
データ拡張:画像認識精度を高める技術

AIを知りたい
『いろいろなデータ拡張』って、画像をちょっと変えるってことですよね?上下とか左右に動かしたり、ひっくり返したり、大きくしたり小さくしたり…回転させたりとか。

AIエンジニア
そうそう、その通りです。画像を少しだけ変化させることで、新しい画像データを作っているのと同じ効果を生み出しているんです。これをデータ拡張と言います。
AIを知りたい
でも、なんでわざわざそんなことをするんですか? 元の画像があれば十分じゃないんですか?
AIエンジニア
いい質問ですね。AIに物体を正しく認識させるには、いろいろなバリエーションの画像データが必要なんです。例えば、猫を認識させたいとき、色々な角度から見た猫の画像、色々な種類の猫の画像をたくさん学習させることで、AIは『猫らしさ』を理解します。でも、あらゆるパターンの画像を用意するのは現実的に難しい。だから、少ない画像データから人工的にバリエーションを増やすためにデータ拡張を行うんです。
各種データ拡張とは。
人工知能でよく使われる『データを増やすための様々な方法』について説明します。データを増やすとは、手元にある画像を加工して、見かけは違うけれど実際には同じものとして扱える画像データをたくさん作ることです。ものを正しく認識させるためには、あらゆる場合を想定したたくさんのデータが必要です。しかし、実際にそのような画像データをすべて用意するのはほぼ不可能です。そこで、データを増やす方法が役に立ちます。簡単な例としては、画像を上下左右に動かしたり、上下左右をひっくり返したり、大きくしたり小さくしたり、回転させたりすることなどが挙げられます。
データ拡張とは

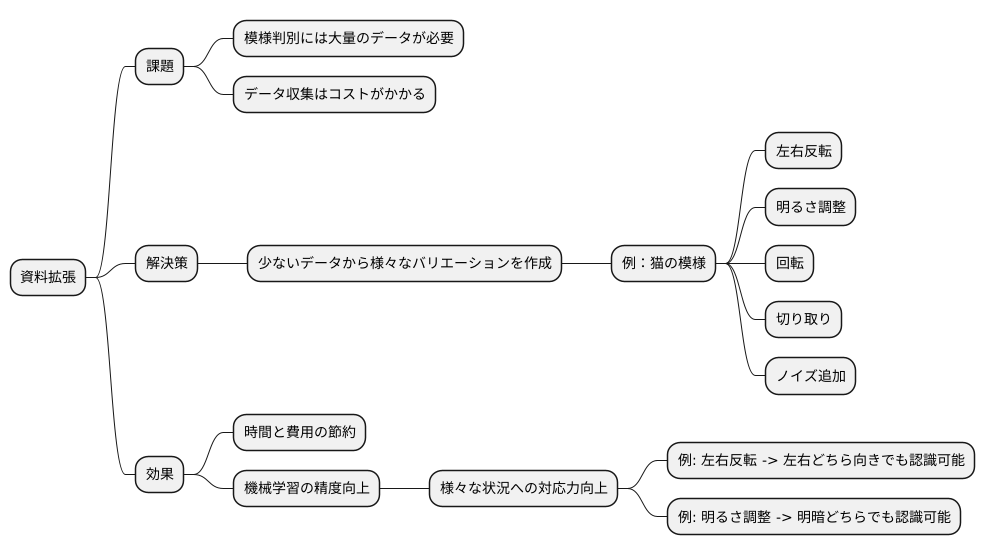
模様判別を機械に学習させるためには、たくさんの絵柄データが必要です。しかし、実世界で起こりうるすべての場合を網羅した資料を集めるのは、時間もお金もかかって大変です。そこで役立つのが、資料拡張という技術です。これは、少ない資料をもとに、様々な模様の変化を作り出す技術です。
たとえば、猫の模様を機械に覚えさせたいとします。普通に考えれば、色々な種類の猫の写真をたくさん集める必要があります。しかし、資料拡張を使えば、一枚の猫の写真から、色々なバリエーションを作り出すことができます。たとえば、写真を左右反転させたり、明るさを変えたり、少し回転させたりすることで、実際には存在しない猫の写真を人工的に作り出すことができます。また、写真の一部を切り取ったり、ノイズを加えたりすることで、機械学習に役立つ様々なバリエーションを作成できます。
このように、資料拡張は、少ない元データから多くの模様データを作り出すことができるため、時間と費用を大幅に節約できます。さらに、機械学習の精度を高める効果もあります。たとえば、左右反転させた猫の写真で学習することで、機械は左右どちらを向いていても猫を認識できるようになります。明るさを変えた写真で学習すれば、暗い場所や明るい場所でも猫を認識できるようになります。このように、資料拡張は、機械が様々な状況に対応できる能力を高める上で重要な役割を果たします。これは、まるで限られた材料から様々な料理を作り出すように、データという素材の可能性を広げる技術と言えるでしょう。
データ拡張のメリット

