
二者択一を見極める技術

AIを知りたい
先生、『2クラス分類モデル』って、どんなものですか?

AIエンジニア
簡単に言うと、データを見て、それがAかBかを決めるモデルのことだよ。例えば、メールを見て、それが迷惑メールか普通のメールか判断する、といったことだね。
AIを知りたい
つまり、2つのグループに分けられるものなら、何でも判断できるってことですか?
AIエンジニア
そうだね。猫の画像か犬の画像か、写真の顔が笑顔かそうでないか、といったように、色々なものに応用できるよ。もちろん、モデルを作るためには、たくさんのデータで学習させる必要があるけどね。
2クラス分類モデルとは。
人工知能でよく使われる言葉に「二つの種類に仕分ける模型」というものがあります。これは、機械学習という方法で、データがどちらのグループに当てはまるのかを二つに分けるための模型のことです。
二つのグループに分ける

私たちは日常生活の中で、知らず知らずのうちに様々なものを二つに分けて考えています。朝、目を覚まして窓の外を見た時、空模様から傘が必要かどうかを判断するのは、天気を晴れか雨かの二つのグループに無意識に分類していると言えるでしょう。傘が必要だと感じれば、雨のグループに分類され、必要ないと感じれば晴れのグループに分類されるのです。
このような二つのグループに分けるという行為は、コンピューターの世界でも活用されています。「二者分類モデル」と呼ばれる技術は、まさにこの考え方に基づいて作られています。大量のデータの中から、ある特徴を持つものと持たないものを自動的に分類するのです。例えば、迷惑メールの判別を想像してみてください。受信したメールを迷惑メールかそうでないかの二つのグループに振り分けることで、重要なメールだけを確認することができるようになります。毎日大量のメールが届く現代社会において、これは非常に便利な機能と言えるでしょう。
また、商品の売れ行き予測にもこの技術は役立ちます。過去のお客様の購入履歴や商品の情報などを分析することで、売れる商品か売れない商品かを予測することが可能になります。この予測に基づいて商品の仕入れ量を調整すれば、売れ残りを減らし、利益を最大化することに繋がります。このように、二者分類モデルは、様々な場面で私たちの生活をより便利で豊かにするための重要な技術と言えるでしょう。
| 場面 | グループA | グループB | メリット |
|---|---|---|---|
| 日常生活 | 晴れ | 雨 | 傘の必要性を判断 |
| 迷惑メール判別 | 迷惑メール | 迷惑メール以外 | 重要なメールだけを確認 |
| 商品の売れ行き予測 | 売れる商品 | 売れない商品 | 売れ残り減少、利益最大化 |
様々な活用事例

二者分類モデルは、様々な分野で活用され、私たちの生活をより良くするために役立っています。
医療分野では、病気の診断支援に役立っています。例えば、レントゲン写真を見ることで肺炎があるかないかを判断したり、CTで撮影した体の内部の画像から腫瘍が悪性なのか良性なのかを見分けたりする際に使われています。これにより、医師はより正確で迅速な診断を行うことが可能になり、患者の早期発見・早期治療につながります。また、心電図データから心臓の異常を検知するシステムにも応用されており、病気の予防にも貢献しています。
金融業界では、融資の判断をより的確に行うために活用されています。顧客の過去の取引の記録や収入といった情報をもとに、お金をきちんと返せるかどうかを予測することで、貸し倒れのリスクを減らすことができます。これにより、金融機関は安全な経営を続けながら、より多くの人に融資を行うことが可能になります。
マーケティング分野では、広告の効果を高めるために活用されています。顧客の年齢や性別、過去の買い物履歴といったデータから、ある商品を買う可能性が高い人を特定し、その人に合わせた広告を出すことができます。そのため、無駄な広告を減らし、より効果的に商品を宣伝することが可能になります。例えば、ある人がインターネットでよく服を見ていれば、その人に服の広告を出すといった具合です。
このように、二者分類モデルは様々な分野で活用され、私たちの生活を支えています。今後、技術の進歩とともに、さらに多くの分野で活用され、より便利な社会の実現に貢献していくと考えられます。
| 分野 | 活用例 | メリット |
|---|---|---|
| 医療 | ・レントゲン写真から肺炎の診断 ・CT画像から腫瘍の良悪性の判断 ・心電図データから心臓異常の検知 |
・医師の診断の正確性と迅速性の向上 ・病気の早期発見・早期治療 ・病気の予防 |
| 金融 | ・顧客の信用リスク評価による貸し倒れリスクの軽減 | ・金融機関の安全な経営 ・より多くの人への融資 |
| マーケティング | ・顧客の購買予測に基づいた targeted advertising | ・広告効果の向上 ・無駄な広告の削減 |
モデルを作る方法

