
アルファ碁ゼロ:自己学習の革新

AIを知りたい
先生、「アルファ碁ゼロ」って、アルファ碁と何が違うんですか?

AIエンジニア
いい質問だね。アルファ碁は、過去のたくさんの碁の対局記録を学習して強くなったんだよ。いわば、先生に教えてもらって勉強したようなものだね。でも、アルファ碁ゼロは違うんだ。
AIを知りたい
違うって、どういうことですか?
AIエンジニア
アルファ碁ゼロは、誰にも教わらず、自分自身と何度も対戦することで強くなったんだ。まるで、一人で試行錯誤を繰り返して学習したようなものだよ。だから、人間の棋譜データは一切使っていないんだ。
アルファ碁ゼロとは。
人工知能に関する言葉である「アルファ碁ゼロ」について説明します。アルファ碁ゼロは、アルファ碁とは異なり、人間の棋譜のデータを使った学習は一切行いません。最初から最後まで自分自身と対戦して得たデータだけを使って、深層強化学習という方法で学習します。
はじめに

囲碁という遊びは、盤面の広さと複雑さゆえに、長い間、人工知能にとって難しい課題とされてきました。黒白の石を置くだけの単純なルールでありながら、その奥深さは人工知能の開発者たちを悩ませてきました。しかし、近年の深層学習技術のめざましい進歩によって、人工知能はついに人間を上回る強さを手に入れました。
その進歩を象徴する出来事の一つが、アルファ碁ゼロの登場です。アルファ碁ゼロは、過去の棋譜データを一切使わず、自己対戦のみで学習するという、画期的な手法を取り入れました。いわば、何も知らない生まれたばかりの状態から、囲碁のルールだけを教えられて、ひたすら自分自身と対戦を繰り返すことで、驚くべき速さで強くなっていったのです。これは、従来の人工知能開発の手法とは大きく異なるもので、囲碁界のみならず、人工知能研究全体に大きな衝撃を与えました。
アルファ碁ゼロの登場は、人工知能が新たな段階へと進んだことを示すものでした。人間が積み重ねてきた膨大な知識や経験に頼ることなく、自力で学習し、進化していく能力は、様々な分野への応用が期待されています。例えば、新薬の開発や、未知の病気の治療法の発見など、複雑な問題を解決するための新たな道を切り開く可能性を秘めていると言えるでしょう。アルファ碁ゼロの仕組みや特徴、そしてその影響について、これから詳しく見ていくことで、人工知能の未来への展望を探ってみたいと思います。
| 項目 | 内容 |
|---|---|
| 囲碁とAI | 盤面の広さと複雑さから、AIにとって長年難しい課題だった。 |
| 深層学習の進歩 | AIは人間を超える強さを獲得。 |
| AlphaGo Zeroの登場 | 過去の棋譜データを使わず、自己対戦のみで学習。 |
| AlphaGo Zeroの学習方法 | 生まれたばかりの状態から、囲碁のルールだけを教えられて自己対戦を繰り返す。 |
| AlphaGo Zeroの影響 | 囲碁界、人工知能研究全体に大きな衝撃を与えた。AIが新たな段階に進んだことを示す。 |
| AlphaGo Zeroの将来への展望 | 新薬開発や未知の病気の治療法発見など、様々な分野への応用が期待される。 |
過去の囲碁AIとの違い

過去の囲碁人工知能と最新の囲碁人工知能には、学習方法という点で大きな違いがあります。以前の囲碁人工知能、例えばアルファ碁は、過去の人間の対局記録を大量に学習することで強くなりました。これは、過去の囲碁名人が積み重ねてきた知恵や経験を、人工知能が受け継ぎ、模倣することで、強さを獲得していくという考え方です。いわば、人間の先生から囲碁を学ぶ弟子のようなものです。
しかし、最新の囲碁人工知能であるアルファ碁ゼロは、全く異なる学習方法を採用しています。アルファ碁ゼロは、人間の対局記録を一切学習しません。その代わりに、自分自身と何度も対局を繰り返すことで、強さを身につけていきます。これは、先生なしで、試行錯誤を繰り返しながら囲碁を学ぶようなものです。対局の最初は、全くの初心者なので、ランダムな手を打ちますが、対局を繰り返すうちに、どの手が有効で、どの手が無駄なのかを徐々に学習していきます。
このように、過去の囲碁人工知能が人間の知恵を基盤としていたのに対し、最新の囲碁人工知能は、人間の知恵に頼らず、独自の学習方法で強くなっている点が、大きな違いです。この違いにより、アルファ碁ゼロは、人間では思いつかないような独創的な打ち手を見せることがあります。まさに、名前の通り「ゼロ」から、人工知能独自の囲碁の世界を築き上げていると言えるでしょう。
| 項目 | 過去の囲碁AI (例: AlphaGo) | 最新の囲碁AI (例: AlphaGo Zero) |
|---|---|---|
| 学習方法 | 人間の棋譜データを大量に学習 | 自己対局による強化学習 |
| 学習元 | 人間の知恵・経験 | ゼロからスタート |
| 特徴 | 人間の先生から学ぶ弟子のような学習 | 試行錯誤を繰り返し、独自の打ち手を発見 |
| 例 | AlphaGo | AlphaGo Zero |
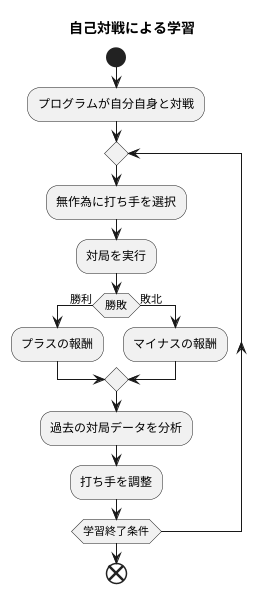
自己対戦による学習の仕組み

