々な種類の猫の画像が含まれていることで、モデルはより汎用的な能力を獲得できます。つまり、特定の種類の猫だけでなく、どんな猫でも認識できるようになるのです。
データセットの規模と質の両方が、機械学習モデルの性能向上に不可欠です。大量の質の高いデータで学習することで、モデルはより複雑なパターンを理解し、より正確な予測を行うことができます。これは、豊富な経験と正確な知識を持つ人が、より良い判断を下せるようになるのと同じです。今後、より高度な機械学習モデルを開発するためには、質の高いデータセットの構築がますます重要になってくるでしょう。
| 要素 | 説明 | 人間へのアナロジー |
|---|---|---|
| データセットの規模 | データが多いほど、様々なパターンを学習できる。 | 多くの経験を積むことで、的確な判断ができるようになる。 |
| データセットの質 | 正確で関連性の高いデータである必要がある。ノイズや誤ったデータは学習を妨げる。 | 間違った情報やあいまいな情報で学習すると、誤った判断をしてしまう。 |
| 高品質なデータセット | 鮮明で正確なデータ、様々なバリエーションを含むデータ。 | 豊富な経験と正確な知識。 |
| 規模と質の重要性 | 両方が重要。大量の質の高いデータが、高性能なモデルを実現する。 | 豊富な経験と正確な知識を持つ人が、より良い判断を下せるようになる。 |
質の低いデータとは

質の低いデータとは、機械学習モデルの学習に悪影響を与えるデータのことで、様々な種類があります。具体的にどのようなものか、詳しく見ていきましょう。
まず、内容に誤りがあるデータです。これは、数字の入力間違いや、事実とは異なる情報が含まれているデータのことです。このような誤ったデータを使って学習したモデルは、間違ったことを覚えてしまいます。例えば、りんごをみかんとラベル付けされた画像データを使って学習させた画像認識モデルは、りんごをみかんと誤認識してしまうでしょう。
次に、特定の属性に偏ったデータも質が低いと言えます。これは、ある一部分の特徴ばかりが強調され、全体像を正しく反映していないデータのことです。例えば、ある商品の購買データが特定の地域に偏っていると、他の地域での売れ行きを予測することが難しくなります。偏ったデータで学習したモデルは、特定の属性に対して過剰に反応したり、無視したりする可能性があり、結果として不公平な判断につながる恐れがあります。
さらに、雑音の多いデータも問題です。雑音とは、本来必要のない情報がデータに混ざっている状態のことです。例えば、音声データにノイズが混ざっていたり、画像データに関係のないものが写り込んでいたりする場合が該当します。雑音が多いと、モデルが重要な情報を見つけることが難しくなり、学習の効率が落ちてしまいます。まるで、たくさんの人で賑やかな場所で大事な話を聞き取ろうとするようなものです。
これらの質の低いデータは、モデルの精度を低下させるだけでなく、公平性や信頼性にも影響を与える可能性があります。そのため、質の高いデータを集め、必要に応じてデータの修正やクリーニングを行うことが重要です。
| 質の低いデータの種類 | 説明 | 例 | モデルへの影響 |
|---|---|---|---|
| 内容に誤りがあるデータ | 数字の入力間違いや、事実とは異なる情報が含まれているデータ | りんごをみかんとラベル付けされた画像データ | 間違ったことを学習し、誤認識する |
| 特定の属性に偏ったデータ | ある一部分の特徴ばかりが強調され、全体像を正しく反映していないデータ | 特定の地域に偏った商品の購買データ | 特定の属性に過剰反応したり、無視したりし、不公平な判断につながる |