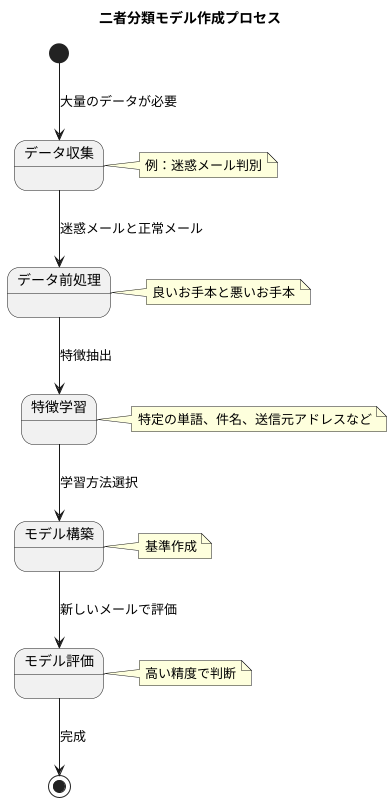
二者分類モデルを作る工程は、ちょうど子供が言葉を覚える過程によく似ています。まず、大量のデータが必要です。例えば、迷惑メールを判別するモデルを作る場合を考えてみましょう。この場合、迷惑メールとそうでないメール、両方のデータが必要です。迷惑メールだけを集めても、何が迷惑メールではないのかを学ぶことはできません。良いお手本と悪いお手本の両方が必要なのです。データは多ければ多いほど、モデルの精度は上がります。百通のメールで学習するよりも、千通、一万通と学習した方が、より正確に迷惑メールを見分けられるようになります。
集めたデータを元に、モデルは迷惑メールの特徴を学習していきます。この学習は、人間が様々な経験を通して知識や判断力を身につけるのと似ています。迷惑メールには、特定の単語が含まれていたり、件名が特徴的だったり、送信元のメールアドレスに共通点があったりといった、様々な特徴があります。モデルは、これらの特徴をデータから自動的に抽出します。この作業は、データの中から共通する規則やパターンを見つけるようなものです。大量のデータから、まるで砂金を探すように、重要な特徴を見つけ出すのです。
学習方法には様々な種類がありますが、基本的にはデータから迷惑メールの特徴を抽出し、それをもとに迷惑メールかそうでないかを判断する基準を作るという作業になります。十分な量のデータで学習させたモデルは、新しいメールを受け取った時に、それが迷惑メールかどうかを高い精度で判断できるようになります。まるで経験豊富な郵便局員が、一目で怪しい手紙を見分けるように、モデルも大量のデータから得た経験を活かして判断を下すのです。このようにして作られた二者分類モデルは、様々な場面で活用されています。
モデルの精度を測る

