
バギングとランダムフォレスト

AIを知りたい
先生、バギングとランダムフォレストの違いがよくわからないのですが、教えていただけますか?

AIエンジニア
そうですね。バギングは、たくさんのデータのかたまりから、いくつかのかたまりを何度も取り出して、それぞれで学習器を作ります。そして、新しいデータに対して、それぞれの学習器に判断させて、多数決で最終的な結果を決める方法です。 ランダムフォレストは、バギングの一種ですが、決定木という学習器を使い、さらに、どの情報を使うかもランダムに決める点が違います。
AIを知りたい
つまり、バギングはいろいろな学習器を使えるけど、ランダムフォレストは決定木しか使わないということですか?そして、情報もランダムに選ぶと。
AIエンジニア
その通りです。バギングは色々な学習器を使えますが、ランダムフォレストは決定木だけを使います。さらにランダムフォレストでは、どの情報で決定木を作るかもランダムに決めるので、より多様な決定木ができます。多くの異なる決定木を使うことで、より正確な予測ができるようになります。
バギングとは。
人工知能の分野でよく使われる『バギング』という手法について説明します。バギングは、データを復元抽出という方法で何度も選び出し、その度に異なる学習器を作ります。そして、それぞれの学習器に予測させ、最終的には多数決で結果を決める手法です。ランダムフォレストは、バギングを決定木という学習器を使って行うものです。さらに、それぞれの決定木では、使う特徴もランダムに選ぶところが、普通のバギングとは異なります。
バギングの概要

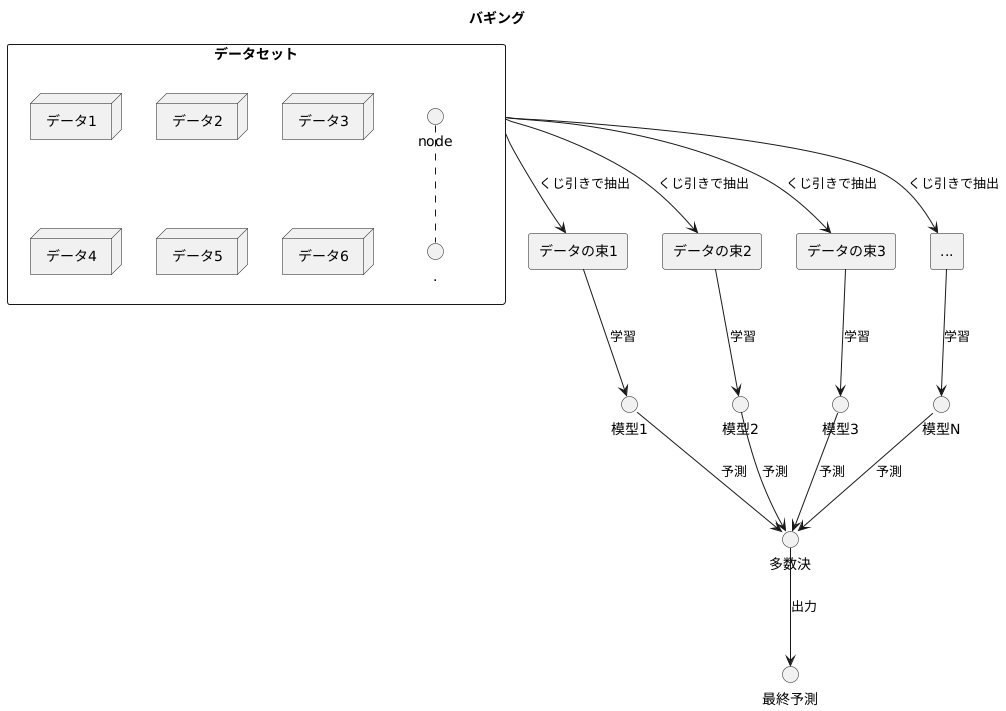
たくさんの模型を組み合わせて、より賢い予測をする方法、それが「集めて袋詰め」のような意味を持つバギングです。これは、機械学習という分野で、複雑な問題を解くための、「アンサンブル学習」という方法のひとつです。
バギングは、まるでくじ引きのように、元の学習データから同じ大きさのデータの束を何度も作り出します。このくじ引きには、同じデータが何度も入ったり、逆に全く入らないデータがあったりします。まるで同じ大きさの袋に、似たようなものを入れて、いくつか袋を作るイメージです。このデータの束それぞれを使って、別々の模型を作ります。それぞれの模型は、少しずつ異なるデータで学習するので、個性を持った模型になります。
予測するときには、これらの個性豊かな模型にそれぞれ予測させ、その結果を多数決でまとめます。多くの模型が「A」と答えれば、最終的な答えも「A」になります。
このように、たくさんの模型の意見を聞くことで、一つの模型を使うよりも、より信頼性の高い予測ができます。特に、決定木のような、データの変化に敏感な模型を使う際に効果的です。
一つ一つの模型は完璧ではありませんが、バギングによって、それぞれの弱点を補い合い、全体として優れた性能を発揮することができます。まるで、たくさんの人が集まって、お互いの知識を出し合うことで、より良い結論を導き出すように、バギングは機械学習において、より良い予測を実現するための、強力な手法と言えるでしょう。
ランダムフォレスト

