
データ正規化と重み初期化

AIを知りたい
先生、「データの正規化」と「重みの初期化」って、AIの学習になぜ必要なのでしょうか? 例えば、賃貸の広さと築年数から家賃を推測する場合、具体的にどう関係するのでしょうか?

AIエンジニア
良い質問だね。賃貸の例で説明すると、広さは平方メートル、築年数は年数と単位が異なる。このままだと、広さの影響が大きくなりすぎて、築年数の影響が見えにくくなってしまうんだ。正規化は、それぞれの値を0から1の範囲に変換することで、単位の影響をなくし、両方の要素を平等に評価できるようにするんだ。
AIを知りたい
なるほど!単位が違うと、片方の要素が強すぎてしまうんですね。では、「重みの初期化」はどういう役割ですか?
AIエンジニア
重みは、広さや築年数が家賃にどれくらい影響するかを決める要素だ。初期値が偏っていると、例えば築年数だけが重要視され、広さが全く無視されるような状態になってしまう。重みの初期化は、特定の要素だけが強くならないように、バランス良く学習を始められるように準備することなんだよ。
データの正規化・重みの初期化とは。
人工知能で使われる言葉、「データの正規化」と「重みの初期化」について説明します。データの正規化とは、データを扱いやすくするために、全ての値を0から1の範囲に変換する前処理のことです。重みの初期化とは、学習を始める前に、偏りがないように、平均的な値になるようモデルの重みを調整することです。例えば、アパートの広さと築年数から家賃を予測する場合を考えてみましょう。「平方メートル」と「年数」のように、異なる単位が使われています。これらの単位の違いは、予測の精度を悪くするため、正規化によって0から1の範囲に統一します。また、重みは、はじめの値によっては、特定の部分が機能しなくなったり、逆に働きすぎたりといった悪い影響が出ることがあります。そのため、学習を始める前の準備として、重みの初期化を行います。
正規化の目的

機械学習のモデルを鍛える際に、入力データの値を整える正規化は欠かせない準備作業です。これは、様々な種類のデータの値を特定の範囲、例えば0から1の間に収める操作を指します。
正規化を行う一番の目的は、モデル学習の効率を高め、予測精度を向上させることです。もし、異なる範囲の値を持つデータがそのまま入力されると、値の範囲が大きいデータがモデルに過剰な影響を与え、値の範囲が小さいデータは無視されてしまう可能性があります。
例えば、家の値段を予測するモデルを考えてみましょう。このモデルに入力するデータとして、家の広さと築年数を使うとします。家の広さは数十から数百の値になり、築年数は数から数十の値になります。これらのデータをそのままモデルに入力すると、広さの値の方が築年数の値よりもはるかに大きいため、広さの情報ばかりが重視され、築年数の情報は軽視されるかもしれません。その結果、モデルは築年数の影響を十分に学習できず、予測精度が落ちてしまう可能性があります。
正規化は、このような問題を防ぐために役立ちます。正規化によって広さと築年数を同じ範囲の値に変換することで、モデルは両方の情報をバランス良く学習できます。家の広さは数百、築年数は数十というように、元々の値の範囲が大きく異なっていても、正規化によって例えばどちらも0から1の範囲に収まります。
このように、正規化はモデルが様々なデータの特徴を適切に捉え、偏りのない学習を行うために必要不可欠な手順です。これにより、モデルの学習は安定し、より正確な予測結果を得られるようになります。
| 正規化 | 説明 | メリット | 例 |
|---|---|---|---|
| 定義 | 様々な種類のデータの値を特定の範囲(例:0〜1)に収める操作 | モデル学習の効率化、予測精度の向上 | 家の価格予測モデル |
| 目的 | 値の範囲が大きいデータがモデルに過剰な影響を与えることを防ぎ、値の範囲が小さいデータが無視されることを防ぐ | モデルが様々なデータの特徴を適切に捉え、偏りのない学習を行う | 家の広さと築年数を同じ範囲の値に変換 |
| 例 | 家の広さ(数十〜数百)、築年数(数〜数十)を正規化し、0〜1の範囲に変換することで、モデルは両方の情報をバランス良く学習できる | モデルの学習が安定し、より正確な予測結果を得られる |
正規化の方法

