
交差検証でモデルの精度を確かめる

AIを知りたい
先生、「交差検証」って、データを二つに分けて学習と評価をするんですよね? なぜそんなことをするんですか? 全部まとめて学習した方が、より多くのデータから学習できて良いモデルが作れるんじゃないでしょうか?

AIエンジニア
良い質問ですね。確かに全部のデータを使えば多くの情報から学習できます。しかし、作ったモデルが本当に使えるものかどうかを判断するには、学習に使っていないデータで試す必要があるんです。学習に使ったデータで評価すると、そのデータに特化しただけの、新しいデータには対応できないモデルになってしまう可能性があるんですよ。
AIを知りたい
なるほど。つまり、作ったモデルが未知のデータに対してもちゃんと使えるかを確認するために、学習に使っていないデータでテストする必要があるんですね。でも、なぜ「交差」検証というんですか?
AIエンジニア
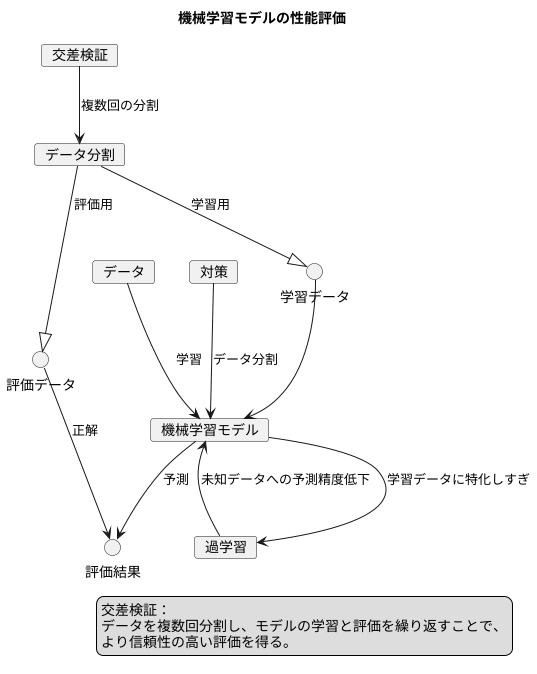
それは、一度だけでなく、データを複数回に分けて、それぞれの分割パターンで学習と評価を繰り返すからです。例えば、5分割交差検証なら、データを5つに分けて、1つを評価用、残りの4つを学習用としてモデルを作り、これを5回繰り返します。こうすることで、限られたデータからより信頼性の高い評価ができます。
交差検証とは。
人工知能の分野でよく使われる「交差検証」という言葉について説明します。交差検証とは、持っている全てのデータを、学習に使うデータ(訓練データ)と、学習した結果を評価するためのデータ(テストデータ)の2つに、無作為に分けて評価する手法のことです。
交差検証とは

機械学習の分野では、作った模型がどれほど使えるものなのかをきちんと確かめることが大切です。この作業を「模型の性能評価」と言いますが、そのための便利な方法の一つが「交差検証」です。
交差検証は、限られた学習データを有効に使い、模型が未知のデータに対してどれくらい正確に予測できるのかを評価する手法です。すべてのデータを使って模型を作ってしまうと、「過学習」という状態になりがちです。過学習とは、学習に使ったデータに対しては精度が高いように見えても、実際には新しいデータに対してはうまく予測できない状態のことです。例えるなら、過去問だけを完璧に覚えて試験に臨むようなもので、見たことのない問題に対応できません。
過学習を防ぐため、一般的にはデータを「学習用」と「評価用」に分けます。学習用データで模型を訓練し、評価用データでその性能を評価します。しかし、一度だけの分割では、たまたま分け方が偏っていた場合、正確な評価ができるとは限りません。まるで、過去問のほんの一部だけで自分の実力を判断するようなものです。
そこで交差検証の出番です。交差検証では、データを複数回にわたって異なる方法で学習用と評価用に分割します。それぞれの分割で模型の学習と評価を繰り返し、その結果を平均することで、より信頼性の高い評価を得られます。これは、過去問をいくつかのグループに分け、それぞれのグループで練習と模擬試験を繰り返すようなものです。何度も練習と試験を繰り返すことで、自分の本当の力が分かります。
このように、交差検証は、限られたデータから模型の真の実力を明らかにするための、強力な手法と言えるでしょう。
交差検証の方法

