
勾配ブースティングで予測精度を高める

AIを知りたい
先生、『勾配ブースティング』って、ブースティングに勾配降下法を使ったものですよね?具体的に勾配降下法はどういう役割を持っているんでしょうか?

AIエンジニア
いい質問だね。ブースティングは弱学習器をたくさん組み合わせて強力な学習器を作る手法だけど、ただ組み合わせるだけじゃなく、前の学習器の誤りを次の学習器で修正していくことが重要なんだ。その修正を効率的に行うために勾配降下法を使うんだよ。
AIを知りたい
効率的に修正する、というと?
AIエンジニア
そうだな。目標値と予測値の差を最小にするのが目的だけど、勾配降下法を使うことで、その差が小さくなる方向へ効率的に弱学習器を修正していけるんだ。いわば、最短ルートで正解に近づいていくようなイメージだね。
勾配ブースティングとは。
人工知能の分野でよく使われる『勾配ブースティング』という言葉について説明します。ブースティングとは、あまり精度が高くない学習器を順番に学習させていく方法です。前の学習器が間違えて分類したデータを、次の学習器がうまく分類できるように、データの重要度を調整しながら学習を進めます。勾配ブースティングは、それぞれのデータの正しい値と予測値の差をまとめた目的関数を最小にするために、勾配降下法という手法を使います。
勾配ブースティングとは

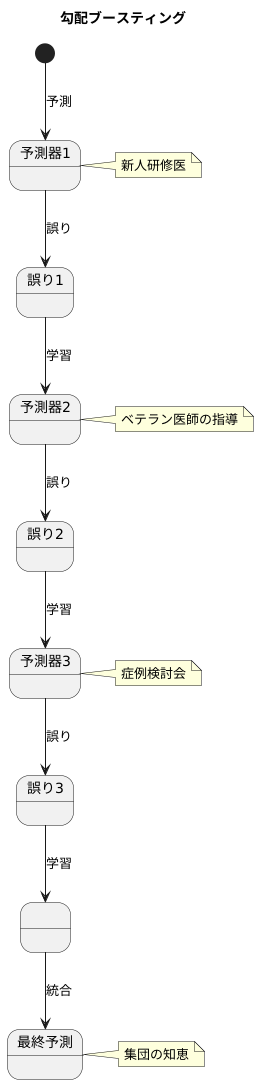
勾配ブースティングは、機械学習の分野で、予測の正確さを高めるための強力な手法です。複数の比較的単純な予測器を組み合わせ、徐々に全体の予測能力を向上させていくという考え方が基本となっています。それぞれの単純な予測器は、単独ではそれほど高い予測精度を持ちません。例えるなら、新人研修医のように、経験が浅いため診断の正確さも限られています。しかし、勾配ブースティングでは、これらの新人のような予測器を段階的に育成していくのです。
まず、最初の予測器が作られ、データに基づいて予測を行います。当然、この予測には誤りが含まれています。次に、二番目の予測器は、最初の予測器の間違いを重点的に学習します。どこに誤りがあったのか、どのように修正すれば良いのかを学ぶことで、より正確な予測ができるようになるのです。これは、ベテラン医師が研修医の誤診を分析し、指導するのと似ています。
さらに三番目、四番目と、新しい予測器が次々と追加され、前の予測器の誤りを修正していくことで、全体の予測精度は徐々に高まっていきます。これは、多くの医師が症例検討会で議論を重ね、より正確な診断を導き出す過程に似ています。各医師の意見を統合することで、より確度の高い結論に至るように、勾配ブースティングも多くの予測器を組み合わせることで、高い予測精度を実現するのです。このように、勾配ブースティングは、複雑な問題を解決するために、集団の知恵を活用する手法と言えるでしょう。
ブースティングの仕組み