情報を適切に扱うためには、値の範囲を調整する正規化という操作がしばしば必要となります。正規化には様々な方法があり、それぞれに特徴と使い分けがあります。ここでは代表的な正規化の方法とその注意点について説明します。
まず、最も基本的な方法として、最小値と最大値を利用した正規化があります。この方法は、データ全体の中で最も小さい値を0に、最も大きい値を1に変換します。そして、その他の値も0から1の範囲に比例変換します。この方法は計算が単純で分かりやすいという利点があります。しかし、データの中に極端に大きい値や小さい値(外れ値)が含まれている場合、この方法はうまく機能しません。なぜなら、外れ値に引っ張られて、他のデータの変換結果が0に近い値や1に近い値に集中してしまうからです。
外れ値の影響を抑えたい場合は、四分位範囲を用いた正規化(ロバストスケーリング)が有効です。この方法は、データを小さい順に並べたときに、全体の4分の1番目と4分の3番目の値を用いて正規化を行います。これらの値は、中央値に近い値のため、外れ値の影響を受けにくいという特徴があります。そのため、外れ値を含むデータに対してより安定した正規化を行うことができます。
また、平均値と標準偏差を用いた正規化(Zスコア正規化)もよく使われます。この方法は、データの平均値を0に、標準偏差を1に変換します。標準偏差とは、データのばらつき具合を示す値です。この方法は、データの分布形状を保ったまま正規化を行うことができるため、データの分析に適しています。
このように、正規化には複数の方法があり、データの特性や目的に応じて適切な方法を選ぶことが重要です。外れ値の有無やデータの分布形状などを考慮し、最適な正規化方法を選択することで、データの分析精度を高めたり、機械学習モデルの性能を向上させたりすることができます。
| 正規化方法 | 特徴 | 利点 | 欠点 |
|---|---|---|---|
| 最小値・最大値正規化 | 最小値を0、最大値を1に比例変換 | 計算が単純、分かりやすい | 外れ値の影響を受けやすい |
| 四分位範囲を用いた正規化(ロバストスケーリング) | データの25%点と75%点を利用 | 外れ値の影響を受けにくい | データの分布形状が変わる可能性がある |
| 平均値と標準偏差を用いた正規化(Zスコア正規化) | 平均値を0、標準偏差を1に変換 | データの分布形状を保つ | 外れ値の影響を完全に排除できない |
重み初期化の目的

人の学習と同様に、機械学習においても適切な初期設定は学習の効率と成果に大きく影響します。この初期設定の一つが、ニューラルネットワークにおける重みの初期化です。ニューラルネットワークは、人間の脳の神経回路を模倣した数理モデルであり、このモデルの中で、重みは神経細胞同士のつながりの強さを表す数値に相当します。学習開始時、これらの重みに適切な初期値を与えることで、学習の進み具合と最終的な精度を向上させることができます。
なぜ重みの初期化が重要なのでしょうか。もし全ての重みを同じ値で初期化してしまうと、どうなるでしょうか。これは、教室の全ての生徒が全く同じ考え方をして、同じ発言をするようなものです。多様な意見が出ず、議論は深まりません。ニューラルネットワークでも同様に、全ての重みが同じ値だと、全ての神経細胞が同じように反応し、学習が進みません。それぞれの神経細胞が異なる役割を担い、異なる特徴を学習することが重要なのです。適切な重みの初期化は、各神経細胞がそれぞれの個性を持つように促し、多様な特徴を捉えられるようにするのです。
例えば、画像認識を学習させる場合を考えてみましょう。適切に重みが初期化されていれば、ある神経細胞は画像の輪郭を、別の神経細胞は色を、また別の神経細胞は模様を認識するといったように、それぞれが異なる特徴を学習します。これらの特徴が統合されることで、最終的に画像全体の内容を理解できるようになります。しかし、もし重みが全て同じ値で初期化されていれば、全ての神経細胞が同じ特徴にしか反応できず、全体像を捉えることができません。結果として、精度の高い画像認識は実現できません。
このように、重みの初期化はニューラルネットワークの学習において非常に重要な要素です。適切な初期値を設定することで、学習の効率と精度を向上させ、より高度なタスクをこなせるモデルを構築することが可能になります。 適切な初期化方法は様々研究されており、学習データの特性やネットワークの構造に合わせて最適な方法を選択することが重要です。
| 項目 | 説明 |
|---|---|
| ニューラルネットワークにおける重みの初期化 | 学習開始時にニューラルネットワークの重みに適切な初期値を与えること。 |
| 重みの役割 | 神経細胞同士のつながりの強さを表す数値。学習の進み具合と最終的な精度に影響する。 |
| 重みを同じ値で初期化すると… | 全ての神経細胞が同じように反応し、学習が進まない。多様な特徴を学習できない。 |
| 適切な重みの初期化の効果 | 各神経細胞が異なる役割を担い、異なる特徴を学習できるようになる。 |
| 画像認識の例 | 適切な初期化:輪郭、色、模様など、異なる特徴を学習し、全体像を捉える。 不適切な初期化:同じ特徴にしか反応できず、全体像を捉えられない。 |
| 結論 | 重みの初期化は学習の効率と精度に大きく影響する。適切な初期化方法は、学習データの特性やネットワークの構造に合わせて選択する必要がある。 |
重み初期化の方法