機械学習モデルの性能を正しく測ることは、精度の高い予測を行う上で欠かせません。そこで活用されるのが交差検証という手法です。交差検証とは、限られたデータを有効に使い、モデルの汎化性能、つまり未知のデータに対しても正しく予測できる能力を確かめるための方法です。
様々な交差検証の方法がありますが、最も広く使われているのがK分割交差検証です。この手法では、まず手元にある全てのデータをK個の同じくらいの大きさのグループに分けます。例として、Kを5としましょう。5分割交差検証の場合、データを5つのグループに分割します。
次に、この5つのグループのうち、4つのグループをモデルの学習に使い、残りの1つのグループを学習済みモデルの性能評価に使います。この時、学習に使ったデータは訓練データ、評価に使ったデータは検証データと呼ばれます。この学習と評価の手順を、検証データとして使うグループを順番に変えながら、5回繰り返します。つまり、5つのグループ全てが1回ずつ検証データの役割を果たします。
それぞれの検証データを使った評価で、モデルの性能を表す数値(例えば、正答率など)が得られます。5分割交差検証であれば、5回の評価で5つの性能数値が得られることになります。最後に、これらの数値の平均を計算することで、モデルの最終的な性能を評価します。
K分割交差検証は、全てのデータが検証データとして使われるため、限られたデータを無駄なく活用できる利点があります。また、複数回の評価を行うことで、特定のデータの分割方法に偏ることなく、より信頼性の高い性能評価を行うことができます。Kの値は、データ量や計算時間などを考慮して適切に選ぶ必要があります。Kの値が小さいと、検証データの量が多くなり、評価の精度は上がりますが、学習データが少なくなり、学習不足に陥る可能性があります。反対にKの値が大きいと、学習データは多くなりますが、検証データが少なくなり、評価の精度が下がる可能性があります。一般的には、K=5またはK=10がよく用いられます。
交差検証の利点

機械学習では、作った学習器の良し悪しを評価することが大切です。この評価を適切に行うための優れた手法の一つに、交差検証があります。交差検証を使う大きな利点は、限られた学習データを最大限に活用できることです。
通常、学習データは学習用と検証用に分割しますが、交差検証ではデータをいくつかのグループに分け、順番に各グループを検証用として、残りを学習用として使います。これを繰り返すことで、全てのデータが学習と検証の両方で使われます。それぞれのグループで検証した結果を平均することで、モデルの性能をより正確に把握できます。
もし、データを一度だけ分割して評価した場合、たまたま分割の仕方によって結果が偏ってしまう可能性があります。例えば、たまたま検証用データに簡単な問題ばかりが含まれていた場合、モデルの性能を過大評価してしまうかもしれません。しかし、交差検証では複数回評価を行うため、このような偶然の偏りを抑え、より客観的な結果を得られます。
交差検証は、過学習を防ぐ上でも役立ちます。過学習とは、学習データに過度に適応しすぎて、未知のデータに対してうまく対応できなくなる状態のことです。交差検証によって、モデルが学習データだけに特化していないかを確認できます。
さらに、交差検証は複数のモデルを比較する際にも役立ちます。例えば、異なる手法で学習させた複数のモデルがある場合、それぞれのモデルに交差検証を行い、その結果を比較することで、どのモデルが最も優れているかを判断できます。最適な手法や調整する値を決めるための手がかりにもなります。
| メリット | 説明 |
|---|---|
| 学習データの最大限活用 | 全てのデータが学習と検証の両方で使われるため、限られたデータを有効に活用できる。 |
| 評価の正確性向上 | 複数回の検証結果を平均することで、偶然の偏りを抑え、モデルの性能をより正確に把握できる。 |
| 過学習の防止 | モデルが学習データだけに特化していないかを確認できる。 |
| 複数モデルの比較 | 異なるモデルに交差検証を行い、結果を比較することで、最適なモデルを選択できる。 |
交差検証の種類

機械学習モデルの性能を正しく測るためには、交差検証が欠かせません。交差検証とは、手持ちのデータを複数の組に分け、それぞれの組で学習と評価を繰り返すことで、モデルの汎化性能を確かめる手法です。
中でも、よく知られているのがK分割交差検証です。これは、データをK個の組に等しく分けて、そのうち1つの組を評価用データ、残りのK-1個の組を学習用データとしてモデルを学習させます。この手順をK回繰り返すことで、全てのデータが1回ずつ評価用データとして使われます。この方法により、限られたデータからモデルの性能をより正確に評価できます。
K分割交差検証以外にも様々な方法があります。例えば、1つだけデータを評価用データとして取り出し、残りの全てを学習用データとする手法があります。これは、Leave-One-Out交差検証と呼ばれ、K分割交差検証のKをデータ数と同じにした場合に相当します。全てのデータが評価用データとして使われるため、精度の高い評価ができます。しかし、データが多いと計算に時間がかかってしまうという難点があります。
また、分類問題を扱う際、各分類のデータ数が大きく異なる場合があります。このような偏りのあるデータでK分割交差検証を行うと、特定の分類のデータばかりが学習用データや評価用データに偏ってしまう可能性があります。これを防ぐのが、層化K分割交差検証です。この方法は、元のデータの分類の比率を保ったままデータを分割します。例えば、犬と猫の画像分類で、犬の画像が9割、猫の画像が1割だった場合、分割後の各組も犬9割、猫1割の比率になるようにします。これにより、偏りの影響を抑え、より信頼性の高い評価を行うことができます。
このように、様々な交差検証の手法が存在し、それぞれに利点と欠点があります。データの性質や分析の目的に合わせて適切な手法を選ぶことが、モデルの性能を正しく評価し、より良いモデルを作る上で重要です。
| 手法 | 説明 | 利点 | 欠点 |
|---|---|---|---|
| K分割交差検証 | データをK個の組に分け、1つを評価用、残りを学習用としてK回繰り返す。 | 限られたデータからモデルの性能をより正確に評価できる。 | – |
| Leave-One-Out交差検証 | 1つだけを評価用データとして取り出し、残りを学習用データとする。K分割交差検証のKをデータ数と同じにした場合に相当。 | 全てのデータが評価用データとして使われるため、精度の高い評価ができる。 | データが多いと計算に時間がかかる。 |
| 層化K分割交差検証 | 元のデータの分類の比率を保ったままデータを分割するK分割交差検証。 | 偏りの影響を抑え、より信頼性の高い評価を行うことができる。 | – |
交差検証の実施

