アルゴリズムバイアス:公平性の落とし穴

AIを知りたい
先生、「アルゴリズムバイアス」って言葉、よく聞くんですけど、難しくてよくわからないです。簡単に教えてもらえますか?

AIエンジニア
そうだね。「アルゴリズムバイアス」とは、機械学習のプログラムに、偏った学習データを与えてしまうことで、そのプログラムが偏った結果を学習してしまうことだよ。 例えば、あるプログラムに男性の写真ばかりを見せて「これは人間です」と教えたら、そのプログラムは女性の写真を見せられても「これは人間ではありません」と答えてしまうかもしれないね。
AIを知りたい
なるほど。つまり、プログラムに教えるデータが偏っていると、プログラムの判断も偏ってしまうということですね。
AIエンジニア
その通り!まさにそういうことだよ。だから、機械学習では、偏りのない、たくさんの種類のデータを使って学習させることがとても大切なんだ。
アルゴリズムバイアスとは。
人工知能に関する言葉である「計算手順の偏り」について説明します。計算手順の偏りとは、偏った学習データを与えたことで、機械学習の計算手順が偏った結果を学習してしまうことを指します。
アルゴリズムバイアスとは

アルゴリズムバイアスとは、人の考えや行動を模倣する情報処理の手順、つまり計算方法に偏りがあることを指します。この偏りは、計算方法自体に問題があるのではなく、計算方法のもととなる学習データに偏りがあるために生じます。例えば、過去の採用活動のデータから学習する採用選考の計算方法を考えてみましょう。もし過去の採用活動において、男性が採用される割合が女性よりも高いという偏りがあった場合、この計算方法は学習データの偏りを反映し、男性を優遇する結果を生み出す可能性があります。
この現象は、計算方法が意図的に差別をしているわけではなく、偏りのあるデータから学習した結果、意図せず差別的な結果を生み出しているという点で重要です。つまり、過去のデータに含まれる社会の偏見や差別が、計算方法を通じて再現、あるいは増幅されてしまうのです。例えば、過去の犯罪データから犯罪発生率を予測する計算方法の場合、特定の地域や集団が犯罪を起こしやすいと判断される可能性があります。しかし、これは必ずしもその地域や集団が実際に犯罪を起こしやすいことを意味するのではなく、過去のデータにおける偏った取り締まりや記録方法が反映されている可能性もあるのです。
アルゴリズムバイアスは、情報技術の公平性と倫理的な活用を考える上で大きな課題となっています。偏りのない計算方法を作るためには、学習データの偏りを認識し、修正するための様々な取り組みが必要です。例えば、学習データの量を増やす、多様なデータを取り入れる、偏りを補正する計算方法を開発する、などといった対策が考えられます。また、計算方法がどのような基準で判断を下しているかを明確にすることで、バイアスの影響を評価し、改善していくことも重要です。
| 項目 | 説明 | 例 |
|---|---|---|
| アルゴリズムバイアス | 計算方法(アルゴリズム)に偏りがあること。学習データの偏りが原因。 | – |
| 学習データの偏りの影響 | 学習データの偏りが、アルゴリズムを通じて差別的な結果を生み出す。意図的な差別ではなく、データの偏りの反映。 | 男性優遇の採用選考アルゴリズム |
| 社会の偏見や差別の再現 | 過去のデータに含まれる社会の偏見や差別が、アルゴリズムによって再現・増幅される。 | 特定地域・集団を犯罪を起こしやすいと判断する犯罪予測アルゴリズム |
| 対策 | 学習データの偏りを認識し、修正する必要がある。 | 学習データの量を増やす、多様なデータを取り入れる、偏りを補正する計算方法を開発する、判断基準を明確にする |
バイアスの種類

