
分類問題:機械学習の基礎

AIを知りたい
先生、「分類問題」って、何ですか?よく聞くんですけど、イメージが掴めなくて…

AIエンジニア
そうだね。「分類問題」とは、簡単に言うと、色々なものを見て、それがどのグループに属するかを当てる問題のことだよ。例えば、色々な動物の画像を見て、それが犬か猫か、鳥か魚かを当てるような問題だね。
AIを知りたい
なるほど。動物の画像を見て、種類を当てるのは「分類問題」なんですね。他に例はありますか?
AIエンジニア
もちろん。例えば、手書きの数字を見て、それが何の数字かを当てるのも分類問題だよ。他にも、メールを見て、それが迷惑メールか普通のメールかを判断するのも分類問題だね。色々なものを見て、グループ分けする問題全般を「分類問題」と言うんだよ。
分類問題とは。
人工知能にまつわる言葉で「分類問題」というものがあります。これは、例えば動物の写真のように、いくつかの種類に分けることができるもの(連続していない値)を予測する問題のことです。
分類問題とは

分類問題は、ものごとをあらかじめ決められた種類に振り分ける問題です。私たちが日常で行っている多くの判断も、実は分類問題として考えることができます。たとえば、朝起きて空模様を見て、今日は傘を持って出かけようか、それとも持って行かなくても大丈夫か判断するのは、天気を「雨」か「晴れ」の二つの種類に分類していると言えるでしょう。分類問題は、機械学習の分野でも重要な役割を担っています。コンピュータに大量のデータを与えて学習させることで、様々なものを自動的に分類する仕組みを作ることができるのです。
具体例を見てみましょう。犬と猫の画像を大量にコンピュータに学習させ、それぞれの画像の特徴を覚えさせます。学習が完了すると、コンピュータは初めて見る画像に対しても、それが犬なのか猫なのかを高い精度で判断できるようになります。また、メールの本文や送信元情報などを用いて、迷惑メールかそうでないかを判別するシステムも、分類問題の一種です。迷惑メールの特徴を学習させることで、自動的に迷惑メールを振り分けることができるようになります。
分類問題の重要な点は、予測したい値が連続的ではなく、いくつかの種類に分けられるということです。たとえば、犬か猫かを判別する場合、答えは「犬」か「猫」のどちらかで、その中間はありません。大きさや重さのように連続的な値ではなく、「犬」「猫」といった個別の種類に分けられる値を予測する問題が、分類問題と呼ばれるのです。
このように、分類問題は機械学習の基礎となる重要な問題であり、画像認識や迷惑メール判別以外にも、医療診断や商品推薦など、様々な分野で応用されています。私たちの生活をより便利で豊かにするために、分類問題の技術は今後ますます重要になっていくでしょう。
| 分類問題とは | 具体例 | ポイント | 応用分野 |
|---|---|---|---|
| あらかじめ決められた種類にものごとを振り分ける問題 |
|
予測したい値が連続的ではなく、いくつかの種類に分けられる。 |
|
分類問題の種類