| 雑音の多いデータ | 本来必要のない情報がデータに混ざっている状態 | ノイズが混ざった音声データ、関係のないものが写り込んだ画像データ | 重要な情報を見つけることが難しくなり、学習の効率が落ちる |
データの質が及ぼす悪影響

誤った情報に基づいた判断は、現実世界で様々な問題を引き起こします。機械学習の世界でも同じことが言えます。質の低いデータを使って学習した機械学習モデルは、まるで欠陥のある設計図をもとに建てられた建物のように、様々な問題を引き起こす可能性があります。
まず、質の低いデータは、モデルの予測精度を低下させます。不正確なデータや偏ったデータで学習したモデルは、現実を正しく反映しない予測結果を出力してしまいます。例えば、商品の売上予測モデルに欠損値が多いデータや古いデータを使えば、将来の売上を正確に予測することはできません。これは企業の経営判断に悪影響を及ぼし、大きな損失につながる可能性があります。
さらに、質の低いデータは、モデルの開発期間を長引かせ、コストを増加させます。データの修正や欠損値の補完、データの偏りを修正する作業には、多くの時間と労力が必要です。開発期間が長引くほど、人件費などのコストが増加し、プロジェクト全体の効率性を低下させます。
また、質の低いデータは、モデルの信頼性を損ないます。偏ったデータで学習したモデルは、特定の集団に対して不公平な結果をもたらす可能性があります。例えば、採用選考支援システムにおいて、過去の採用データに性差別的な偏りが含まれている場合、モデルもまた性差別的な判断を下す可能性があります。これは倫理的な問題を引き起こすだけでなく、企業の評判を大きく損なう可能性があります。
特に医療診断や自動運転といった人命に関わる分野では、データの質が非常に重要になります。誤った判断は深刻な結果につながる可能性があるため、高い精度と信頼性が求められます。そのため、機械学習プロジェクトを成功させるためには、データの質の確保が不可欠です。高品質なデータを集め、適切に前処理を行うことで、初めて信頼性の高い機械学習モデルを構築することができます。
| 問題点 | 説明 | 例 | 影響 |
|---|---|---|---|
| 予測精度の低下 | 不正確なデータや偏ったデータで学習したモデルは、現実を正しく反映しない予測結果を出力する。 | 商品の売上予測モデルに欠損値が多いデータや古いデータを使うと、将来の売上を正確に予測できない。 | 企業の経営判断への悪影響、大きな損失 |
| 開発期間の長期化とコスト増加 | データの修正や欠損値の補完、データの偏りを修正する作業には、多くの時間と労力が必要。 | – | 人件費などのコスト増加、プロジェクト全体の効率性低下 |
| モデルの信頼性損失 | 偏ったデータで学習したモデルは、特定の集団に対して不公平な結果をもたらす可能性がある。 | 採用選考支援システムにおいて、過去の採用データに性差別的な偏りが含まれている場合、モデルもまた性差別的な判断を下す可能性がある。 | 倫理的な問題、企業の評判損失 |
質の高いデータセットの構築

質の高い学習用情報を作ることは、人工知能開発の土台となる重要な作業です。良い学習用情報とは、単に量が多いだけでなく、正確で、偏りがなく、目的とする人工知能モデルの訓練に適したものである必要があります。それでは、具体的にどのようにして質の高い学習用情報を作ることができるのでしょうか。