人工知能、特に囲碁や将棋といった盤面ゲームにおいては、自己対戦を通じて学習を進める手法が大きな成果を上げています。この自己対戦による学習は、どのように行われているのでしょうか。
まず、基本的な考え方として、プログラムは自分自身と何度も対戦を繰り返します。最初のうちは、石の置き方や駒の動かし方は全くの無作為です。いわば、全くの初心者同士が対局しているような状態です。しかし、対局を繰り返すうちに、それぞれの打ち手が勝利につながるのか、それとも敗北につながるのかを徐々に学習していきます。
この学習の過程で鍵となるのが「報酬」という考え方です。対局に勝利すれば、プログラムにはプラスの報酬が与えられます。逆に、敗北すればマイナスの報酬が与えられます。プログラムは、この報酬をできるだけ大きくするように、つまり勝利を最大化するために、自分の打ち手を調整していきます。
具体的には、過去の対局データから、どのような打ち手が勝利につながりやすいか、どのような打ち手が敗北につながりやすいかを分析します。そして、勝利につながる打ち手の頻度を高め、敗北につながる打ち手の頻度を下げるように、自ら修正していくのです。この一連の過程は、人間が教え込むことなく、プログラムが自ら試行錯誤を繰り返すことで実現されます。
自己対戦による学習の最大の利点は、人間の介入を必要としないことです。そのため、膨大な量の対局データを自動的に生成することができます。人間同士の対戦では、時間や体力の制約から、行える対局数には限界があります。しかし、プログラム同士の対戦であれば、そのような制約はありません。結果として、自己対戦は、人工知能の能力を飛躍的に向上させるための、非常に効果的な学習方法となっているのです。
深層学習の役割

近年の囲碁界において、人工知能(AI)が人間を凌駕する強さを示したことは、大変な驚きをもって迎えられました。この偉業を達成した立役者こそ、深層学習という技術です。深層学習は、人間の脳の神経回路網を模倣した仕組みで、これをニューラルネットワークと呼びます。このニューラルネットワークは、幾重にも層を重ねた構造を持ち、複雑なデータの中から隠れた規則性や特徴を見つけることに長けています。
囲碁というゲームを考えてみましょう。盤面には無数の石が置かれ、その配置一つ一つがゲームの行方を左右します。人間であれば、経験と直感に基づいて盤面を判断し、次の一手を考えますが、コンピュータにとっては、この複雑な状況を理解することは容易ではありません。そこで、深層学習が力を発揮します。深層学習を用いることで、コンピュータは、過去の膨大な棋譜データから、どのような盤面が有利で、どのような手が有効なのかを学ぶことができます。あたかも、熟練の棋士が長年の経験から得た知識を、コンピュータが短期間で習得するようなものです。
特に、アルファ碁ゼロと呼ばれるAIは、自己対戦という画期的な方法で学習を行いました。これは、AI同士が何千、何万回となく対戦を繰り返すことで、人間の知識や経験に一切頼ることなく、囲碁の奥深さを理解していくというものです。深層学習によって、AIは盤面の評価能力と最適な手を選択する能力を磨き上げ、ついには人間のトップ棋士をも超える強さを手に入れました。まさに、深層学習がAIの進化を大きく加速させ、新たな可能性を切り開いたと言えるでしょう。
| 項目 | 内容 |
|---|---|
| 技術 | 深層学習 (ニューラルネットワーク) |
| 仕組み | 人間の脳の神経回路網を模倣した多層構造 |
| 機能 | 複雑なデータから隠れた規則性や特徴を発見 |
| 応用例 | 囲碁AI (アルファ碁ゼロ) |
| 学習方法 | 過去の棋譜データ、自己対戦 |
| 成果 | 人間のトップ棋士を超える強さを獲得 |
アルファ碁ゼロの成果と影響

