
学習データの適切な取捨選択

AIを知りたい
先生、「学習データのカットオフ」ってどういう意味ですか?

AIエンジニア
簡単に言うと、AIの学習に使うデータの一部をわざと使わないようにすることだよ。例えるなら、料理で例えると、腐った野菜を取り除いて、新鮮な野菜だけを使うようなイメージだね。
AIを知りたい
なるほど。どうしてわざとデータを使わないようにするんですか?
AIエンジニア
古い情報や、関係のない情報がAIの学習を邪魔してしまうのを防ぐためだよ。例えば、昔の流行語をAIに覚えさせても、今の会話では役に立たないよね?そういう不要な情報を除くことで、AIの性能を上げることができるんだ。
学習データのカットオフとは。
人工知能を作る際に使う言葉で「学習データの切り捨て」というものがあります。これは、様々な理由で、人工知能に覚えさせるデータの一部をわざと使わないようにすることを指します。例えば、時間の流れに沿って変わるデータを使う場合は、古すぎる情報を覚えさせないように、昔のデータを一部使わないようにすることがあります。他にも、ある特定の条件に合うデータだけを覚えさせたい場合は、その条件に合わないデータを切り捨てることがあります。
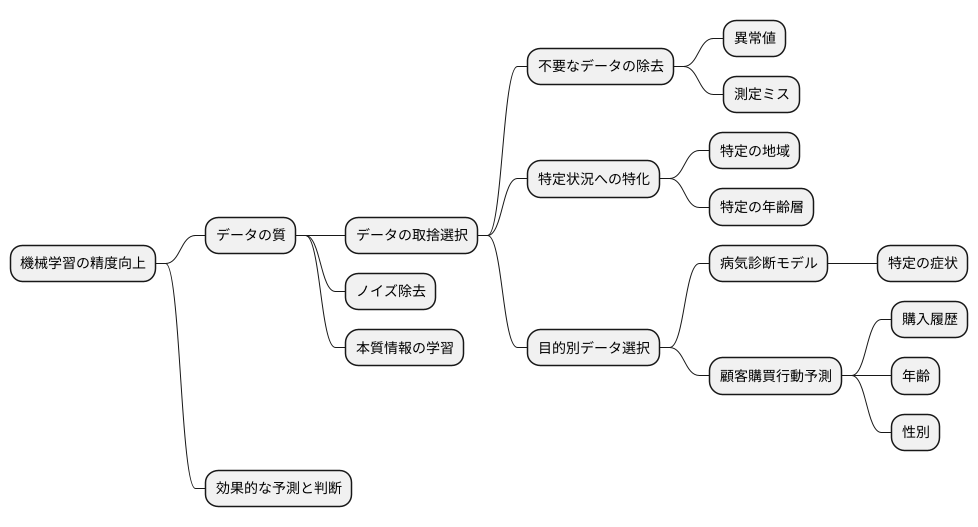
データの取捨選択とは

機械学習の精度は、学習に使うデータの質に大きく左右されます。そのため、ただ大量のデータを集めるだけでなく、その中から必要なデータを選び、不要なデータを取り除く作業が重要になります。これをデータの取捨選択と言います。集めたデータすべてをそのまま学習に使うと、質の低いデータや偏ったデータの影響で、望ましい結果が得られないことがあります。
データの取捨選択には、様々な方法があります。例えば、ある特定の値より大きい、あるいは小さいデータを削除するといった単純な方法があります。これは、明らかに異常な値や測定ミスによるデータを除外するのに役立ちます。また、ある範囲外のデータを取り除くことで、特定の状況に特化した学習を行うことも可能です。例えば、特定の地域や年齢層のデータに絞って学習させることで、その地域や年齢層に最適化された結果を得ることができます。
データの取捨選択の基準は、学習の目的やデータの内容によって変化します。例えば、病気の診断モデルを作る場合、特定の症状を持つ患者のデータのみを選択することで、その病気の診断精度を高めることができます。一方、顧客の購買行動を予測するモデルを作る場合、過去の購入履歴や年齢、性別などのデータを選択することが重要になります。
適切なデータの取捨選択は、高精度なモデルの構築に不可欠です。不要なデータを取り除くことで、モデルがノイズに惑わされず、本質的な情報を学習することができます。また、特定の状況に合わせたデータを選択することで、より効果的な予測や判断が可能になります。データの取捨選択は、時間と手間のかかる作業ですが、最終的なモデルの性能を大きく向上させるため、非常に重要な作業と言えます。
時間経過によるデータの取捨選択