機械学習モデルを作る上で、データ拡張は非常に有効な手法です。その最大の利点は、過学習の抑制とモデルの汎化性能向上です。過学習とは、まるで試験勉強で教科書の内容を丸暗記したものの、少し問題文が変わると途端に解けなくなってしまう状態です。モデルが学習データの特徴を細部まで覚え込みすぎて、未知のデータへの対応力が失われてしまう現象です。
データ拡張は、この過学習を防ぐ効果があります。元のデータに様々な変換を加えることで、擬似的に大量のデータを作成します。例えば、画像データであれば、回転、拡大縮小、色の変更などを行い、多様なバリエーションを生み出します。これにより、モデルは特定のデータの特徴に固執することなく、本質的な特徴を学習できます。
データ拡張は、まるで様々な問題に触れることで応用力が身につく学習方法のようです。多様なデータで学習したモデルは、初めて見るデータに対しても、高い精度で予測や分類を行うことができます。これは、未知の状況への対応力、すなわち汎化性能の向上を意味します。
さらに、データ拡張には時間と費用の削減という大きな利点もあります。一般的に、機械学習に使用するデータ収集は多くの時間と費用を必要とします。しかし、データ拡張はコンピュータ処理で自動的に行うことができるため、実データを集める手間を大幅に省き、効率的に学習データを増やすことができます。これは、限られた資源で高性能なモデル開発を目指す上で、非常に重要な要素です。
| 利点 | 説明 | 例 |
|---|---|---|
| 過学習の抑制 | モデルが学習データの特徴を細部まで覚え込みすぎて、未知のデータへの対応力が失われてしまう現象を防ぐ。 | 試験勉強で教科書の内容を丸暗記したものの、少し問題文が変わると途端に解けなくなってしまう状態 |
| モデルの汎化性能向上 | 様々な問題に触れることで応用力が身につく学習方法のように、多様なデータで学習することで、初めて見るデータに対しても、高い精度で予測や分類を行う。 | – |
| 時間と費用の削減 | コンピュータ処理で自動的にデータを増やすことができるため、実データを集める手間を大幅に省き、効率的に学習データを増やす。 | 画像データであれば、回転、拡大縮小、色の変更など |
データ拡張の方法

情報の量を増やす方法はいろいろあります。画像を扱う場合、基本的な方法として、画像を横にずらしたり、上下ひっくり返したり、回転させたり、大きくしたり小さくしたりといったことが考えられます。これらの方法は、画像の置かれる場所や大きさ、向きを変えることで、様々なバリエーションを生み出します。例えば、猫の写真を左右反転させると、反対側から見たような写真が得られます。少し回転させれば、猫が少し体を傾けたような写真になります。このように、同じ猫でも様々な角度や姿勢の写真を作ることができます。つまり、少し手を加えるだけで多くのバリエーションが作れるということです。
また、画像全体の明るさや鮮やかさ、色の濃淡を調整するのも良い方法です。これらの調整は、写真の雰囲気を変えることで、様々な照明条件や撮影時の状況を再現できます。例えば、明るさを落とせば、夕方や夜に撮影したような雰囲気になりますし、鮮やかさを上げれば、晴れた日に撮影したような明るい雰囲気になります。
さらに、高度な方法として、画像の一部を隠したり、わざとノイズを加えるという方法もあります。一部を隠すことで、一部が隠れた状態での認識能力を向上させることができます。また、ノイズを加えることで、実際の撮影時に発生するノイズへの耐性を高めることができます。これらの高度な方法は、目的に合わせて使い分けることで、より効果的に情報の量を増やすことができます。どの方法を選ぶかは、どのような情報を増やしたいか、どのような目的で情報を増やすかによって異なります。目的に合った方法を選ぶことで、より良い結果を得ることができます。
| 方法 | 操作 | 効果 | 種類 |
|---|---|---|---|
| 基本的な方法 | 横にずらす | 画像の置かれる場所を変える | 画像の位置、大きさ、向き変更 |
| 上下ひっくり返す | 画像の向きを変える | ||
| 回転させる | 画像の向きを変える | ||
| 拡大/縮小 | 画像の大きさを変える | ||
| 画像の調整 | 明るさ調整 | 写真の雰囲気を変える、照明条件を再現 | 画質調整 |
| 鮮やかさ調整 | 写真の雰囲気を変える、撮影時の状況を再現 | ||
| 色の濃淡調整 | 写真の雰囲気を変える | ||
| 高度な方法 | 一部を隠す | 一部が隠れた状態での認識能力向上 | データ拡張 |
| ノイズを加える | ノイズへの耐性向上 |
適用事例

