共変量シフト:機械学習モデルの落とし穴

AIを知りたい
先生、「共変量シフト」ってよく聞くんですけど、何のことか教えてもらえますか?

AIエンジニア
はい。「共変量シフト」とは、機械学習などで、予測したいものと、予測に使っているデータの関係性が、学習時と予測時で変わってしまうことを指します。例えば、ある商品の売上を予測するモデルを作ったとします。学習時は夏のデータを使っていたのに、予測時に冬のデータを使うと、気温などの影響で売上の傾向が変わってしまい、予測精度が悪くなることがあります。これが共変量シフトの一例です。つまり、予測に使うデータの分布が変わってしまう現象ですね。
AIを知りたい
なるほど。予測に使うデータが変わってしまうんですね。関係性が変わるっていうのは、どういうことですか?
AIエンジニア
例えば、さっきの商品の売上の例で言うと、夏は気温が高いほど売上が上がりますが、冬は気温が低いほど売上が上がるかもしれません。このように、気温と売上の関係性が季節によって変わってしまうと、学習時と予測時でデータの分布が変わり、予測精度に悪影響を与えるのです。これが「関係性が変わる」という意味です。分かりましたか?
共変量シフトとは。
人工知能で使う言葉の一つに「共変量シフト」というものがあります。これは、機械学習や予測分析といった分野で使われます。この「共変量シフト」は様々な原因で起こる変化のことを指し、その原因別に色々な呼び方があります。中でも「概念ドリフト」と「データドリフト」は重要な言葉です。
はじめに

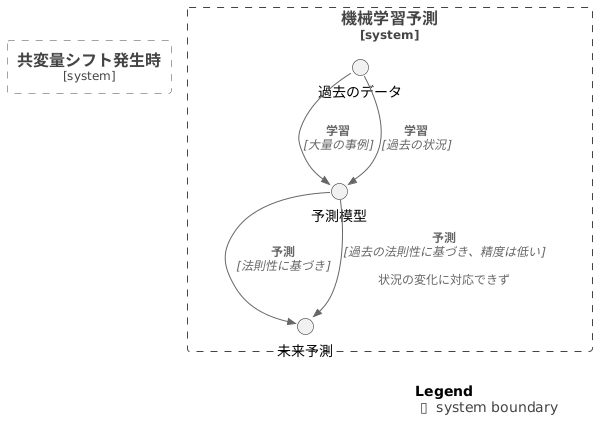
機械学習は、大量の事例から法則性を学び、将来の出来事を予想する強力な手法です。まるで、たくさんの経験を積むことで未来を見通す達人のようです。しかし、現実の世界は常に変化し続けています。そのため、一度学習を終えた予測模型も、時間の流れと共にその精度が落ちてしまうことがあります。これは、様々な原因によって起こりうる現象ですが、中でも「共変量シフト」は重要な考え方です。
共変量シフトとは、予測模型に入力される情報の傾向が、学習時と予測時で異なってしまうことを指します。例えば、過去の天気図から明日の天気を予測する模型を考えてみましょう。この模型は、過去の大量の天気図を学習することで、雲の動きや気圧の変化などから天気の法則を学びます。しかし、もし地球温暖化の影響で気候の傾向が大きく変わってしまった場合、学習時と予測時で天気図の傾向が異なってしまいます。つまり、模型が学習した天気の法則と、実際に予測を行う際の天気の法則が食い違ってしまうのです。これが共変量シフトです。
このように、模型が学習した時の状況と、実際に予測を行う時の状況が異なると、予測の正確さが低下してしまいます。これは、まるで過去の経験に基づいて未来を予測しようとした達人が、状況の変化に対応できずに的外れな予測をしてしまうようなものです。この共変量シフトという問題は、機械学習模型を実際に運用する上で避けては通れない課題です。そのため、その影響を正しく理解し、適切な対策を講じることがとても重要になります。例えば、定期的に新しい情報を模型に学習させることで、変化する状況に対応させることができます。また、共変量シフトの影響を受けにくい、より頑健な模型を作るための研究も進められています。このように、機械学習を効果的に活用するためには、共変量シフトへの理解と対策が欠かせません。
共変量シフトとは