計算手順に潜む偏りには、様々な種類があります。これらの偏りは、機械学習の様々な場面で発生し、予測や判断の正確さを損なう原因となります。代表的なものをいくつか紹介します。
まず、学習に使うデータの中に、特定の特徴を持つデータが過剰に含まれている場合に起こるのが、「代表性偏り」です。例えば、顔認識の学習データに特定の人種が多く含まれていると、その他の人種の認識精度が低くなる可能性があります。これは、学習データが現実世界を正しく反映していないために起こります。現実世界でのデータの分布を把握し、学習データの偏りを修正する必要があります。
次に、「欠落偏り」は、特定の特徴を持つデータが学習データに十分に含まれていない場合に発生します。例えば、医療診断の学習データに特定の病気のデータが少ないと、その病気の診断精度が低くなる可能性があります。この偏りは、データ収集の難しさや、特定のデータの入手しにくさなどが原因で発生します。欠落しているデータを補完したり、データ収集方法を改善したりする対策が必要です。
さらに、「測定偏り」は、データを集める方法や測り方に問題がある場合に発生します。例えば、アンケート調査で質問の仕方が誘導的だと、回答に偏りが生じる可能性があります。これは、データそのものに問題があるのではなく、データの収集過程に問題があるために発生します。データ収集方法を慎重に見直し、偏りのないデータを得られるように工夫する必要があります。
これらの偏りは、単独で現れる場合だけでなく、複数組み合わさって複雑な問題を引き起こすこともあります。例えば、代表性偏りと測定偏りが同時に存在すると、特定の特徴を持つデータが過剰に含まれている上に、そのデータの測定方法にも問題があるため、偏りがさらに大きくなる可能性があります。そのため、様々な種類の偏りを理解し、それぞれの状況に応じて適切な対策を講じることが重要です。
| 偏りの種類 | 説明 | 例 | 対策 |
|---|---|---|---|
| 代表性偏り | 特定の特徴を持つデータが学習データに過剰に含まれている。 | 顔認識の学習データに特定の人種が多く含まれているため、その他の人種の認識精度が低い。 | 現実世界のデータの分布を把握し、学習データの偏りを修正する。 |
| 欠落偏り | 特定の特徴を持つデータが学習データに十分に含まれていない。 | 医療診断の学習データに特定の病気のデータが少ないため、その病気の診断精度が低い。 | 欠落しているデータを補完したり、データ収集方法を改善したりする。 |
| 測定偏り | データを集める方法や測り方に問題がある。 | アンケート調査で質問の仕方が誘導的だと、回答に偏りが生じる。 | データ収集方法を慎重に見直し、偏りのないデータを得られるように工夫する。 |
バイアスの影響

人工知能(AI)が私たちの社会で広く使われるようになり、暮らしが便利になる一方で、思わぬ落とし穴も存在します。それはAIの「かたより」、つまりバイアスの問題です。このバイアスは、AIの判断をゆがめ、様々な場面で不公平な結果を生み出す可能性があります。
例えば、企業の採用活動を考えてみましょう。AIを使って履歴書をふるいにかけるシステムがあったとします。もしこのシステムに過去の採用データに基づいたバイアスが含まれていた場合、特定の属性を持つ人、例えば女性や特定の出身地の人などは、能力に関係なく不利な評価を受ける可能性があります。これは機会の平等を損ない、深刻な問題です。
また、お金を借りる際の審査でも同様の問題が起こりえます。AIが過去のローン返済データからバイアスを学習していると、特定の地域に住む人や、特定の職業の人々が不当に低い評価を受け、融資を受けにくくなる可能性があります。これは経済的な格差をさらに広げることにつながりかねません。
さらに、犯罪の発生を予測するシステムや医療診断を支援するシステムなどでも、バイアスによる影響が懸念されています。犯罪予測システムでは、特定の人種や地域が過剰に危険視される可能性があり、医療診断システムでは、特定の性別や年齢層に対して誤った診断が行われる可能性があります。このようなバイアスは、人々の安全や健康に直接関わるため、特に注意が必要です。
このように、AIのバイアスは社会の様々な場面で不公平を生み出す可能性があります。AIを正しく活用するためには、バイアスの影響を最小限に抑えるための技術的な対策はもちろんのこと、AIが出した結果を人間が常に批判的に検討する姿勢も重要です。
| 場面 | バイアスによる影響 | 問題点 |
|---|---|---|
| 採用活動 | 特定の属性(性別、出身地など)を持つ人が不利な評価を受ける | 機会の平等を損なう |
| ローン審査 | 特定の地域や職業の人が融資を受けにくくなる | 経済的な格差を拡大する |
| 犯罪予測 | 特定の人種や地域が過剰に危険視される | 人々の安全に影響 |
| 医療診断 | 特定の性別や年齢層に対して誤った診断が行われる | 人々の健康に影響 |
バイアスへの対策