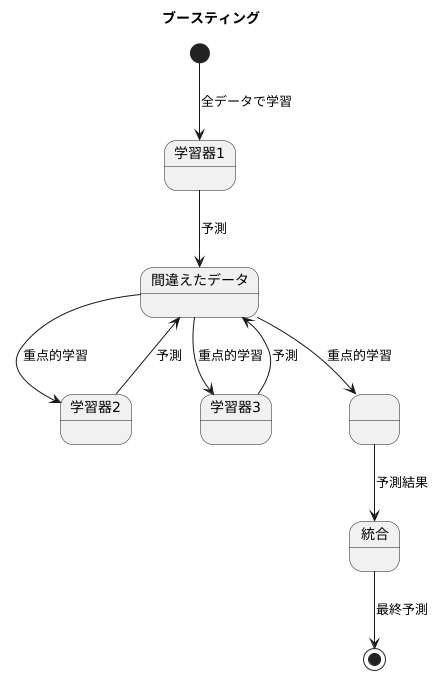
ブースティングとは、複数の弱い学習器を組み合わせることで、高い予測精度を持つ強力な学習器を作る手法です。弱い学習器とは、単独では精度が低い学習器のことを指します。まるで、スポーツチームで言えば、一人ひとりの選手はそれほど優れていなくても、チームとして協力することで大きな成果を出せるようなものです。
ブースティングでは、まず最初の弱い学習器を、与えられた全てのデータを使って学習させます。この学習器は、データ全体を予測しますが、まだ精度は高くありません。まるで、スポーツチームが初めて全体練習をするようなもので、個々の選手の動きはまだぎこちなく、チームとしての連携も取れていません。
次に、最初の学習器が間違えてしまったデータに注目します。まるで、チームのコーチが試合のビデオを見て、チームの弱点を見つけるようなものです。そして、この間違えやすいデータを重点的に学習するような、次の弱い学習器を作ります。これは、コーチがチームの弱点克服のための練習メニューを作るようなものです。
この手順を何度も繰り返します。前の学習器が苦手としたデータを、次の学習器が補うように学習していくことで、全体として徐々に精度が上がっていきます。まるで、チームが弱点克服のための練習を繰り返すことで、チーム全体の能力が向上していくようなものです。
最終的には、それぞれの弱い学習器の予測結果を組み合わせ、最終的な予測を出します。これは、試合でそれぞれの選手が自分の役割をこなし、チームとして勝利を目指すようなものです。それぞれの学習器が、データの異なる側面を捉えることで、全体として高い精度を実現できるのです。
勾配降下法と勾配ブースティング

勾配降下法と勾配ブースティング、これらは機械学習の分野でよく耳にする言葉です。一見似ているようですが、実際には異なる役割を担っています。勾配降下法は、ある関数の最小値を見つけるための手法です。例えるなら、深い霧の中にいるとしましょう。目の前は真っ白で、どこが低い場所なのか分かりません。しかし、足元の傾きを感じながら、少しずつ低い方へ低い方へと進んでいくことで、最終的には谷底にたどり着くことができます。この「足元の傾き」が勾配であり、それを利用して最小値を探すのが勾配降下法です。
一方、勾配ブースティングは、複数の弱い予測モデルを組み合わせて、より強力な予測モデルを作る手法です。個々のモデルは、霧の中で少しだけ見える範囲で進む方向を示す標識のようなものです。一つ一つの標識は不完全で、遠くまでは見えません。しかし、複数の標識を参考にしながら進むことで、より正確に目的地にたどり着くことができます。
では、勾配降下法と勾配ブースティングはどのように関係しているのでしょうか?勾配ブースティングでは、新しい予測モデルを追加する際に、勾配降下法を用いて最適なパラメータを決定します。具体的には、現在の予測と実際の値の差、つまり誤差を計算します。この誤差を最小にするように、新しいモデルのパラメータを調整するのです。この調整は、霧の中の傾きを参考にしながら進むのと同様に、勾配降下法を用いて行われます。つまり勾配ブースティングは、勾配降下法を「より良い予測モデルを作る」という目的のために利用しているのです。このように、勾配降下法は、勾配ブースティングという強力な手法を支える重要な役割を担っています。
| 項目 | 説明 | 例え |
|---|---|---|
| 勾配降下法 | 関数の最小値を見つける手法 | 霧の中で足元の傾きを感じながら谷底を探す |
| 勾配ブースティング | 複数の弱い予測モデルを組み合わせて、強力な予測モデルを作る手法 | 霧の中で複数の標識を参考にしながら目的地を目指す |
| 両者の関係 | 勾配ブースティングは、新しいモデルを追加する際に、勾配降下法を用いて最適なパラメータを決定する | – |
様々な勾配ブースティング

勾配ブースティングとは、決定木をたくさん組み合わせることで、高い予測精度を実現する手法です。いくつか種類があり、代表的なものにエックス・ジー・ブースト、ライト・ジー・ビー・エム、キャット・ブーストなどがあります。これらは基本的な考え方は同じですが、それぞれに工夫が凝らされており、計算の速さや正確さといった特徴が違います。
まず、エックス・ジー・ブーストは、様々な工夫によって勾配ブースティングの計算を速くした手法です。従来の勾配ブースティングでは計算に時間がかかっていましたが、エックス・ジー・ブーストでは、並列処理や近似計算といった技術を使うことで、計算時間を大幅に短縮することに成功しました。このため、大規模なデータや複雑なモデルにも対応できるようになりました。
次に、ライト・ジー・ビー・エムは、エックス・ジー・ブーストよりもさらに計算を速くするために、度数分布表に基づく方法を取り入れています。度数分布表とは、データをいくつかの区間に分けて、それぞれの区間に含まれるデータの数を表にしたものです。ライト・ジー・ビー・エムでは、この度数分布表を使って計算を行うことで、計算量を減らし、高速化を実現しています。特に、データの数が非常に多い場合に効果を発揮します。
最後に、キャット・ブーストは、種類を表す変数を効率よく扱うことができるように設計された手法です。種類を表す変数とは、例えば「色」や「性別」といった、数値ではないデータのことです。従来の勾配ブースティングでは、種類を表す変数を数値に変換する必要がありましたが、キャット・ブーストでは、種類を表す変数を直接扱うことができます。そのため、データの前処理の手間を省くことができ、より正確な予測を行うことができます。
このように、勾配ブースティングには様々な手法があり、それぞれに得意な点があります。データの量や種類、求める精度などに応じて、適切な手法を選ぶことが重要です。
| 手法 | 特徴 | 工夫 |
|---|---|---|
| エックス・ジー・ブースト (XGBoost) | 高速な計算 | 並列処理、近似計算 |
| ライト・ジー・ビー・エム (LightGBM) | さらに高速な計算 | 度数分布表に基づく計算 |
| キャット・ブースト (CatBoost) | 種類を表す変数を効率的に処理 | 種類を表す変数を直接扱う |
勾配ブースティングの利点