機械学習の分野では、作成した学習器の性能を正しく評価することがとても大切です。そのためによく用いられる手法が交差検証です。この手法は、限られたデータを有効に活用して、学習器の性能をより信頼性の高い形で評価することを可能にします。多くの機械学習の道具箱には、この交差検証を行うための便利な関数が用意されています。例えば、Pythonでよく使われるscikit-learnには、様々な交差検証の手法が組み込まれています。代表的なものには、データを単純に分割するK分割交差検証や、データの偏りを考慮して分割する層化K分割交差検証などがあります。これらの関数を使うことで、難しい手順を踏むことなく、手軽に交差検証を行うことができます。
交差検証を行う際には、いくつか注意すべき点があります。まず、データの前処理です。データに欠損値や異常値が含まれている場合は、それらを適切に処理する必要があります。例えば、欠損値を平均値で補完したり、異常値を取り除いたりすることで、モデルの精度を向上させることができます。次に、モデルに含まれる調整可能な数値(パラメータ)を適切に設定することも重要です。パラメータの値によってモデルの性能は大きく変わるため、最適な値を見つける必要があります。このパラメータ調整と交差検証を組み合わせることで、限られたデータからでも性能の良いモデルを作り出すことができます。
さらに、交差検証が終わった後には、その結果を詳しく調べることが重要です。単にモデルの性能を見るだけでなく、どの部分で予測がうまくいっているのか、あるいはうまくいっていないのかを分析することで、モデルの弱点や改善点が見えてきます。例えば、特定の種類のデータで予測精度が低い場合は、そのデータに特化した学習を行う、あるいはモデルの構造を見直す必要があるかもしれません。このように、交差検証の結果を分析し、モデルを改良していくことで、より実用的な、信頼性の高い機械学習モデルを開発することができます。
| 機械学習における交差検証の重要性と注意点 |
|---|
|
| 交差検証の注意点 |
|
交差検証の注意点

機械学習モデルの性能をきちんと評価するために、交差検証は欠かせない手法です。しかし、いくつかの注意点を守らないと、その効果を十分に発揮できないことがあります。まず、データをいくつかのグループに分ける方法は、データの性質に合わせて慎重に選ぶ必要があります。例えば、株価の予測のように、時間の流れに沿って変化するデータの場合、無作為にグループ分けしてしまうと、未来のデータを使って過去のデータを予測するような、本来ありえない状況を作ってしまいます。このようなデータでは、時間を追って順番にグループ分けすることで、より現実に近い形でモデルの性能を測ることができます。
次に、モデルの良し悪しを判断する基準も、扱う問題によって適切に選ぶ必要があります。例えば、病気の有無を判別するような問題では、どれだけ正確に病気を当てられるかを示す「精度」や、実際に病気の人をどれだけ見つけられるかを示す「再現率」といった指標がよく使われます。一方、家の価格を予測するような問題では、予測値と実際の値のずれの大きさを示す「平均二乗誤差」や、予測がどれだけデータのばらつきを説明できているかを示す「決定係数」といった指標が用いられます。扱う問題に合わない指標を使うと、モデルの本当の性能を見誤ってしまう可能性があります。
最後に、交差検証は何度もモデルの学習と評価を繰り返すため、計算に時間がかかるという点にも注意が必要です。特に、扱うデータが膨大だったり、モデルが複雑だったりする場合には、かなりの計算時間がかかってしまうことがあります。そのため、使える時間や計算資源を考慮して、検証の回数などを調整する必要があります。例えば、データ量が非常に多い場合には、検証の回数を減らしたり、より単純なモデルを使ったりすることで、計算時間を短縮することができます。適切な方法を選ぶことで、限られた時間の中で効率的にモデルを評価することができます。
| 注意点 | 詳細 | 例 |
|---|---|---|
| データのグループ分け | データの性質に合わせ、慎重にグループ分けの方法を選ぶ必要がある。時系列データの場合は、時間を追って順番にグループ分けする。 | 株価予測 |
| モデル評価指標の選択 | 扱う問題によって適切な指標を選ぶ必要がある。 | 病気の有無:精度、再現率 家の価格:平均二乗誤差、決定係数 |
| 計算時間 | 交差検証は計算に時間がかかるため、データ量やモデルの複雑さ、利用可能な資源を考慮して検証回数などを調整する。 | データ量が多い場合は検証回数を減らす、単純なモデルを使う |