まず、情報の集め方から慎重に行う必要があります。集め方、情報の出所、情報の特性などを明確に決めておくことで、後から情報の偏りや間違いに気づくことができます。例えば、特定の地域の人々からだけ情報を集めると、地域特有の偏りが生じる可能性があります。また、古い情報や信憑性の低い情報源から情報を集めると、情報の正確性が損なわれる可能性があります。情報の集め方を計画する段階で、このような問題点を予測し、対策を立てておくことが重要です。
次に、集めた情報の整理も欠かせません。情報の欠けている部分の処理、情報の重複を取り除く作業、間違っている情報の修正などを行い、情報の正確さを高める必要があります。例えば、住所の情報が欠けているデータがあれば、補完するか削除するかを判断する必要があります。また、同じ人物の情報が複数存在する場合は、一つにまとめる必要があります。このような整理作業によって、無駄な情報や誤った情報が取り除かれ、学習用情報の質が向上します。
さらに、集めた情報を人工知能モデルが理解しやすい形に変換する作業も重要です。数値の範囲を調整したり、情報を別の形式に変換したり、情報の重要な特徴を抜き出したりすることで、人工知能モデルが効率的に学習できるようになります。例えば、画像認識の人工知能モデルを訓練する場合、画像のサイズを統一したり、明るさやコントラストを調整したりする必要があります。また、自然言語処理の人工知能モデルを訓練する場合、文章を単語に分割したり、単語の出現頻度を数えたりする必要があります。このように、情報を適切に処理することで、人工知能モデルの性能を向上させることができます。
| ステップ | 内容 | 例 |
|---|---|---|
| 情報の収集 | 情報の出所、情報の特性などを明確にし、偏りや間違いのないように情報を集める。 | 特定の地域の人々からだけ情報を集めない。古い情報や信憑性の低い情報源から情報を集めない。 |
| 情報の整理 | 情報の欠損処理、重複除去、誤り修正などを行い、情報の正確さを高める。 | 住所の情報が欠けているデータを補完または削除する。同じ人物の情報を一つにまとめる。 |
| 情報の変換 | 人工知能モデルが理解しやすい形に情報を加工する。 | 画像認識:画像サイズの統一、明るさやコントラストの調整 自然言語処理:文章の単語分割、単語出現頻度の計算 |
データの選別

質の高い学習用資料を作るためには、資料を選ぶ作業がとても大切です。良い資料ばかりではなく、学習の邪魔になる資料も混ざっていることがあるからです。そのため、正しい基準で資料を選び、不要な資料を取り除く必要があります。
具体的には、大きく外れた値や邪魔な情報を取り除いたり、偏りを減らすなどの方法で資料の質を高めます。近頃注目されている「資料刈り込み」も有効な方法の一つです。資料刈り込みとは、学習に役立たない資料や、むしろ悪い影響を与える資料を見つけて、資料集から取り除く技術です。この技術を使うことで、資料集の大きさを小さくしながら、学習の効果を高めることができます。
例えば、画像認識の学習で、画像に写っている主要な物体とは関係のない背景部分や、ノイズの多い画像を削除することで、より正確な認識モデルを作ることができます。また、自然言語処理の学習では、文法的に誤っている文章や、特定の偏りを持つ文章を削除することで、より自然で公平な文章生成モデルを作ることができます。
適切な資料刈り込みを行うには、学習モデルの特徴や資料の性質を理解し、適切な方法を選ぶことが重要です。状況によっては、いくつかの方法を組み合わせることで、より効果的な資料刈り込みができる場合もあります。例えば、統計的な基準に基づいて外れ値を削除した後、専門家の知識に基づいてノイズの多いデータを削除するといった方法が考えられます。また、学習モデル自体に資料の重要度を評価させ、重要度の低い資料を削除するといった方法も研究されています。