機械学習のモデルにおいて、重みの初期値は学習の成否を大きく左右する重要な要素です。適切な初期値を設定することで、学習速度の向上や精度の改善につながります。逆に、不適切な初期値を設定すると、学習がうまく進まない、いわゆる勾配消失や勾配爆発といった問題を引き起こす可能性があります。
重みを初期化する方法には、様々な手法が存在します。その中でも、よく用いられるのが正規分布を用いた初期化です。正規分布とは、平均値を中心とした釣鐘型の分布で、この分布に従ってランダムに重みの値を決定します。正規分布を用いることで、重みの値にある程度のばらつきを持たせることができ、それぞれの部分が異なる特徴を学習できるようになります。
しかし、正規分布を用いる際に注意すべき点がいくつかあります。正規分布には、平均値と標準偏差という二つの重要な値があり、これらを適切に設定する必要があります。標準偏差は、分布の広がり具合を表す値です。標準偏差の設定値が大きすぎると、重みの値が極端に大きな値や小さな値になりやすくなります。これは、勾配爆発(学習中に勾配が異常に大きくなり、学習が不安定になる現象)もしくは勾配消失(学習中に勾配がほぼゼロになり、重みが更新されなくなる現象)といった問題につながる可能性があります。
標準偏差の設定は、使用する活性化関数によって適切な値が異なります。活性化関数とは、入力された値を特定の範囲に変換する関数のことです。例えば、シグモイド関数やReLU関数など、様々な活性化関数が存在し、それぞれ異なる特性を持っています。そのため、活性化関数の特性に合わせて標準偏差を調整する必要があります。
活性化関数の種類に応じて、適切な標準偏差を計算する手法も提案されています。代表的なものとして、Xavierの初期値やHeの初期値などがあります。これらの手法は、使用する活性化関数の特性を考慮して、勾配消失や勾配爆発を防ぐように設計されています。最適な初期化方法を選ぶことで、より効率的かつ効果的な学習を実現できます。
| 項目 | 説明 |
|---|---|
| 重みの初期値の重要性 | 学習の成否を左右する重要な要素。適切な初期値は学習速度向上、精度改善に貢献。不適切な初期値は勾配消失/爆発等の問題を引き起こす。 |
| 正規分布を用いた初期化 | 平均値を中心とした釣鐘型の分布に従い重みを決定。重みにばらつきを持たせ、異なる特徴の学習を可能にする。 |
| 正規分布の注意点 | 平均値と標準偏差を適切に設定する必要がある。標準偏差が大きすぎると、重みが極端な値になり、勾配爆発/消失につながる可能性がある。 |
| 標準偏差と活性化関数 | 標準偏差の適切な値は活性化関数に依存する。活性化関数の特性に合わせ標準偏差を調整する必要がある。 |
| 代表的な初期化手法 | Xavierの初期値、Heの初期値など。活性化関数の特性を考慮し、勾配消失/爆発を防ぐように設計されている。 |
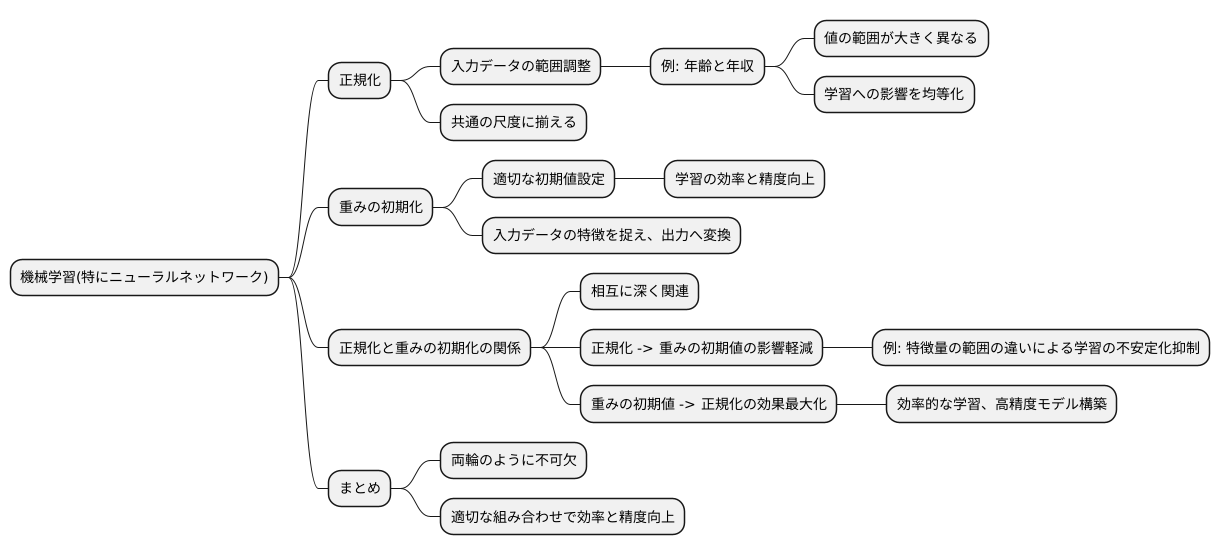
初期化と正規化の関係

