
ブートストラップサンプリングで精度向上

AIを知りたい
先生、「ブートストラップサンプリング」って、一部のデータだけを使って学習するんですよね?どうして全部のデータを使わないんですか?

AIエンジニア
良い質問だね。全部のデータを使うと、そのデータだけに過剰に適応してしまう「過学習」が起こる可能性があるんだ。一部のデータを使うことで、様々なデータに柔軟に対応できるようになるんだよ。
AIを知りたい
なるほど。でも、一部のデータだけだと、学習が不十分になるんじゃないですか?
AIエンジニア
ブートストラップサンプリングは、一部のデータを使うと言っても、ランダムに何度も繰り返すことで、結果的にほとんど全てのデータが学習に使われることになるんだ。さらに、同じデータが何度も使われることもあるんだよ。
ブートストラップサンプリングとは。
『ブートストラップサンプリング』という人工知能で使われる言葉について説明します。これは、学習の際に全てのデータを使うのではなく、それぞれの決定木に対して、無作為に一部のデータを選び出して学習を行う方法のことです。
データの選び方

機械学習では、良い予測をするためには、たくさんのデータが必要です。しかし、ただ闇雲に多くのデータを使えば良いというわけではありません。むしろ、データが多すぎると、学習に時間がかかったり、「過学習」という問題が起こる可能性があります。過学習とは、まるで試験のヤマを張りすぎて、試験範囲全体を理解できていない状態のようなものです。学習に使ったデータに対しては完璧な答えを出せても、新しいデータに対してはうまく対応できないのです。
そこで、データの選び方が重要になります。すべてのデータを一度に使うのではなく、一部のデータだけをうまく選んで学習に使うことで、過学習を防ぎ、より良い予測モデルを作ることができます。そのための方法の一つが、「ブートストラップサンプリング」と呼ばれる手法です。
ブートストラップサンプリングは、たくさんのデータの中から、ランダムに一部のデータを選び出す方法です。まるで、くじ引きのように、偶然に選ばれたデータを使って学習を行います。このくじ引きを何度も繰り返すことで、毎回異なるデータの組み合わせで学習することになります。
例えるなら、限られた種類の食材で、様々な料理を作るようなものです。同じ食材でも、組み合わせや調理方法を変えることで、色々な料理が作れます。ブートストラップサンプリングも同様に、限られたデータから多様なモデルを作ることを可能にします。それぞれのモデルは、異なるデータで学習しているので、それぞれ違った特徴を持っています。これらの多様なモデルを組み合わせることで、より精度の高い、安定した予測が可能になるのです。まるで、複数の専門家の意見を聞いて、より良い判断をするように、多様なモデルの集合知を活用することで、未知のデータに対しても精度の高い予測ができるようになります。
手法の仕組み

この手法は、たくさんのデータの中から、一部のデータを何度も繰り返し取り出すことで、擬似的にたくさんのデータセットを作ります。まるで、たくさんの種類の飴が入った袋から、飴を一つずつ取り出しては袋に戻す作業を繰り返すようなものです。同じ飴が何度も選ばれることもありますが、袋の中身と似たような割合で飴が選ばれます。この手法を「ブートストラップサンプリング」といいます。
ブートストラップサンプリングでは、元のデータの大きさと同じ数のデータを、重複を許しながら取り出します。例えば、10個のデータがある場合、10個のデータをランダムに選びます。1つ目のデータを選ぶとき、10個の中からどれか1つを選びます。そして、選んだデータを元の場所に戻し、再び10個の中から1つを選びます。これを10回繰り返します。このとき、同じデータが複数回選ばれる可能性があるというのが重要な点です。
こうして作られた新しいデータセットは、元のデータの性質をよく反映したものになります。元のデータの中に、ある特徴を持つデータが多ければ、新しいデータセットにも、その特徴を持つデータが多く含まれる可能性が高くなります。逆に、元のデータの中に、ある特徴を持つデータが少なければ、新しいデータセットにも、その特徴を持つデータは少なくなるでしょう。
ブートストラップサンプリングで重要なのは、データを何度も繰り返し取り出す点と、取り出したデータを毎回元に戻す点です。これにより、元のデータの分布を維持しながら、ランダム性を加える効果があります。そして、このランダム性が、様々な決定木を作成する上で重要な役割を果たします。それぞれの決定木は、少しずつ異なるデータセットから作られるため、多様な結果が得られます。これらの結果を組み合わせることで、より信頼性の高い予測を行うことができます。
予測精度の向上