資料刈り込みは、学習に使う計算資源を節約できるだけでなく、学習モデルの精度向上にも繋がるため、今後の学習用資料作成において不可欠な技術となるでしょう。
| 項目 | 説明 | 例 |
|---|---|---|
| 質の高い学習用資料作成 | 学習の邪魔になる資料を取り除き、正しい基準で資料を選び、質を高めることが重要 | – |
| 資料の質を高める方法 | 大きく外れた値や邪魔な情報を取り除く、偏りを減らす、資料刈り込み | – |
| 資料刈り込み | 学習に役立たない資料や、むしろ悪い影響を与える資料を見つけて、資料集から取り除く技術。資料集の大きさを小さくしながら、学習の効果を高める。 | – |
| 画像認識の例 | 背景部分やノイズの多い画像を削除し、より正確な認識モデルを作る | – |
| 自然言語処理の例 | 文法的に誤っている文章や、特定の偏りを持つ文章を削除し、より自然で公平な文章生成モデルを作る | – |
| 適切な資料刈り込みの方法 | 学習モデルの特徴や資料の性質を理解し、適切な方法を選ぶ。いくつかの方法を組み合わせることで、より効果的な資料刈り込みができる場合もある。 | 統計的な基準に基づいて外れ値を削除した後、専門家の知識に基づいてノイズの多いデータを削除する 学習モデル自体に資料の重要度を評価させ、重要度の低い資料を削除する |
| 資料刈り込みの効果 | 学習に使う計算資源を節約できるだけでなく、学習モデルの精度向上にも繋がる | – |
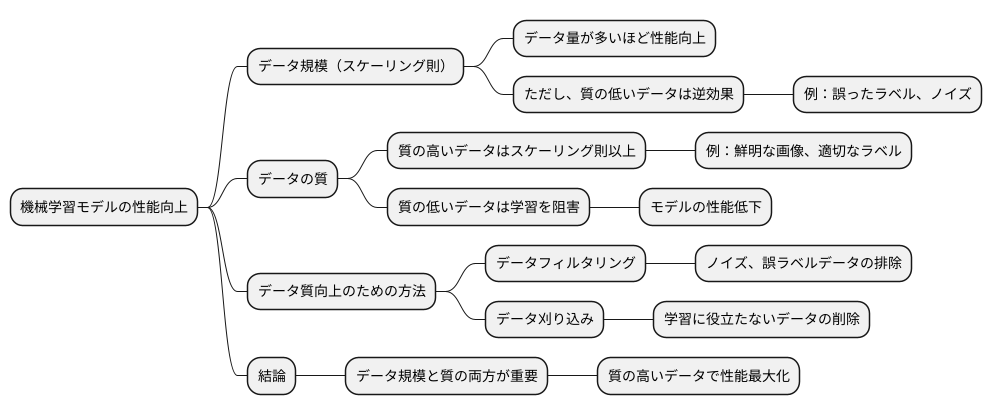
質の高いデータとスケーリング則

近年の機械学習モデル、特に大規模言語モデルにおいては、学習に用いるデータの規模がモデルの性能に大きな影響を与えることが広く知られています。これをスケーリング則と呼び、データ量を増やすほどモデルの性能が向上する傾向を示しています。しかし、闇雲にデータを増やせば良いというわけではなく、データの質も同様に重要です。
質の低いデータ、例えば誤ったラベル付けがされたデータやノイズの多いデータを増やしても、必ずしも性能が向上するとは限りません。このような質の低いデータは、モデルが学習すべき真の関係性を捉えることを妨げ、学習を間違った方向へ導いてしまう可能性があります。結果として、せっかく大量のデータを用いても、モデルの性能が向上しないどころか、かえって低下してしまうこともあり得ます。
一方で、質の高いデータを用いることで、スケーリング則で期待される以上の性能向上が見込めます。質の高いデータとは、モデルが学習したい事柄を正確に反映したデータです。例えば、画像認識タスクであれば、鮮明で適切にラベル付けされた画像データが質の高いデータと言えるでしょう。このような質の高いデータは、モデルがより効率的に学習することを可能にし、少ないデータ量でも高い性能を発揮できるようになります。
近年の研究では、データの質を向上させるための様々な手法が提案されています。例えば、データのフィルタリングは、ノイズの多いデータや誤ったラベルのデータを排除することで、データ全体の質を向上させる手法です。また、データ刈り込みは、学習に役立たないデータを特定し、削除することで、より効率的な学習を可能にします。これらの手法を用いてデータの質を向上させることで、スケーリング則を超える性能向上を達成した事例も報告されており、データの質がモデル性能向上に極めて重要であることが改めて示されています。
つまり、大規模なデータを用いることは重要ですが、同時にデータの質にも注意を払う必要があるのです。質の高いデータを集め、適切な前処理を行うことで、モデルの性能を最大限に引き出すことが可能になります。