
交差検証でモデルの精度を確かめる

AIを知りたい
先生、交差検証って学習データとテストデータを分けて評価するんですよね? なぜ、わざわざ分ける必要があるんですか? 全部まとめて学習に使った方が、より多くのデータから学習できて良いような気がするのですが…

AIエンジニア
良い質問ですね。確かに、全部のデータで学習させれば、一見多くのことを学習できそうですが、実は落とし穴があります。作ったモデルが、未知のデータに対してどれくらいうまく対応できるか、つまり汎化性能を測ることができないのです。
AIを知りたい
汎化性能…ですか?
AIエンジニア
はい。例えば、過去のテストの問題と解答を全て暗記したとします。しかし、少し問題文が変わると解けなくなる、というのは汎化性能が低いと言えます。交差検証は、学習に使っていないデータで性能を測ることで、この汎化性能を評価し、未知のデータに対しても正しく動くかを確認するために行うのです。
交差検証とは。
人工知能でよく使われる「交差検証」という用語について説明します。交差検証とは、持っている全てのデータを学習に使うデータと、学習した結果を評価するためのデータの2つに、でたらめに分けて評価する方法のことです。
交差検証とは

機械学習の分野では、作った模型がどれほど使えるのかを確かめることがとても大切です。この確認作業でよく使われるのが交差検証と呼ばれる方法です。交差検証を使う目的は、限られた学習データを最大限に活用し、未知のデータにどれだけうまく対応できるのか、つまり汎化性能を正しく評価することにあります。
交差検証は、データをいくつかのグループに分けて行います。それぞれのグループを順番にテストデータとして使い、残りのグループを学習データとして模型を作ります。例えば、10個のデータがあったとしましょう。このデータを10個のグループに分けます。まず、1番目のグループをテストデータ、残りの9個のグループを学習データとして模型を作ります。次に、2番目のグループをテストデータ、残りの9個のグループを学習データとして模型を作ります。これを全てのグループが一度テストデータになるまで繰り返します。
このようにして、それぞれのグループで作った模型の性能を平均することで、模型全体の性能を評価します。この方法を10分割交差検証と呼びます。5分割交差検証や3分割交差検証といった方法もあります。分割数を大きくするほど、学習データは多くなり、テストデータは少なくなります。
交差検証を行う利点は、限られたデータから偏りのない評価結果を得られることです。もし、データを一度だけ学習用とテスト用に分けた場合、その分け方によって評価結果が大きく変わる可能性があります。交差検証では、全てのデータがテストデータとして使われるため、特定のデータ分割による偏りを防ぎ、より客観的な評価が可能になります。こうして、未知のデータに対しても安定した性能を発揮する、信頼性の高い模型を作ることができます。
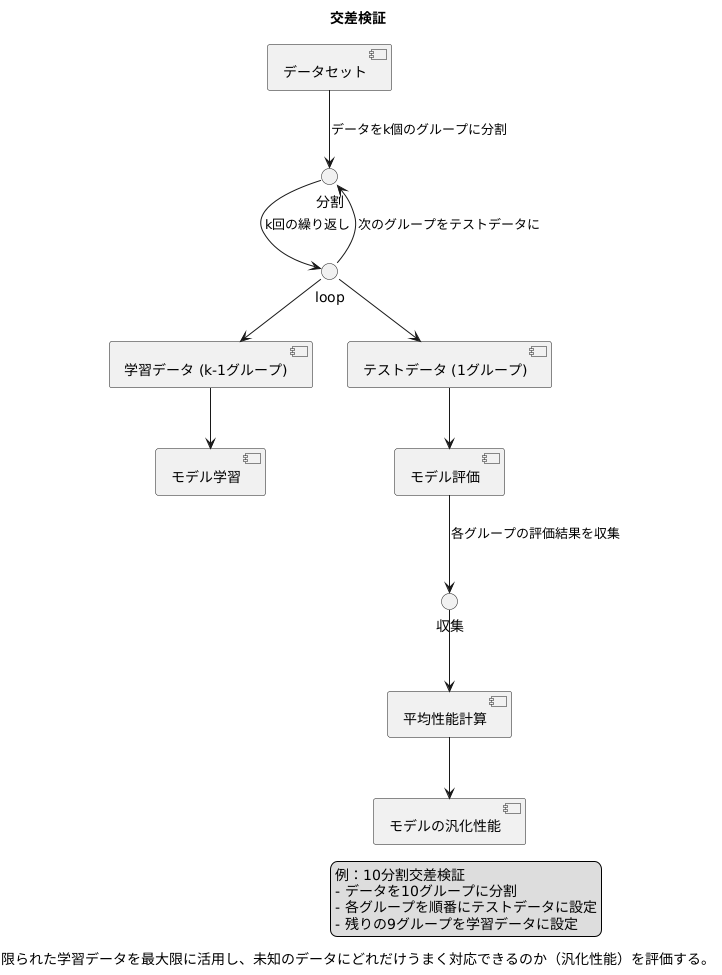
交差検証の方法