機械学習で作られた予測模型の良し悪しを見極めることは、模型を実際に役立てる上で非常に大切です。模型の正確さを測る物差しはいくつかありますが、ここでは二つの選択肢から答えを選ぶ、二者分類模型について、よく使われる指標を説明します。
まず「精度」は、模型がどれくらい正解できたかを示す全体的な指標です。たくさんのデータの中で、どれだけの割合で正しく分類できたかを表します。しかし、精度だけでは模型の性能を完全に把握することはできません。例えば、滅多に起こらない事象を予測する場合、常に「起こらない」と予測するだけでも精度は高くなりますが、肝心の「起こる」という予測は全くできません。
そこで、「適合率」と「再現率」という二つの指標が登場します。適合率は、模型が「起こる」と予測した中で、実際に起こったものの割合を示します。一方、再現率は、実際に起こった事象のうち、模型が正しく「起こる」と予測できた割合を示します。病気の診断を例に考えると、適合率は「病気と診断された人の中で、実際に病気だった人の割合」、再現率は「実際に病気の人の中で、病気と診断された人の割合」を表します。
適合率と再現率はトレードオフの関係にあることが多く、どちらか一方を高くしようとすると、もう一方が低くなる傾向があります。そこで、両方のバランスを考えた指標として「F値」が使われます。F値は、適合率と再現率の調和平均で計算され、両方の値が共に高いほど、F値も高くなります。
これらの指標をうまく活用することで、模型の強みと弱みを理解し、目的に合った模型を作ることができます。また、一度作った模型をずっと使い続けるのではなく、定期的に見直し、データの変化や周りの状況に合わせて調整していくことが、常に高い予測精度を保つ秘訣です。
| 指標名 | 説明 | 例(病気の診断) |
|---|---|---|
| 精度 | 模型がどれくらい正解できたかを示す全体的な指標。たくさんのデータの中で、どれだけの割合で正しく分類できたかを表す。 | – |
| 適合率 | 模型が「起こる」と予測した中で、実際に起こったものの割合。 | 病気と診断された人の中で、実際に病気だった人の割合 |
| 再現率 | 実際に起こった事象のうち、模型が正しく「起こる」と予測できた割合。 | 実際に病気の人の中で、病気と診断された人の割合 |
| F値 | 適合率と再現率の調和平均。両方の値が共に高いほど、F値も高くなる。 | – |
より良いモデルを目指して

二つの選択肢から一つを選ぶ、二者分類モデルを作る方法は実に様々です。統計的な手法を用いる方法や、データの構造を学習する方法など、多くのやり方があります。
例えば、統計的な手法の一つである「回帰分析」は、過去のデータから二つの選択肢それぞれへの関連性を数値化し、将来の予測に役立てます。また、「サポートベクターマシン」という手法は、データの境界線を巧みに見つけ出し、どちらの選択肢に属するかを明確に区別します。さらに、「決定木」という手法は、まるで樹木の枝のようにデータを段階的に分類し、最終的に二つの選択肢に振り分けます。
どの手法にも、それぞれ向き不向きがあります。扱うデータの特性に合わせて、最適な手法を選ぶことが大切です。例えば、データの中に外れ値と呼ばれる特殊なデータが多い場合は、それに強い手法を選ぶ必要があります。
モデルの精度を上げるためには、データの前処理も重要です。前処理とは、いわば料理の下ごしらえのようなものです。データに欠けている部分があれば補い、不要な情報があれば取り除きます。そうすることで、モデルがデータの特徴をより正確に捉えられるようになります。
さらに、データから新たな特徴を作り出す「特徴量設計」も重要です。これは、料理で言えば、素材を組み合わせ、新たな料理を作り出すようなものです。既存のデータから、モデルが学習しやすい特徴を新たに作り出すことで、より精度の高いモデルを作ることができます。
これらの技術をうまく組み合わせ、常に新しい情報を学び続けることで、より良い二者分類モデルを作ることが可能になります。技術は日々進歩しています。常に学び続け、探求することで、より良いモデル作りを目指しましょう。
| 手法カテゴリー | 手法 | 説明 | データへの向き・不向き |
|---|---|---|---|
| 統計的手法 | 回帰分析 | 過去のデータから選択肢への関連性を数値化し、予測を行う。 | |
| データ構造学習 | サポートベクターマシン | データの境界線を発見し、選択肢を区別する。 | |
| データ構造学習 | 決定木 | データを段階的に分類し、選択肢に振り分ける。 |
| モデル改善 | 説明 | 例え |
|---|---|---|
| データ前処理 | データの欠損を補ったり、不要な情報を削除する。 | 料理の下ごしらえ |
| 特徴量設計 | 既存データから新たな特徴を作り出す。 | 新しい料理を作り出す |