ランダムフォレストは、たくさんの決定木を組み合わせることで、高い予測精度を実現する手法です。まるで森のようにたくさんの木が生えている様子から、この名前が付けられました。それぞれの木は、学習データから一部を抜き出して作られ、さらに木の枝分かれの際に使う情報も一部だけに絞られます。
データの一部を抜き出す方法は、ブートストラップサンプリングと呼ばれます。これは、同じデータに重複を許しながら、何度もくじ引きのようにデータを抜き出す方法です。それぞれの木には、異なる組み合わせのデータが割り当てられるため、同じデータを使っていても、異なる木が生えてくるのです。
さらに、木の枝分かれの際に使う情報も、全部使うのではなく、一部だけに絞ります。たとえば、ある商品が売れるかどうかを予測する際に、商品の値段、色、大きさなど、たくさんの情報があるとします。ランダムフォレストでは、それぞれの木で使う情報をランダムに選びます。ある木は値段と色だけ、別の木は大きさだけ、といった具合です。このように情報を絞ることで、それぞれの木の特徴がさらに際立ち、多様な木が育ちます。
森が出来上がったら、いよいよ予測です。新しいデータがやってくると、森のすべての木に予測させます。そして、それぞれの木の予測結果を多数決でまとめて、最終的な予測結果とします。たとえば、ある商品が売れるかどうかを予測する際に、森の中の70本の木が「売れる」と予測し、30本の木が「売れない」と予測したとします。この場合、多数決に従って「売れる」と予測します。このように、たくさんの木がそれぞれ異なる視点から予測することで、全体としてより正確な予測が可能になるのです。
ランダムフォレストは、高い予測精度に加えて、様々な種類のデータに対応できること、使う前の準備が比較的簡単であることなど、多くの利点があります。そのため、様々な分野で広く使われています。
決定木の役割

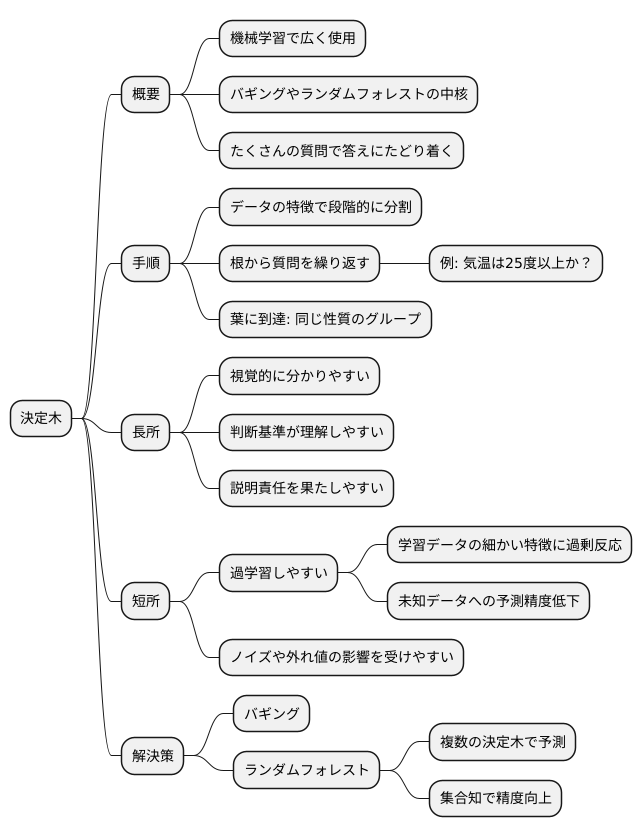
決定木は、機械学習の分野で広く使われている手法であり、特にバギングやランダムフォレストといったアンサンブル学習の中核を担っています。この手法は、例えるなら、たくさんの質問を繰り返すことで、最終的に求める答えにたどり着くような手順を踏みます。
決定木では、データの持つ様々な特徴を元にして、段階的にデータを小さなグループに分割していきます。木の根の部分から始まり、各分岐点で、データのある特徴に基づいた質問をします。例えば、「気温は25度以上か?」といった質問です。この質問への答えによって、データを2つのグループに分け、さらにそれぞれのグループの中で、別の特徴に基づいた質問を繰り返します。これを繰り返すことで、木の枝のようにデータが分割され、最終的には葉と呼ばれる部分にたどり着きます。葉の部分に属するデータは、同じ性質を持つと判断され、同じグループとして扱われます。
決定木による予測モデルは、視覚的に分かりやすく、どのような基準で判断が行われているかを理解しやすいという長所があります。これは、予測結果の説明責任が求められる場面では特に重要です。しかし、決定木は、学習データの細かい特徴に過剰に反応してしまうことがあります。つまり、学習データに含まれるごく特殊なパターンや例外的なデータにまで適合するようにモデルが作られてしまい、未知のデータに対しては正確な予測ができなくなることがあります。これを過学習と呼びます。また、学習データにノイズや外れ値が含まれる場合、それらの影響を大きく受けて、予測精度が低下することもあります。
こうした決定木の欠点を補うために、バギングやランダムフォレストといった手法が用いられます。これらの手法は、複数の決定木を生成し、それぞれの予測結果を組み合わせて最終的な予測を行います。多数の決定木の「集合知」を活用することで、単独の決定木では得られない高い精度と安定した予測結果を実現することができるのです。このように、決定木の分かりやすさとアンサンブル学習の強力さが組み合わさることで、実用的な機械学習モデルが構築されるのです。
多数決の重要性