機械学習において、作った学習器の性能を正しく測ることはとても大切です。そこで役に立つのが交差検証という方法です。交差検証は、限られたデータを使って、学習器の性能をしっかりと確かめるための工夫です。
まず、集めたデータをいくつかのグループに分けます。このグループの数は、データの量や種類によって適切に決める必要があります。一般的には5個か10個のグループに分けることが多いです。グループの大きさは、できるだけ同じになるようにします。
次に、分けられたグループの中から一つを選び、これをテスト用のデータとします。残りのグループは、学習器の訓練に使う学習用のデータとなります。学習用のデータを使って学習器を訓練し、その後、テスト用のデータを使って学習器の性能を評価します。
この手順を、それぞれのグループが一度ずつテスト用データになるまで繰り返します。つまり、最初のグループ分けで5つのグループを作った場合は、この手順を5回繰り返すことになります。それぞれのグループがテスト用データになることで、全てのデータが平等に評価に使われます。
最後に、各回の評価結果を平均します。この平均値が、その学習器の最終的な性能の目安となります。交差検証を使うことで、限られたデータから学習器の性能をより正確に、そして公平に見積もることが可能になります。これは、新しいデータに対する学習器の性能を予測するのにも役立ちます。
交差検証の利点

機械学習のモデルを作る際には、限られた学習データからそのモデルの性能や信頼性をきちんと測る方法が必要です。その際に役立つのが、交差検証と呼ばれる手法です。交差検証を使う大きな利点は、少ない学習データを無駄なく有効に使えることにあります。
交差検証では、全てのデータを学習と検証の両方に使います。例えば、データを5つに等しく分けて、そのうち4つをモデルの学習に使い、残りの1つを性能の検証に使います。これを5回繰り返し、毎回異なる部分を検証に使うことで、全てのデータが学習と検証の両方に使われます。このため、特定のデータの分け方に偏ることなく、モデルの性能をしっかりと測ることができます。ある特定のデータの分け方によって、たまたま良い結果や悪い結果が出てしまうことを避けることができ、より信頼性の高い評価が可能になります。
また、データの偏りの影響も減らすことができます。限られたデータの中に、特定の特徴を持つデータが偏って多く含まれていると、そのデータに特化したモデルが作られてしまうことがあります。しかし、交差検証では、異なるデータの組み合わせで何度も学習と検証を行うため、特定のデータの偏りに影響されにくい、汎用的なモデルを作ることができます。
さらに、交差検証は様々な種類の機械学習モデルに使える汎用的な手法です。異なる種類のモデルを同じデータセットで交差検証し、その結果を比べることで、どのモデルがそのデータセットに適しているかを判断できます。複数のモデルを公平に比較できるため、最適なモデルを選ぶのに役立ちます。
このように、交差検証は限られた学習データを有効に活用し、モデルの性能と信頼性を高めるために非常に役立つ手法です。そして、様々なモデルに適用できるという汎用性も大きな魅力です。だからこそ、機械学習の分野で広く使われています。
| メリット | 説明 |
|---|---|
| 学習データの有効活用 | 少ない学習データを無駄なく、学習と検証の両方に利用できる。 |
| 信頼性の高い評価 | 全てのデータが学習と検証に使われるため、特定のデータの分け方に偏ることなく、モデルの性能をしっかりと測れる。 |
| データの偏りの影響軽減 | 異なるデータの組み合わせで学習と検証を行うため、特定のデータの偏りに影響されにくい汎用的なモデルを作れる。 |
| 様々なモデルに適用可能 | 様々な種類の機械学習モデルに適用できるため、複数のモデルを公平に比較し、最適なモデルを選択するのに役立つ。 |
データ分割の注意点