機械学習の分野において、学習済みの予測モデルが実世界のデータに対して期待通りの性能を発揮しない、という問題に直面することがしばしばあります。このような事態を引き起こす要因の一つに、「共変量シフト」と呼ばれる現象があります。これは、モデルの学習に用いたデータと、実際に予測を行う際に用いるデータとで、入力データの特徴の分布、すなわち共変量の分布が異なっている状態を指します。
例として、商品の需要を予測するモデルを考えてみましょう。過去の販売データを使ってモデルを学習させた後、そのモデルを使って将来の需要を予測しようとします。しかし、学習データを集めた時点と予測を行う時点では、様々な要因によってデータの分布が変化している可能性があります。例えば、景気の変動によって消費者の購買意欲が変化したり、季節の変化によって特定の商品への需要が増減したり、競合他社の参入によって市場の構造が変化したりするかもしれません。これらの変化によって、過去のデータと将来のデータでは、商品の価格、広告費、気温といった入力データの特徴の分布が異なってしまうのです。これが共変量シフトです。
共変量シフトが発生すると、学習済みのモデルは予測精度が低下してしまいます。なぜなら、モデルは学習データの分布に最適化されているため、分布の異なるデータに対してはうまく対応できないからです。例えば、過去のデータでは価格が高いほど需要が低かったとしても、景気が好転して消費者の購買意欲が高まれば、価格が高くても需要は下がらないかもしれません。このような場合、過去のデータに基づいて学習されたモデルは、将来の需要を過小評価してしまう可能性があります。
このように、共変量シフトは機械学習モデルの性能に大きな影響を与えるため、モデル構築の際にはその可能性を十分に検討し、適切な対策を講じることが重要です。例えば、共変量シフトの影響を受けにくい頑健なモデルを学習する方法や、学習データの分布を予測データの分布に合わせる方法などが研究されています。これらの対策によって、共変量シフトによる予測精度の低下を防ぎ、より信頼性の高い予測モデルを構築することが可能になります。
概念ドリフトとの関係

機械学習の分野では、時間の流れとともに予測の精度が下がるという問題がよく起こります。これは概念ドリフトと呼ばれる現象と深い関わりがあります。概念ドリフトとは、予測したいものと、予測に使うものの関係性が変わってしまうことを指します。
概念ドリフトの中には、いくつかの種類があります。その一つが共変量シフトです。これは、予測に使うデータのばらつき方が変わることを意味します。例えば、ある商品の需要予測モデルを考えたとき、季節が変われば売れ筋商品も変わるため、過去のデータの傾向が未来の予測に合わなくなることがあります。これが共変量シフトの一例です。
しかし、概念ドリフトは共変量シフトだけではありません。予測したいもの自体が変わってしまうこともあります。これを事前確率シフトといいます。例えば、ある病気の診断モデルを考えたとき、ある地域でその病気が流行すれば、患者数が増え、診断モデルの精度に影響が出ることがあります。
さらに、予測に使うものと予測したいものの関係が変わってしまうこともあります。これを条件付き確率シフトといいます。例えば、ある広告の効果予測モデルを考えたとき、消費者の好みが変われば、同じ広告でも効果が変わることがあります。
このように、概念ドリフトには様々な種類があり、これらが複雑に絡み合って機械学習モデルの精度を下げる原因となります。精度を保つためには、それぞれの変化の種類を正しく見分け、適切な対策を講じることが重要です。

データドリフトとの関係

機械学習のモデルは、過去の情報から未来を予想する賢い道具のようなものです。しかし、世の中の状況は常に変化します。この変化が、機械学習モデルの精度に大きな影響を与えることがあります。これが「データドリフト」と呼ばれる現象です。
データドリフトとは、モデル学習に使ったデータと、実際に予測を行う時のデータの特徴がずれてしまうことを指します。たとえば、ある商品の売れ行きを予測するモデルを作ったとします。学習データは夏の暑い時期のもので、モデルは気温が高いほど売上が伸びると学習しました。しかし、冬になり気温が下がると、このモデルは売れ行きを過大に予測してしまうでしょう。これは、学習時と予測時で気温というデータの性質が変わってしまった、つまりデータドリフトが発生した例です。
データドリフトは、「共変量シフト」と深い関係があります。共変量とは、予測したいものと関係する要素のことです。先ほどの例では気温が共変量に当たります。共変量シフトは、この共変量の分布、つまりデータのばらつき方が変わってしまうことを意味します。データドリフトは、入力データ全体の変化を指すのに比べ、共変量シフトは予測に関連する変数の変化に注目しています。つまり、共変量シフトはデータドリフトの一種と言えるでしょう。
データドリフトが発生すると、せっかく作ったモデルの精度が下がってしまいます。これは、まるで地図が古くなって目的地にたどり着けなくなるようなものです。ですから、データドリフトをいち早く見つけ、なぜそうなったのかを調べ、対策を立てることが重要です。例えば、定期的にモデルを新しいデータで学習し直したり、変化に強いモデルを開発するなど、様々な工夫が必要となります。
対策