たくさんの人が集まって物事を決めるとき、多くの人の意見が一致したほうを選ぶやり方を多数決といいます。これは、私たちが普段生活している中でもよく見られる方法で、例えば、クラスで遠足に行く場所を決めるときや、会社の会議で新しい企画を選ぶときなどにも使われています。
機械学習の世界でも、この多数決の考え方はとても役に立ちます。特に、「バギング」や「ランダムフォレスト」といった方法では、多数決が重要な役割を果たしています。これらの方法は、木をたくさん作って、それぞれの木に問題を解かせ、その結果をまとめることで、より正確な答えを導き出すという仕組みです。それぞれの木は、少しずつ異なるデータを使って学習するため、同じ問題でも答えが少し違います。そこで、どの答えが最も多く選ばれたかを多数決で決めることで、より信頼性の高い答えを得ることができるのです。
例えば、100本の木を使って、ある果物がリンゴかミカンかを判断する問題を考えてみましょう。70本の木がリンゴ、30本の木がミカンと判断した場合、多数決によって最終的な答えはリンゴとなります。このように、たとえ一部の木が間違った判断をしたとしても、多数決によって全体の正解率を高めることができるのです。
また、多数決は、単に数を数えるだけでなく、それぞれの木の判断の確信度を考慮することもできます。例えば、ある木がリンゴだと強く確信している場合は、その判断に大きな重みを与え、逆にあまり確信がない場合は、重みを小さくすることで、より精度の高い結果を得ることができます。
このように、多数決は、機械学習において、様々な判断をまとめ、より良い答えを導き出すための強力な道具となっています。特に、たくさんの木を使うバギングやランダムフォレストといった方法では、この多数決の仕組みが不可欠であり、複雑な問題を解く上で重要な役割を果たしていると言えるでしょう。
| 多数決とは | たくさんの人が集まって物事を決めるとき、多くの人の意見が一致したほうを選ぶやり方 |
|---|---|
| 日常生活での例 | クラスの遠足場所決め、会社の会議での企画選び |
| 機械学習での活用 | バギング、ランダムフォレスト |
| 仕組み | 複数の木を生成し、各々が問題を解き、結果を多数決で統合 |
| 例 | 100本の木で果物を判定。70本がリンゴ、30本がミカン→多数決でリンゴと判定 |
| 確信度の考慮 | 木の判断の確信度を重みとして考慮することで、精度向上 |
| まとめ | 多数決は機械学習において様々な判断をまとめ、より良い答えを導き出すための強力な道具 |
多様性の確保

たくさんの木を組み合わせる手法である、バギングとランダムフォレスト。これらの手法がうまくいく鍵は、学習されるそれぞれの木に、ばらつきを持たせることです。
バギングでは、データを何度も取り出して、それぞれの木に与えます。まるで、たくさんのくじが入った袋から、何度もくじを引くように、同じデータが何度も選ばれることもあれば、全く選ばれないデータもあるわけです。このようにして、それぞれの木が異なるデータで学習されることで、木のばらつきが生まれます。
ランダムフォレストでは、バギングに加えて、どの情報を使うかについてもランダムに決めます。たとえば、身長、体重、年齢といった様々な情報の中から、くじ引きのようにランダムに選び出して、それぞれの木に与えます。こうすることで、それぞれの木が異なる情報に注目して学習することになり、さらに木のばらつきが大きくなります。
このばらつきこそが、組み合わせ学習の効果を高める重要な要素です。もし、すべての木が同じデータ、同じ情報を使って学習されたとしたら、それらを組み合わせても予測の精度は上がりません。まるで、同じ考えを持つ人々が集まって話し合っても、新しい発想が生まれないのと同じです。
それぞれの木が異なる情報に注目し、異なるまちがいをすることで、多数決によってまちがいを打ち消し合い、全体としての予測精度を向上させることができるのです。まるで、様々な専門家が集まって議論することで、より正確な結論にたどり着けるのと同じです。ばらつきを大きくするための工夫は、ランダムフォレストの性能を左右する重要な要素と言えるでしょう。
| 手法 | データ | 情報 | ばらつき |
|---|---|---|---|
| バギング | 重複ありランダム抽出 | すべて | 小 |
| ランダムフォレスト | 重複ありランダム抽出 | ランダム抽出 | 大 |