情報を正しく扱うためには、データを適切に分割することがとても大切です。特に、交差検証を行う際には、その分割方法が結果に大きく影響します。データの特徴を無視して無作為に分割すると、偏りが生じる恐れがあります。
例えば、時間の流れに沿って変化するデータの場合を考えてみましょう。このようなデータは、時間の流れに沿って分割しなければなりません。無作為に分割すると、未来の情報を使って過去を予測してしまうという、論理的に矛盾した状況が起こりえます。これは、まるで未来の新聞を見て昨日の株価を予想するようなものです。このような予測は正確ではなく、信頼できません。
また、データの中に特定の特徴を持つ情報が少ない場合も注意が必要です。例えば、ある病気の患者データを集めたとします。その病気の患者数が非常に少ない場合、無作為にデータを分割すると、あるグループにはその病気の患者データが全く入らないということが起こりえます。このような場合、層化抽出法という手法を用いて、各グループにおけるデータの割合が元のデータセットと同じになるように分割する必要があります。これは、全体の縮図をそれぞれのグループで再現するようなイメージです。
このように、データの性質を理解し、それに適した分割方法を選ぶことが、信頼できる結果を得るために非常に重要です。目的に合わせて適切な道具を選ぶように、データの特性に合わせて分割方法を慎重に選択することで、より正確な分析を行うことができます。
| データの性質 | 分割方法 | 問題点(無作為分割時) | 解決策 |
|---|---|---|---|
| 時間の流れに沿って変化するデータ | 時間の流れに沿った分割 | 未来の情報を使って過去を予測してしまう (論理的に矛盾) | 時系列順に分割 |
| 特定の特徴を持つ情報が少ないデータ | 層化抽出法 | 特定の情報が一部のグループに偏る、または欠落する | 各グループでデータの割合を元のデータセットと同じにする |
交差検証の種類

交差検証とは、機械学習モデルの性能をより正確に評価するための手法です。限られたデータから学習と評価を行う際に、データの分割方法によって評価結果が大きく変わってしまう可能性があります。そこで、交差検証を用いることで、様々なデータ分割を試して、モデルの平均的な性能を測ることができるのです。
交差検証にはいくつか種類があり、代表的なものを紹介します。まず、広く使われているのが「K分割交差検証」です。これは、全てのデータをK個のグループに均等に分割し、そのうち1つのグループを検証データ、残りのK-1個のグループを学習データとしてモデルを学習・評価します。この手順をK回繰り返し、毎回異なるグループを検証データとして使うことで、全てのデータが1回ずつ検証データとして使われます。そして、K回の評価結果の平均を最終的なモデルの性能とします。Kの値は一般的に5や10が使われますが、データ量や性質に応じて適切な値を選ぶ必要があります。
次に、「Leave-One-Out交差検証」について説明します。これは、K分割交差検証のKをデータの総数と同じにした特殊な場合です。つまり、1つのデータだけを検証データとし、残りのデータを学習データとしてモデルを学習・評価します。この手順をデータの数だけ繰り返し、全てのデータが1回ずつ検証データとなります。この方法は、データが少ない場合に有効ですが、計算コストが高くなるという欠点があります。
最後に、「層化K分割交差検証」を紹介します。この手法は、K分割交差検証と似ていますが、各グループのデータのクラスの割合を元のデータセットとほぼ同じになるように分割します。例えば、犬と猫の画像分類で、元のデータセットに犬の画像が70%、猫の画像が30%含まれている場合、分割後の各グループも犬が70%、猫が30%となるように調整します。この手法は、分類問題において、データの偏りによる影響を軽減し、より正確な評価を行うために有効です。
どの交差検証の手法を選ぶかは、データの量や種類、そして分析の目的によります。それぞれの長所と短所を理解し、適切な手法を選択することが重要です。
| 手法 | 説明 | 長所 | 短所 | 適用場面 |
|---|---|---|---|---|
| K分割交差検証 | データをK個のグループに分割し、1グループを検証データ、残りを学習データとしてK回学習・評価を行う。 | 広く使われており、比較的計算コストが低い。 | Kの値の選択が重要。 | データ量が多めで、Kの値を適切に設定できる場合。 |
| Leave-One-Out交差検証 | K分割交差検証のKをデータの総数としたもの。1データずつ検証データとして学習・評価を行う。 | データが少ない場合に有効。 | 計算コストが高い。 | データが少ない場合。 |
| 層化K分割交差検証 | K分割交差検証と同様だが、各グループのクラス割合を元のデータセットとほぼ同じにする。 | 分類問題でデータの偏りの影響を軽減できる。 | K分割交差検証と同様にKの値の選択が重要。 | 分類問題でデータの偏りがある場合。 |