画像を加工してデータを増やす技術は、様々な分野で役に立っています。この技術のおかげで、少ないデータでも人工知能をうまく学習させることができるようになりました。
例えば、医療の分野では、レントゲン写真やCT画像から病気を見つけるのに役立っています。珍しい病気の場合、学習に使える画像データが少ないことがあります。しかし、この技術を使えば、少ない画像データからでも、病気を正確に見つける人工知能を作ることができます。例えば、画像を回転させたり、明るさを変えたりすることで、元々の画像とは少し違う画像をたくさん作ることができます。こうして増やした画像データを使って人工知能を学習させることで、様々なバリエーションの画像に対応できるようになり、診断の精度が向上します。
自動運転の分野でも、この技術は重要な役割を果たしています。安全な自動運転システムを作るためには、様々な道路状況や天気の画像データを人工知能に学習させる必要があります。しかし、現実世界で全ての状況のデータを収集するのは困難です。そこで、この技術を使って、晴れの日の画像から雨の日の画像を作ったり、昼の画像から夜の画像を作ったりすることで、人工知能の学習に必要なデータを効率的に増やすことができます。これにより、様々な状況に対応できる、より安全な自動運転システムの開発が可能になります。
製造業では、製品の検査にこの技術が使われています。不良品を見つける人工知能を作るには、様々な不良品の画像データが必要です。しかし、不良品は少ない方が良いので、大量の不良品データを集めるのは難しいです。そこで、この技術を使って、少ない不良品の画像データから様々なパターンの不良品画像を作り出し、人工知能を学習させることができます。こうして、少ないデータでも高い精度で不良品を見つけられる人工知能を開発することができます。
このように、画像を加工してデータを増やす技術は、様々な分野で役立っており、今後もさらに活躍の場が広がっていくでしょう。
| 分野 | 課題 | データ増強技術の活用例 | 効果 |
|---|---|---|---|
| 医療 | 珍しい病気の画像データ不足 | レントゲン写真やCT画像の回転、明るさ変更 | 診断精度の向上 |
| 自動運転 | 様々な道路状況や天気の画像データ収集の困難さ | 晴れの日の画像から雨の日の画像生成、昼の画像から夜の画像生成 | 様々な状況に対応できる安全な自動運転システムの開発 |
| 製造業 | 不良品画像データの不足 | 少ない不良品画像データから様々なパターンの不良品画像生成 | 高精度な不良品検出AIの開発 |
今後の展望

今後のデータ拡張技術は、人工知能技術の進歩をさらに推し進める力となるでしょう。深層学習の進化とともに発展を続けるデータ拡張は、より高度で精巧な技術へと進化しています。
近年注目を集めているのが、敵対的生成ネットワーク、いわゆる「偽物を作る仕組み」と「偽物を見分ける仕組み」を競わせる方法です。この方法では、偽物を作る部分が本物と見分けがつかないほど精巧なデータを作り出すことを目指します。この技術をデータ拡張に用いることで、従来の方法では難しかった複雑な変化や組み合わせも可能になり、より効果的な学習データの生成につながります。例えば、限られた数の画像データから、様々な角度や明るさ、背景などの変化を加えた大量の画像データを生成することで、人工知能モデルの認識精度向上に貢献します。
また、データ拡張技術の自動化も進んでいます。これまで、データの種類や特性に合わせて、適切なデータ拡張方法を選ぶ必要がありました。しかし、最適な方法を自動的に選択する仕組みが開発されたことで、手間や専門知識がなくても、効果的なデータ拡張が可能になります。
これらの技術革新は、人工知能がより少ないデータからでも効率的に学習することを可能にし、様々な分野での応用が期待されます。医療画像診断の精度向上や自動運転技術の安全性向上など、幅広い分野で人工知能の活躍を支える重要な技術となるでしょう。今後もデータ拡張技術は高度化・自動化を進め、人工知能の発展を加速させていくと予想されます。
| データ拡張技術の進化 | 内容 | 効果 |
|---|---|---|
| 敵対的生成ネットワーク (GAN) の活用 | 「偽物を作る仕組み」と「偽物を見分ける仕組み」を競わせることで、本物と見分けがつかない精巧なデータを生成。 | 複雑な変化や組み合わせが可能になり、より効果的な学習データ生成。例:限られた画像データから多様なバリエーションの画像データを生成し、AIモデルの認識精度向上。 |
| データ拡張の自動化 | データの種類や特性に合わせて最適なデータ拡張方法を自動的に選択。 | 手間や専門知識がなくても効果的なデータ拡張が可能。 |