計算手順の偏りを正すには、様々な方法があります。まず、学習させる情報に偏りがないように、情報の集め方や整理の仕方を改める必要があります。もし、特定の種類の情報が少ない場合は、その情報を追加で集めることが重要です。集めた情報に偏りがある場合は、その偏りを修正する計算方法を使うという手もあります。
次に、計算手順そのものにも対策が必要です。例えば、公平さを重視した新しい計算手順を開発するという方法があります。他にも、計算結果を常にチェックして、偏りがないかを確認する仕組みを作ることも大切です。計算結果に偏りが見つかった場合は、すぐに対応できるようにしておく必要があります。
さらに、計算手順を作る人や使う人の意識を変えることも重要です。偏りに関する教育や研修を行うことで、倫理的に正しい計算手順の開発を促すことができます。計算手順を作る人や使う人が、偏りの問題をしっかりと理解していれば、偏りが発生しにくい計算手順を作ったり、偏りに気づきやすくなるからです。
これらの対策をすべて行うことで、計算手順の偏りの影響を最小限に抑え、公平で信頼できる計算システムを作ることができます。偏りへの対策は一度行えば終わりではなく、常に改善していく必要があるということも忘れてはいけません。技術の進歩に合わせて、新しい対策方法を常に探っていく必要があります。
| 対策 | 具体的な方法 |
|---|---|
| 学習させる情報の偏りをなくす | 情報の集め方や整理の仕方を改める 少ない情報を追加で集める 偏りを修正する計算方法を使う |
| 計算手順そのものに介入する | 公平さを重視した新しい計算手順を開発する 計算結果を常にチェックして、偏りがないかを確認する仕組みを作る 計算結果に偏りが見つかった場合は、すぐに対応できるようにしておく |
| 計算手順を作る人や使う人の意識を変える | 偏りに関する教育や研修を行う |
今後の展望

人工知能技術の進歩に伴い、計算手順に潜む偏りは、社会全体の公平性や持続可能性を左右する重要な課題となっています。今後、人工知能が様々な分野で広く活用されるにつれて、この偏りによる不公平な結果が生じる危険性はさらに高まると考えられます。
まず、計算手順の偏りを生み出す原因を詳しく調べ、その発生を未然に防ぐための対策を確立することが重要です。そのためには、人工知能の学習に用いるデータの質を高め、多様な属性の人々を公平に反映したデータセットを構築する必要があります。さらに、計算手順の開発段階から偏りの有無を検証し、必要に応じて修正を加える仕組みを導入することも不可欠です。また、偏りを自動的に検知し、修正する技術の開発も重要な課題です。
さらに、人工知能の倫理に関する議論を深め、社会全体で公平な人工知能利用のための規範や制度を整備していくことも大切です。人工知能技術の開発者、利用者、そして社会全体の構成員がそれぞれの責任を自覚し、倫理的な観点から人工知能技術の利用を監視・評価していく必要があります。透明性の高い開発プロセスを確保し、人工知能の判断根拠を説明できる仕組みを構築することで、利用者や社会全体の理解と信頼を得ることが重要です。
人工知能技術の進歩は、私たちの社会に様々な恩恵をもたらす可能性を秘めています。しかし、その恩恵を公平に享受するためには、計算手順の偏りという課題に適切に対処していく必要があります。今後の社会の発展のためにも、人工知能技術と社会の調和を図り、より良い未来を築き上げていく努力が求められています。
| 課題 | 対策 | 関係者 |
|---|---|---|
| 計算手順の偏り |
|
|
まとめ