時系列の情報を扱う場合、時間の流れと共に情報の特徴が変わるということがよくあります。例えば、人々の買い物傾向や株式の値動きは、世の中の動きやお金の流れに影響されて、時間の流れと共に大きく変わることがあります。
ある商品の流行を例に考えてみましょう。以前は人気があった商品でも、新しい商品が登場したり、人々の好みが変わったりすることで、次第に売れなくなっていくことがあります。このような状況で、過去の売れ行き情報だけを使って将来の需要を予測すると、実際よりも多く見積もってしまう可能性があります。これは、過去の情報が必ずしも未来を予測するのに役立つとは限らないからです。
同様に、株価も社会の出来事や会社の業績によって大きく変動します。過去の株価の情報だけを基に未来の株価を予測しようとしても、最新の状況を反映していないため、正確な予測は難しいでしょう。
そこで、ある時点より前の情報を切り捨てるという方法が有効になります。古い情報を除外することで、より最近の流行や傾向を捉えた予測モデルを作ることができます。具体的には、過去一年間のデータのみを利用したり、特定の大きな出来事以降のデータのみを利用したりすることで、より精度の高い予測が可能になります。
これは、変化の激しい市場や状況に対応するために非常に大切な考え方です。常に最新の情報を重視し、古い情報に固執しないことで、より的確な判断と予測を行うことができるようになります。
| 問題点 | 具体例 | 解決策 | 効果 |
|---|---|---|---|
| 過去の情報に基づく予測は、時間の経過とともに変化する情報の特徴を捉えられない。 | 過去の売れ筋商品データで将来の需要予測を行うと、過大評価になる可能性がある。 過去の株価データのみで将来の株価を予測するのは困難。 |
ある時点より前の情報を切り捨てる。 | より最近の傾向を捉えた予測モデル作成が可能になる。 特定の期間や出来事以降のデータのみを使うことで、予測精度が向上する。 |
特定条件によるデータの取捨選択

データの中から必要な情報だけを選び出し、不要な情報を捨てる作業は、質の高い予測モデルを作る上で欠かせません。まるで、宝石を作る職人が原石から不要な部分を削り落として美しい宝石を磨き上げるように、データも丁寧に取捨選択することで、その真価を発揮します。データの取捨選択は、特定の条件に基づいて行います。例えば、新しいお店の出店場所を決めるために、ある街の住民の購買データを分析するとします。この時、分析の目的がその街への出店かどうかによって、データの範囲が変わってきます。もし、その街に特化したお店を作るのであれば、その街の住民データのみを分析対象とするべきです。他の街のデータは、その街特有の消費傾向を捉える上で邪魔になる可能性があります。逆に、全国展開を視野に入れたお店を作るなら、全国のデータを分析対象とする方が良いでしょう。
データの取捨選択のもう一つの重要な側面は、異常値や雑音となるデータの除去です。データの中には、何らかの間違いで極端に大きな値や小さな値が入っている場合があります。また、測定機器の誤作動などで本来の値とは異なる値が記録されていることもあります。これらの異常値や雑音は、モデルの精度を低下させる原因となります。例えば、ある製品の売上予測モデルを作る際に、過去の売上に異常値が含まれていると、将来の売上予測も不正確なものになってしまいます。このような異常値や雑音は、慎重に取り除く必要があります。データの取捨選択は、モデルの目的に合った適切なデータのみを利用し、質の高い予測結果を得るための重要な作業と言えるでしょう。
データの取捨選択の注意点

情報を適切に扱うには、どの情報を使うか、どの情報を使わないかを決める作業が欠かせません。このデータの取捨選択は、結果に大きな影響を与えるため、慎重に行う必要があります。どのような理由で情報を切り捨てるのか、どの程度の情報を捨てるのかは、目的や情報の種類をしっかり考えて決める必要があります。
例えば、ある商品の売れ行きを予測するモデルを作る場合を考えてみましょう。過去の販売データを使う際に、過去の景気や天候といった情報も一緒に使いたいと思うかもしれません。しかし、もし予測したい期間が短ければ、長期的な景気の変動はあまり関係ないかもしれません。逆に、予測期間が長ければ、景気の変動は重要な要素となるでしょう。このように、予測する期間の長さによって、使うべき情報が変わってくるのです。
また、情報の質にも注意が必要です。集めた情報に誤りが含まれていると、正しい結果を得ることができません。例えば、商品の価格を入力ミスしていて、実際の価格よりもはるかに高い値が入力されているとします。この間違った情報を使ってモデルを作ると、売れ行きを過小評価してしまう可能性があります。情報の正確さを確認し、間違っている情報は修正するか、捨てる必要があるのです。
さらに、不用意に情報を捨ててしまうと、大切な情報が失われ、結果の正確さが低くなる可能性があります。例えば、商品の売れ行き予測で、特定の時期の販売データだけを都合よく選んで使うと、実際の売れ行きを正しく反映しないモデルができてしまうかもしれません。反対に、必要のない情報を残しておくと、情報の質が下がり、結果に悪影響を与える可能性があります。例えば、商品の色と売れ行きの関係を調べたいのに、関係のない製造工場の情報まで含めてしまうと、分析が複雑になり、正しい結果を得にくくなるかもしれません。適切な量の情報を適切な方法で使うことが、良い結果を得るために重要なのです。
| データの取捨選択の重要性 | 考慮すべき点 | 例 |
|---|---|---|
| 結果に大きな影響を与えるため、慎重に行う必要がある | 情報の取捨選択の理由、捨てる情報の量 | 商品の売れ行き予測モデル作成 |
| 目的や情報の種類によって適切な情報を選択する | 予測期間 | 短期予測:長期的な景気変動はあまり関係ない 長期予測:景気の変動は重要な要素 |
| 情報の質(正確さ) | 価格の入力ミス:売れ行きを過小評価する可能性 | |
| 適切な量の情報を適切な方法で使うことが重要 | 不用意に情報を捨てると、結果の正確さが低くなる | 特定の時期の販売データだけを使う:実際の売れ行きを正しく反映しないモデル |
| 必要のない情報を使うと、情報の質が下がり、結果に悪影響を与える | 関係のない製造工場の情報:分析が複雑になり、正しい結果を得にくくなる |
データの取捨選択とモデルの評価