機械学習モデルの予測精度を維持するには、共変量シフト、つまり学習時と予測時でデータの分布が変化してしまう問題への対策が欠かせません。この問題に対処するための主な手法として、領域適応、重み付け学習、そしてモデルの再学習が挙げられます。
領域適応とは、学習データと予測データの分布のずれを小さくすることを目指す手法です。例えるなら、方言と標準語のように、地域によって言葉遣いが違うと、同じ意味でも伝わりにくくなります。これと同じように、データの分布が違うと、モデルがうまく予測できません。領域適応は、データの共通の特徴を捉え、方言と標準語を翻訳するように、学習データと予測データの分布を近づけることで、モデルが予測しやすくなるようにします。
重み付け学習は、予測データに近い学習データに重みを付け、遠いデータには小さな重みを付けて学習する手法です。これは、周りの環境に詳しい人に意見を求めるようなものです。予測したいデータに近いデータは、予測にとってより重要なので、大きな重みを付けてモデルに重点的に学習させることで、予測精度を向上させることができます。
モデルの再学習は、最新のデータを用いてモデルを定期的に学習し直す手法です。時代の変化に合わせて知識を更新する必要があるように、データの分布も時間と共に変化します。古い知識に基づいたモデルは、最新の情報には対応できません。そのため、定期的に新しいデータでモデルを学習し直すことで、データの変化に追従し、予測精度を保つことができます。
これらの手法は単独で用いることもできますが、組み合わせて使うことでより効果的になります。例えば、領域適応でデータの分布を調整した後に重み付け学習を行い、さらに定期的にモデルの再学習を行うことで、共変量シフトの影響を抑え、安定した予測性能を実現できます。
| 手法 | 説明 | 例え |
|---|---|---|
| 領域適応 | 学習データと予測データの分布のずれを小さくする。 | 方言と標準語を翻訳する |
| 重み付け学習 | 予測データに近い学習データに重みを付け、遠いデータには小さな重みを付けて学習する。 | 周りの環境に詳しい人に意見を求める |
| モデルの再学習 | 最新のデータを用いてモデルを定期的に学習し直す。 | 時代の変化に合わせて知識を更新する |
まとめ

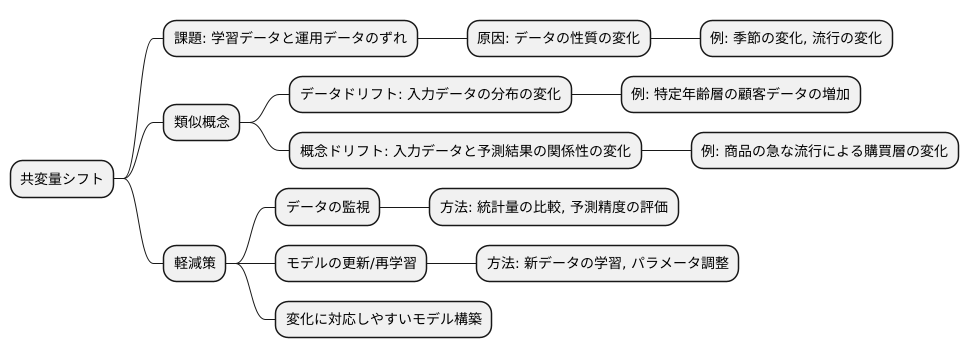
機械学習の予測モデルは、学習に使ったデータと実際の運用データとの間に違いが生じると、予測精度が落ちてしまうことがあります。この学習データと運用データのずれを共変量シフトと呼び、機械学習モデルをうまく運用していく上で重要な課題となっています。
この共変量シフトは、データの性質の変化が原因で起こります。例えば、ある商品の購買予測モデルを構築したとします。このモデルは過去の購買データに基づいて学習されていますが、季節の変化や流行の変化によって顧客の購買傾向が変化することがあります。すると、学習データと運用データの間にずれが生じ、予測精度が低下してしまうのです。
共変量シフトと似た言葉に概念ドリフトとデータドリフトがあります。データドリフトは、入力データの分布が変化することを指します。例えば、商品の購買予測モデルで、ある時期から特定の年齢層の顧客データが増加した場合、データドリフトが発生したと言えます。概念ドリフトは、入力データと予測したい結果との関係性が変化することを指します。例えば、ある商品が急に流行し始め、購買層が大きく変化した場合、概念ドリフトが発生したと言えます。共変量シフトは、このデータドリフトと概念ドリフトの両方、あるいはどちらか一方によって引き起こされる可能性があります。
では、共変量シフトの影響を軽減するためにはどうすれば良いのでしょうか。まず、データの変化を常に監視することが重要です。具体的には、学習データと運用データの統計量を比較したり、モデルの予測精度を継続的に評価したりすることで、データの変化を早期に発見することができます。
データの変化が確認された場合は、モデルの更新や再学習が必要になります。具体的には、変化したデータを追加で学習させたり、モデルのパラメータを調整したりすることで、モデルの精度を回復させることができます。また、変化に対応しやすいモデルを最初から構築しておくことも有効です。
このように、共変量シフトへの理解と適切な対策は、機械学習モデルを現実世界で効果的に活用するために不可欠です。常にデータの変化に注意を払い、継続的な改善を心がけることで、信頼性の高い予測モデルを維持し、変化する環境にも対応できる、より頑丈な機械学習システムを構築することができます。