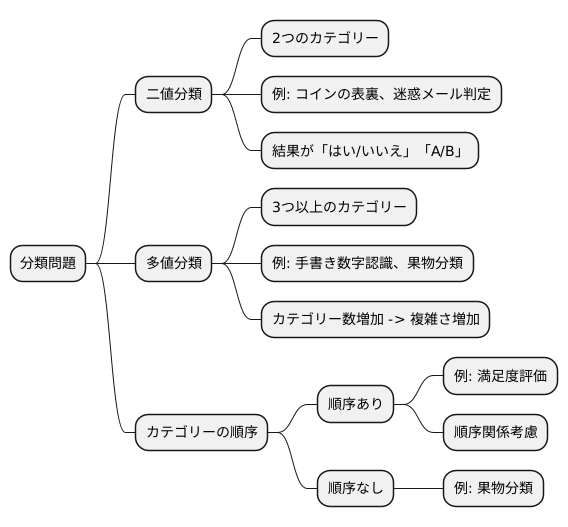
物事を種類分けする問題、いわゆる分類問題は、大きく分けて二つの種類があります。一つは二値分類、もう一つは多値分類です。この二つの違いは、分類する種類、つまりカテゴリーの数にあります。
二値分類とは、二つのカテゴリーに分ける問題です。例えば、コインを投げた時に表になるか裏になるかを予測する、送られてきた電子手紙が迷惑メールかそうでないかを判断する、といった問題が二値分類にあたります。このように、結果が「はい」か「いいえ」か、AかBか、といった二者択一の判断を行う場面で用いられます。二値分類は、比較的単純な問題設定であるため、分類問題の中でも基本的なものと言えるでしょう。
一方、多値分類とは、三つ以上のカテゴリーに分ける問題です。例えば、手書きの数字を0から9までのどれかを当てる、果物の写真を見てりんご、みかん、バナナのどれかを判断する、といった問題が該当します。二値分類と比べて、分類するカテゴリーの数が増えるため、問題の複雑さも増します。
さらに、カテゴリー同士に順番があるかないかも、分類問題を考える上で重要な要素です。例えば、商品の満足度を五段階で評価する問題を考えてみましょう。「とても満足」「満足」「普通」「不満」「とても不満」のように、それぞれのカテゴリーには順番があります。このような場合は、カテゴリー間の順序関係を考慮した特別な計算方法を使う必要があります。反対に、果物の種類を分類する問題のように、カテゴリー間に順序関係がない場合もあります。りんご、みかん、バナナのどれが上でどれが下か、といった順番は特にありません。このように、カテゴリー間に順序関係があるかないかで、適した分類方法が変わってくるため、問題の種類を見極めることが重要です。
分類問題の活用事例

ものを種類分けする分類問題は、私たちの暮らしを支える様々な場面で役立っています。例えば、医療の分野では、患者の訴える症状や検査結果といった情報から病気を診断するために使われています。医師は、患者の熱や咳、血液検査の数値などをもとに、風邪なのか、肺炎なのか、他の病気なのかを判断します。これはまさに分類問題を解いていると言えるでしょう。また、最適な治療方針を決める際にも分類問題は役立ちます。患者の状態や病気の種類に応じて、薬物治療が良いのか、手術が必要なのかなどを判断します。
金融の分野でも、分類問題は欠かせません。融資を申し込んできた人の信用度を評価する際に、過去の返済履歴や収入、資産状況といった情報から、融資を実行しても安全かどうかを判断します。さらに、クレジットカードの不正利用を見つけるためにも活用されています。普段と異なる高額な買い物や、海外での不自然な利用などを検知し、不正利用の可能性が高い取引を識別します。
販売促進に関わる分野でも、分類問題は活躍しています。顧客の過去の買い物履歴や好み、年齢や性別といった情報から、その人に合った商品を薦めることができます。インターネット通販のサイトで「あなたへのおすすめ商品」が表示されるのも、分類問題を活用した技術のおかげです。また、効果的な広告を出すためにも役立ちます。どの顧客層にどの広告を見せるのが効果的かを判断し、広告配信を最適化します。
近年では、写真や動画に写っているものを認識する技術や、言葉を理解する技術が進歩しています。これにより、これまで以上に複雑な分類問題にも対応できるようになり、活用の幅はますます広がっています。
| 分野 | 分類問題の活用例 |
|---|---|
| 医療 |
|
| 金融 |
|
| 販売促進 |
|
分類問題の解決手法