機械学習の分野で、特にニューラルネットワークを扱う際には、データの初期化と正規化は切っても切り離せない重要な要素です。これらは、まるで車の両輪のように、共に学習の効率と精度を高めるために不可欠な存在です。
まず、正規化について考えてみましょう。正規化とは、入力データの範囲を調整する処理のことです。例えば、あるデータセットの中に、年齢や年収といった複数の情報が含まれているとします。年齢は数十、年収は数百万といったように、それぞれの値の範囲は大きく異なります。そのままでは、値の範囲が大きい情報が学習に過大な影響を与えてしまう可能性があります。そこで、正規化によって各情報を共通の尺度に揃えることで、それぞれの情報が均等に学習に貢献できるように調整するのです。
次に、重みの初期化について説明します。ニューラルネットワークは、入力データを受け取り、それを処理して出力する複雑な構造を持っています。この処理の過程で、重みと呼ばれるパラメータが重要な役割を果たします。重みは、入力データの特徴を捉え、出力へと変換する際に用いられる数値です。学習の初期段階では、この重みに適切な初期値を設定する必要があります。重みの初期値が適切でないと、学習がうまく進まない、あるいは望ましい結果が得られないといった問題が発生する可能性があります。
正規化と重みの初期化は、互いに深く関連しています。正規化によってデータの尺度を調整することで、重みの初期値の影響を軽減することができます。例えば、データが正規化されていない場合、特徴量の範囲の違いによって重みの更新に偏りが生じ、学習が不安定になる可能性があります。正規化を行うことで、このような偏りを抑え、安定した学習を実現することができます。また、重みの初期値を適切に設定することで、正規化の効果を最大限に引き出すこともできます。適切に初期化された重みは、正規化されたデータの特徴を効率的に学習し、より精度の高いモデルを構築することが期待されます。
このように、正規化と重みの初期化は、ニューラルネットワークの学習において、車の両輪のように不可欠な要素です。これらを適切に組み合わせ、調整することで、学習の効率を高め、より精度の高いモデルを構築することが可能となります。
実践的な活用

機械学習を実際に役立てる場面では、データの整え方と重みの決め方がとても大切です。この整え方と決め方を、それぞれデータの正規化と重みの初期化と呼びます。色々な作業で、この二つの技術が役立っています。
例えば、人の目で見て何が写っているかを機械に判断させる画像認識では、画像の色の濃さを数値で表したピクセル値を調整することで、学習の効率と正確さを高めることができます。色の濃さをそのまま使うのではなく、ある範囲の値に調整することで、機械がより早く正確に学習できるようになります。
また、人間が話す言葉を機械に理解させる自然言語処理では、単語がどのくらい使われているかを数値化し、調整することで、単語の重要度を機械が正しく学習できるようになります。よく使われる単語とあまり使われない単語を同じように扱うのではなく、使われている頻度に応じて調整することで、機械はより人間の言葉に近い形で理解できるようになります。
さらに、人間の声を機械に文字に変換させる音声認識では、声の大きさを調整することで、周りの雑音の影響を減らすことができます。声の大きさを一定の範囲に調整することで、機械は雑音に惑わされずに、より正確に声を文字に変換できるようになります。
このように、画像認識、自然言語処理、音声認識など、様々な場面でデータの正規化と重みの初期化は欠かせない技術となっています。
データの正規化と重みの初期化には色々な方法があり、作業の内容に合わせて適切な方法を選ぶことで、より良い結果を得ることができます。そのため、これらの技術について深く理解し、うまく使いこなすことが、機械学習を実際に役立てる上で重要です。
| 分野 | データの正規化 | 目的 |
|---|---|---|
| 画像認識 | ピクセル値の調整 | 学習の効率と正確さの向上 |
| 自然言語処理 | 単語の使用頻度の数値化と調整 | 単語の重要度の正確な学習 |
| 音声認識 | 声の大きさの調整 | 雑音の影響の軽減 |