勾配ブースティングは、様々な分野で活用されている強力な予測手法であり、多くの利点を持ち合わせています。その中でも特に注目すべきは、高い予測精度です。勾配ブースティングは、複数の弱い学習器(予測能力の低いモデル)を組み合わせることで、高い精度を実現します。それぞれの学習器は、前の学習器の誤りを修正するように学習していくため、最終的には非常に正確な予測を可能にします。
また、勾配ブースティングは、様々な種類のデータに対応できる柔軟性も大きな魅力です。数値データだけでなく、カテゴリデータや欠損値を含むデータにも対応できるため、データの前処理にかかる手間を減らすことができます。さらに、データの特性に合わせて様々な損失関数を設定できるため、個々の問題に最適化したモデルを構築できます。この柔軟性により、勾配ブースティングは、幅広い分野のデータ分析で力を発揮します。
さらに、勾配ブースティングは、比較的少ないパラメータ調整で高い性能を発揮します。他の機械学習手法では、最適なパラメータを見つけるために複雑な調整が必要となる場合がありますが、勾配ブースティングは自動的に調整される部分が多く、利用者の負担を軽減します。そのため、機械学習の専門家でなくても、比較的容易に扱うことができます。
このように、高い予測精度、データへの柔軟性、そして使いやすさといった多くの利点を持つ勾配ブースティングは、データ分析において非常に強力な手法と言えるでしょう。そのため、ビジネスの意思決定支援や、将来予測など、様々な場面で活用が期待されています。
| 利点 | 説明 |
|---|---|
| 高い予測精度 | 複数の弱い学習器を組み合わせ、前の学習器の誤りを修正するように学習することで、高い精度を実現 |
| データへの柔軟性 | 数値データ、カテゴリデータ、欠損値を含むデータなど、様々な種類のデータに対応可能。様々な損失関数を設定することで、個々の問題に最適化できる。 |
| 使いやすさ | パラメータ調整が比較的少なく、自動的に調整される部分が多い。 |
勾配ブースティングの応用例

勾配ブースティングは、機械学習の中でも特に優れた予測能力を持つ手法として、様々な分野で活用が広がっています。その応用例をいくつか詳しく見ていきましょう。
まず、金融分野では、顧客の信用リスク評価に勾配ブースティングが役立っています。顧客の年齢、収入、過去の取引履歴などのデータに基づいて、将来債務不履行を起こす可能性を予測することで、融資の可否判断や金利設定をより的確に行うことができます。これにより、金融機関はリスク管理を強化し、健全な経営を維持することが可能になります。
次に、医療分野を見てみましょう。勾配ブースティングは、画像診断データや患者の病歴、検査結果など膨大な情報を分析し、病気の早期発見や診断精度の向上に貢献しています。例えば、がんの早期発見や、心臓病のリスク評価などに活用されています。また、個々の患者に最適な治療方針を決定するのにも役立ち、医療の質向上に大きく貢献しています。
マーケティング分野でも、勾配ブースティングは広く活用されています。顧客の購買履歴やウェブサイトの閲覧履歴、年齢や性別などの属性情報に基づいて、顧客がどのような商品に興味を持っているかを予測し、個々に合わせた広告配信や商品推薦を行うことができます。これにより、企業は販売促進効果を高め、顧客満足度向上につなげることができます。
このように、勾配ブースティングは、様々な分野で予測精度を高めるために活用されており、私たちの生活をより豊かに、そして安全なものにするために貢献しています。今後、データ量の増加や技術の進歩に伴い、さらに応用範囲が広がり、社会に大きな影響を与えていくと期待されています。
| 分野 | 勾配ブースティングの応用例 | 効果 |
|---|---|---|
| 金融 | 顧客の信用リスク評価(融資可否判断、金利設定) | リスク管理強化、健全な経営維持 |
| 医療 | 病気の早期発見、診断精度の向上(例:がん、心臓病)、最適な治療方針決定 | 医療の質向上 |
| マーケティング | 顧客の興味予測に基づいた広告配信、商品推薦 | 販売促進効果向上、顧客満足度向上 |