予測の正確さをより高めるために、たくさんの小さなデータの集まりをたくさん作って、それぞれで予測のやり方を学び取る方法があります。
この方法は、元のデータから一部を取り出して、同じ大きさの新しいデータの集まりをたくさん作ることで実現します。まるで、元となるデータから、少しづつ材料を集めて、同じ大きさの料理をたくさん作るようなものです。それぞれの料理は似ていますが、材料の組み合わせが少しづつ異なるため、少しずつ味が変わります。これと同じように、それぞれの小さなデータの集まりは元のデータと似ていますが、少しずつ内容が異なるため、それぞれで学習した予測のやり方も少しずつ変わってきます。
このようにして作られた、たくさんの予測のやり方を組み合わせることで、より正確な予測をすることができます。これは、たくさんの人が集まって、それぞれが自分の得意な方法で問題を解決しようとする様子に似ています。人によって得意なことが違うため、色々な解決策が出てきます。これらの解決策を組み合わせることで、より良い答えを見つけられる可能性が高まります。
この方法は、元のデータの中にたまたま偏りや間違いが含まれていたとしても、その影響を少なくすることができます。たとえば、一部のデータに偏りがあったとしても、たくさんの小さなデータの集まりを作る過程で、その偏りが薄められるからです。これは、たくさんの人の意見を聞くことで、一部の人の偏った意見に左右されにくくなるのと同じです。
このように、たくさんの小さなデータの集まりを使って予測のやり方を学ぶことで、より正確で、偏りの少ない予測が可能になります。まるで、たくさんの専門家の意見を総合して、より良い判断を下すように、様々な予測のやり方を組み合わせることで、予測の信頼性を高めることができるのです。
ランダムフォレストとの関係
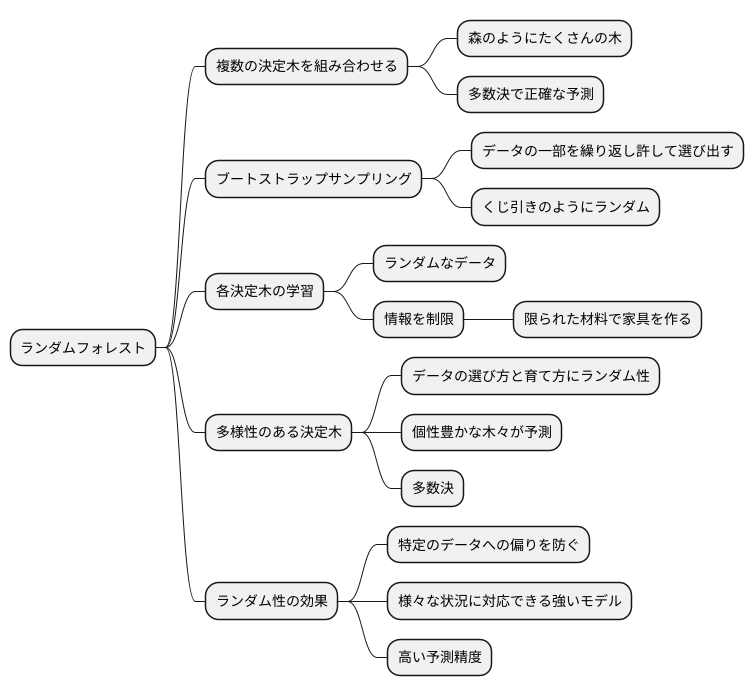
ランダムフォレストは、複数の決定木を組み合わせて強力な予測モデルを作る手法です。まるで森のようにたくさんの木を組み合わせるため、この名前が付けられています。一つ一つの木はそれほど賢くなくても、たくさんの木々が多数決をとることで、驚くほど正確な予測ができます。
このランダムフォレストで重要な役割を果たすのが、ブートストラップサンプリングというデータの選び方です。たくさんのデータの中から、一部のデータを繰り返し許して選び出す方法です。同じデータが何度も選ばれることもあれば、全く選ばれないデータもあります。まるでくじ引きのようなもので、偶然によって選ばれたデータでそれぞれの木を育てます。
こうして集められたデータで、それぞれの決定木が学習していきます。しかし、データを選ぶだけでなく、木の成長にもランダム性を取り入れます。それぞれの木では、使える情報の種類も制限します。全ての情報を使うのではなく、一部の情報だけを使って木を育てます。まるで、限られた材料だけで家具を作るようなものです。
このように、データの選び方と木の育て方にランダム性を取り入れることで、一つ一つの木の特徴が少しずつ異なってきます。そして、これらの個性豊かな木々が、それぞれの予測結果を出し合い、最終的に多数決で最も有力な答えを選びます。
ランダム性を加えることで、一つ一つの木が特定のデータに偏ってしまうことを防ぎ、全体としてバランスの取れた、様々な状況に対応できる強い予測モデルを作ることができるのです。この仕組みにより、ランダムフォレストは、様々な分野で高い予測精度を発揮し、多くの問題解決に役立っています。
過学習への対策