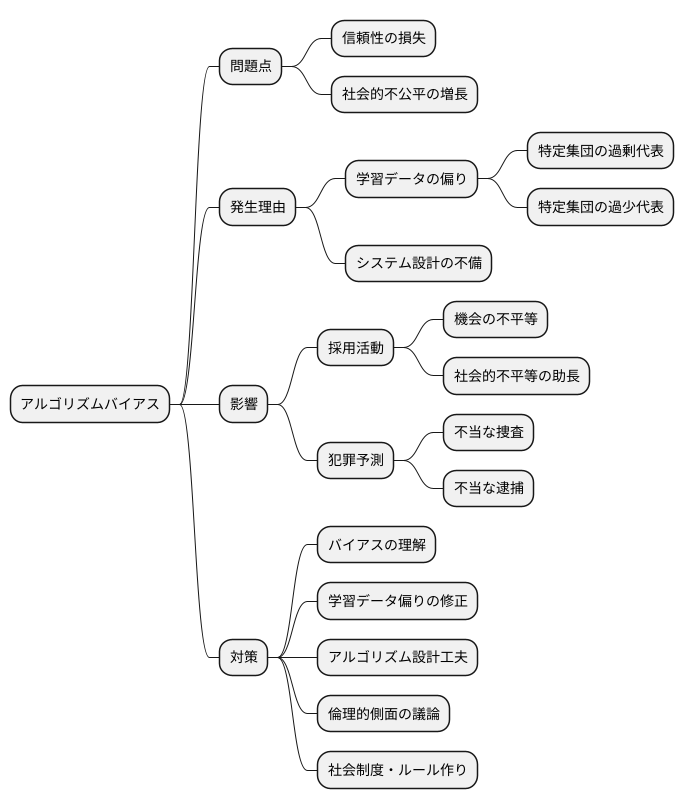
人工知能の技術が発展するにつれて、人工知能が持つ公平さへの関心も高まっています。しかし、人工知能の判断には、時に偏りが生じてしまうことがあります。これをアルゴリズムバイアスと呼びます。アルゴリズムバイアスは、人工知能システムの信頼性を損なうだけでなく、社会全体に不公平な影響を与える可能性がある深刻な問題です。
アルゴリズムバイアスは様々な理由で発生します。例えば、人工知能が学習するデータに偏りがある場合、その偏りが人工知能の判断にも反映されてしまいます。学習データが特定の集団を過剰に代表していたり、逆に過少に代表していたりすると、人工知能はその集団に対して不公平な判断を下す可能性があります。また、人工知能を作る際の設計そのものに問題がある場合もバイアスが発生する原因となります。
このバイアスは、社会の様々な場面で影響を及ぼします。例えば、採用活動において、特定の属性を持つ人々を不利に扱うようなバイアスが存在すれば、機会の平等を損ない、社会的な不平等を助長することになります。また、犯罪予測システムにおいて特定の地域や人種に対してバイアスがかかっていれば、不当な捜査や逮捕につながる可能性も懸念されます。
アルゴリズムバイアスの影響を最小限に抑えるためには、まずバイアスの種類や影響を正しく理解することが重要です。その上で、学習データの偏りを修正する技術や、アルゴリズムの設計段階でバイアスを軽減するための工夫など、適切な対策を講じる必要があります。さらに、人工知能技術者だけでなく、社会全体で倫理的な側面も踏まえた議論を行い、社会的な制度やルール作りを進めることも必要不可欠です。人工知能技術がより良い社会を実現するために活用されるためには、アルゴリズムバイアスへの継続的な取り組みが不可欠です。今後も技術開発と社会制度の両面からこの問題に取り組んでいく必要があるでしょう。