ものの種類分け問題を解く方法はいろいろあります。よく使われる方法として、決定木、サポートベクターマシン、ロジスティック回帰、神経回路網などが挙げられます。それぞれの特徴と使い分けについて詳しく見ていきましょう。
決定木は、データの特徴を元に段階的に分けていく方法です。例えるなら、いくつかの質問に「はい」か「いいえ」で答えていくことで、最終的にどの種類に当てはまるかを決めるようなものです。この方法は、まるで樹木の枝のように分岐していく様子を図で表せるため、結果が分かりやすいという長所があります。
サポートベクターマシンは、データの境界線をうまく引くことで種類分けをする方法です。高次元データ、つまりたくさんの特徴を持つデータの分類に優れています。まるで、たくさんの種類のボールが混ざっている中で、ボールの種類ごとに線を引いてきれいに区分けするようなイメージです。
ロジスティック回帰は、データがそれぞれのカテゴリーに属する確率を計算する方法です。例えば、ある果物がリンゴである確率、ミカンである確率などを計算し、一番確率の高いカテゴリーに分類します。この方法は、結果が確率として表されるため、どの程度確信を持って分類されたかが分かりやすいという利点があります。
神経回路網は、人間の脳の神経細胞のつながりをまねた仕組みです。複雑な関係を持つデータでも学習することができ、特に近年の深層学習の発展により、画像認識や自然言語処理などで高い成果を上げています。他の方法では捉えきれない、複雑なデータの特徴を学習できることが強みです。
これらの方法は、それぞれ得意とするデータの種類や問題の性質が違います。そのため、どの方法を選ぶかが、問題をうまく解く鍵となります。最近では、深層学習を使った神経回路網による分類方法が注目を集めており、高い正答率を達成しています。
| 分類方法 | 説明 | 長所/特徴 |
|---|---|---|
| 決定木 | データの特徴を元に段階的に分けていく方法。 | 結果が分かりやすい(樹形図で表現できる) |
| サポートベクターマシン | データの境界線をうまく引くことで種類分けをする方法。 | 高次元データの分類に優れている |
| ロジスティック回帰 | データがそれぞれのカテゴリーに属する確率を計算する方法。 | 結果が確率で表され、確信度が分かりやすい |
| 神経回路網(深層学習) | 人間の脳の神経細胞のつながりをまねた仕組み。 | 複雑な関係を持つデータでも学習でき、特に画像認識や自然言語処理で高い成果。 |
分類問題の評価指標

様々な種類がある分類モデルですが、その良し悪しを測るには、どれほど正確に分類できているかを示す指標が必要です。どのような目的にモデルを使うかによって、重視すべき指標も変わってきます。代表的な指標をいくつか紹介します。まず「正解率」は、全体の中でどれだけのデータを正しく分類できたかを示す、最も基本的な指標です。しかし、データの偏りがある場合には、この指標だけでは不十分な場合があります。例えば、ある病気の患者が1%しかいない集団を対象に、全員を「病気でない」と予測するモデルを考えてみましょう。このモデルの正解率は99%と非常に高い値になりますが、病気の患者を一人も見つけることができていないため、診断には全く役に立ちません。
次に、「適合率」と「再現率」という二つの指標を見てみましょう。「適合率」は、ある分類モデルが「病気である」と判断した人の中で、実際に病気だった人の割合を示します。つまり、モデルの判断の確実性を表す指標と言えるでしょう。一方、「再現率」は、実際に病気である人の中で、モデルが「病気である」と正しく判断できた人の割合を示します。これは、見落としをどれだけ少なくできるかを示す指標です。先ほどの病気の例で考えると、全員を「病気でない」と予測するモデルの再現率は0%になります。
「適合率」と「再現率」は、トレードオフの関係にあることが多く、どちらかを高くしようとすると、もう一方が低くなる傾向があります。例えば、適合率を高めるためには、より確実に「病気である」と判断できる場合にのみ陽性と予測すればよいですが、そうすると実際に病気の人を見落とす可能性が高くなり、再現率は低下します。逆に、再現率を高めるためには、少しでも病気の疑いがあれば陽性と予測すればよいですが、そうすると誤診が増え、適合率は低下します。そこで、これらのバランスを考えた指標として「F値」があります。F値は、適合率と再現率の調和平均で、両者のバランスを考慮した指標です。目的に応じて、これらの指標を使い分けることが重要です。病気の診断のように、偽陰性を避けたい場合は再現率を重視し、スパムメールの検知のように、偽陽性を避けたい場合は適合率を重視します。
| 指標名 | 説明 | 用途 |
|---|---|---|
| 正解率 | 全体の中でどれだけのデータを正しく分類できたかを示す基本的な指標 | データの偏りが少ない場合 |
| 適合率 | モデルが陽性と判断した中で、実際に陽性だった割合 | 偽陽性を避けたい場合 (例: スパムメール検知) |
| 再現率 | 実際に陽性である中で、モデルが正しく陽性と判断できた割合 | 偽陰性を避けたい場合 (例: 病気の診断) |
| F値 | 適合率と再現率の調和平均 | 適合率と再現率のバランスを取りたい場合 |