機械学習の模型作りでは、学習し過ぎに気を付けなければなりません。学習し過ぎとは、練習問題にぴったり合いすぎて、本番の問題が解けなくなる状態のことです。まるで、教科書の例題だけを暗記して、応用問題が解けない生徒のようです。
この学習し過ぎを防ぐ良い方法の一つに、復元抽出法があります。これは、持っている練習問題の一部を使って、小さな模型をたくさん作る方法です。全体を一度に使うのではなく、一部を使うことで、特定の問題に偏ることなく、色々な問題に対応できる模型を作ることができます。
例えば、算数の練習問題を解くとします。足し算、引き算、掛け算、割り算の問題集から、ランダムにいくつか選んで小さな問題集をたくさん作ります。それぞれの小さな問題集で練習することで、特定の種類の問題に特化することなく、どんな問題が出ても対応できる力が身につきます。全体を一度に使うと、たまたま多かった問題の解き方に偏ってしまうかもしれません。
復元抽出法も同じ考え方です。色々な小さな模型を作ることで、特定のデータに引っ張られることなく、色々なデータに対応できる、バランスの取れた模型を作ることができます。
これは、色々な経験を積むことで、どんな状況にも対応できるようになることに似ています。一つのことに集中するよりも、色々なことに挑戦することで、応用力が身につき、新しい問題にも対応できるようになります。復元抽出法は、機械学習の模型をより実用的にするために、重要な役割を果たしているのです。
様々な応用事例

ブートストラップサンプリングは、もとのデータから何度も繰り返しデータを抜き出すことで、擬似的にたくさんのデータを作り出す方法です。この方法は、様々な分野で広く使われており、その応用範囲は年々広がっています。
医療の分野では、病気の診断や治療方針の決定に役立てられています。例えば、ある病気の診断精度を評価したい場合、限られた患者さんのデータから何度も無作為抽出を繰り返すことで、たくさんの仮想的な患者集団を作ることができます。それぞれの集団で診断精度を計算し、そのばらつきを見ることで、もとのデータから得られた診断精度の信頼性を評価できます。また、新しい治療法の効果を検証する場合にも、ブートストラップサンプリングを使って効果のばらつきを推定することで、より確かな結論を導き出すことが可能になります。
金融の分野では、リスク評価や不正検知などに活用されています。例えば、ある金融商品の価格変動リスクを評価する場合、過去の価格変動データから何度も無作為抽出を行い、様々な市場状況を模擬することで、より正確なリスク評価ができます。また、クレジットカードの不正利用を検知するシステムにも、ブートストラップサンプリングが利用されています。正常な取引と不正な取引のデータからそれぞれ無作為抽出を繰り返し、不正検知モデルの精度を向上させることができます。
販売促進の分野では、顧客の購買行動の予測や商品推薦などに使われています。例えば、顧客の過去の購買履歴データから無作為抽出を繰り返し、顧客の将来の購買行動を予測するモデルを構築できます。これにより、顧客一人ひとりに合わせた最適な商品推薦を行うことが可能になります。また、新しい商品の売れ行き予測にもブートストラップサンプリングが役立ちます。限られた市場調査データから様々な市場反応を模擬することで、より精度の高い予測を行うことができます。このように、ブートストラップサンプリングは、限られたデータからでも多くの情報を取り出し、様々な分野で意思決定を支援する強力な手法となっています。
| 分野 | ブートストラップサンプリングの活用例 |
|---|---|
| 医療 | 病気の診断精度評価、新しい治療法の効果検証 |
| 金融 | リスク評価、不正検知 |
| 販売促進 | 顧客の購買行動予測、商品推薦、新商品の売れ行き予測 |