機械学習モデルを作る上で、扱うデータの選び方はモデルの良し悪しを大きく左右します。そのため、どのデータをモデルに学習させるか、どのデータを捨てるかの判断は非常に重要です。このデータの取捨選択の効果を正しく測るには、適切な方法でモデルの性能評価を行う必要があります。
まず、データを取捨選択する前と後それぞれのモデルで、どの程度予測が当たっているか、つまり精度を比較することが大切です。精度は、例えば全体の中で正しく予測できた割合などで表すことができます。取捨選択後に精度が上がっていれば、その選択はモデルの性能向上に役立ったと言えるでしょう。逆に、精度が下がっていれば、取捨選択が適切でなかった可能性があり、見直しが必要になります。
データの取捨選択には様々な方法があり、どの方法が最も効果的かはデータの種類や目的によって異なります。例えば、ある値を基準にして、それより大きいデータだけを使う、小さいデータだけを使う、といった方法があります。この基準値のことを「しきい値」と呼びますが、このしきい値を様々に変えて試すことで、どのしきい値が最も効果的か検証することができます。
モデルの評価は一度だけでなく、様々な条件で繰り返し行うことが重要です。例えば、データを学習用と検証用に分けて、学習用データでモデルを作り、検証用データでその性能を評価します。このデータの分け方を何度も変えて評価することで、特定のデータに偏った結果にならないようにします。
適切な評価を行うことで、データの取捨選択が本当に効果があったのかを確認し、より良いモデルを作ることができます。どのデータをどのように選ぶか、様々な観点から検討し、試し、評価することで、最終的に優れた性能を持つモデルを開発することができます。
適切な活用で精度向上を

機械学習の予測精度を高めるには、学習に使うデータの取捨選択が重要です。このデータの取捨選択を指すのが「カットオフ」です。古い情報や関係のない情報まで含んだまま学習を進めると、本当に必要な情報が埋もれてしまい、学習の効率が悪くなるだけでなく、予測精度も下がってしまうことがあります。
カットオフは、まるで植物の剪定作業のようです。不要な枝葉を取り除くことで、植物は栄養を必要な部分に集中させ、すくすくと成長することができます。同様に、機械学習においても、古くなったデータや関係のないデータを適切に取り除くことで、モデルは重要な情報に集中できます。これにより、より正確な予測を行うことができるようになります。
例えば、時間の流れとともに変化するデータ(時系列データ)を扱う場合を考えてみましょう。過去のトレンドが現在の状況にそぐわない場合は、古いデータを学習に含めると予測の精度が落ちてしまいます。このような場合は、ある時点を境に古いデータを切り捨てることで、現在の状況をより正確に反映した予測が可能になります。
また、特定の条件下で収集されたデータのみを扱う場合も、カットオフが重要になります。例えば、特定の地域における天気予報モデルを作る際に、他の地域の気象データは不要、もしくは悪影響を与える可能性があります。このような場合は、対象地域以外のデータをカットオフすることで、予測精度を高めることが期待できます。
しかし、カットオフは慎重に行う必要があります。必要なデータまで切り捨ててしまうと、モデルの学習が不十分になり、予測精度が低下する可能性があります。そのため、どのような基準でデータを切り捨てるのか、慎重に検討する必要があります。また、カットオフの効果を適切に測るための評価方法も大切です。目的に合った評価方法を選び、カットオフの効果を検証することで、より精度の高い機械学習モデルを作ることができるでしょう。適切なカットオフは、質の高い予測モデルを作るための土台と言えるでしょう。