アルファ碁ゼロは、人工知能(じんこうちのう)における革新的な出来事と言えるでしょう。過去の囲碁ソフトは、過去の棋譜データや、囲碁の知識を持つ人間からの教えを学習材料としていました。しかし、アルファ碁ゼロは全く異なる方法、つまり自分自身との対戦を通して学習する「自己対局」という方法で、驚くべき強さを身につけたのです。
従来の最強ソフトであったアルファ碁に、全く教えを受けずに勝利したという事実は、人工知能の研究者にとって大きな衝撃でした。アルファ碁ゼロは、過去のデータや人間の知識に頼らず、ゼロから学習を始めることで、従来の囲碁ソフトの限界を超える力を獲得したのです。この成果は、人工知能の自己学習能力の可能性を示す、画期的な成果として高く評価されました。
アルファ碁ゼロの登場は、囲碁界だけでなく、様々な分野に大きな影響を与えました。例えば、新薬の開発や新しい材料の開発など、これまで人間の経験や知識に頼っていた分野においても、アルファ碁ゼロの自己学習技術が応用できる可能性が出てきました。膨大なデータから最適な組み合わせを見つけ出す必要がある創薬や材料開発において、アルファ碁ゼロの自己学習能力は、画期的な発見をもたらすと期待されています。
また、ゲームソフト開発の分野でも、アルファ碁ゼロの影響は無視できません。ゲームのキャラクターに、人間が教えなくても自分で学習して強くなる能力を持たせることができれば、より現実的で、より高度な人工知能を持つゲームを作ることが可能になるでしょう。アルファ碁ゼロの登場は、人工知能の新たな可能性を切り開き、未来を大きく変える力を持っていると言えるでしょう。
| 項目 | 内容 |
|---|---|
| 学習方法 | 自己対局(自分自身との対戦) |
| 従来ソフトとの比較 | 過去の棋譜データや人間の知識を学習に用いるアルファ碁に勝利 |
| 成果 | 人間の知識に頼らず、ゼロから学習することで従来ソフトの限界を超える力を獲得 |
| 影響 | 新薬開発、新材料開発、ゲームソフト開発など様々な分野への応用可能性 |
| 期待される効果 | 創薬や材料開発における最適な組み合わせの発見、より高度なAIを持つゲームの開発 |
今後の展望

囲碁という複雑な盤上遊戯において、教師なし学習だけで人間を凌駕する強さを示したアルファ碁ゼロの成功は、人工知能研究における大きな飛躍と言えるでしょう。この出来事は、機械学習、特に自己学習の可能性を示すと同時に、今後解決すべき幾つかの課題も浮かび上がらせました。
まず、アルファ碁ゼロの学習には膨大な計算資源と時間が費やされています。より複雑なゲームや、囲碁とは全く異なるルールを持つ実世界の課題に自己学習を適用するには、現状の学習効率では限界があります。そのため、少ない計算資源と時間で学習を完了できる、より効率的な学習手法の開発が急務です。
次に、学習データの質の改善も重要な課題です。アルファ碁ゼロは自己対戦によって学習データを生成していますが、初期の学習段階では質の低いデータも含まれてしまう可能性があります。質の低いデータに基づいて学習を進めると、学習の停滞や誤った方向への学習に繋がる恐れがあります。学習データの質を担保する仕組みや、質の低いデータの影響を低減する手法の開発が求められます。
これらの課題は容易に解決できるものではありませんが、アルファ碁ゼロが示した自己学習の可能性は計り知れません。今後、研究開発が進み、これらの課題が解決されれば、人工知能は様々な分野で目覚ましい発展を遂げるでしょう。人間では解決が困難な問題を解決したり、新しい発想を生み出したりするなど、人間を超える能力を持つ人工知能が、様々な分野で活躍する未来も現実味を帯びてきています。人工知能の発展は目覚ましく、私たちは今後の進歩を注意深く見守りながら、その可能性を最大限に引き出し、より良い社会を築いていく必要があるでしょう。
| 課題 | 詳細 |
|---|---|
| 計算資源と時間 | アルファ碁ゼロの学習には膨大な計算資源と時間が費やされている。より複雑なゲームや実世界の課題に適用するには、現状の学習効率では限界があるため、より効率的な学習手法の開発が急務である。 |
| 学習データの質 | アルファ碁ゼロは自己対戦で学習データを生成するが、初期段階では質の低いデータも含まれる可能性があり、学習の停滞や誤った方向への学習に繋がる恐れがある。学習データの質を担保する仕組みや、質の低いデータの影響を低減する手法の開発が求められる。 |