敵対的攻撃:AIの弱点

AIを知りたい
「人工知能へのいたずら」って、どういう意味ですか?

AIエンジニア
人工知能をだますような、ちょっとした細工のことだよ。例えば、パンダの絵にほとんど見えないような模様を付け加えると、人工知能がテナガザルだと勘違いしてしまうことがあるんだ。
AIを知りたい
へえ、まるで目の錯覚みたいですね。でも、そんなちょっとしたことで騙されるんですか?
AIエンジニア
そうなんだ。人間には気づかないようなわずかな変化でも、人工知能にとっては大きな違いになることがある。例えば、自動運転車が標識を読み間違えて事故につながる可能性もあるから、対策が必要とされているんだよ。
Adversarial Attackとは。
人工知能にまつわる言葉である「敵対的攻撃」について説明します。敵対的攻撃とは、人工知能が例えば「A」だと認識している画像に、わずかな修正を加えることで、人工知能がそれを「B」だと誤って認識するように仕向けることです。有名な例として、パンダの絵にノイズを加えることで、人間にはパンダのままに見えるのに、人工知能はテナガザルだと認識してしまう、というものがあります。このようなデータの改変だけでなく、例えば道路標識に物理的な手を加えることで、「止まれ」の標識を「止まれ」だと認識させなくしてしまうことも、敵対的攻撃の一つです。敵対的攻撃を防ぐための新しい方法が開発されても、それをすり抜ける新しい攻撃方法が生み出されるという、いたちごっこが続いています。人工知能は日々進化していますが、例えば自動運転車が敵対的攻撃を受けると、誤認識によって事故につながる可能性もあります。そのため、攻撃に強い人工知能モデルの開発が必要不可欠です。
人工知能の誤認識

人工知能は、まるで人のように画像を見分けたり、声を聞き取ったりすることができるようになり、様々な分野でめざましい成果をあげています。自動運転や医療診断など、私たちの暮らしを大きく変える可能性を秘めています。しかし、人工知能にはまだ弱点も存在します。その一つが、人工知能をだます攻撃、いわゆる「敵対的な攻撃」です。
この攻撃は、人工知能が認識するデータに、まるで気づかないような小さな変化を加えることで、人工知能を間違った判断に導くというものです。例えば、パンダの絵を人工知能に見せるとします。この絵に、人にはまったく見えないようなごく小さなノイズを加えます。すると、人工知能は、パンダの絵をテナガザルだと誤って認識してしまうのです。まるで、人工知能の目に魔法をかけて、実際とは違うものを見せているかのようです。
このような小さな変化は、人間には全く分かりません。パンダの絵は、ノイズが加えられても、私たちには変わらずパンダの絵に見えます。しかし、人工知能にとっては、このノイズが大きな意味を持ち、判断を狂わせる原因となるのです。これは、人工知能がデータの特徴を捉える仕方が、人間とは大きく異なることを示しています。
敵対的な攻撃は、人工知能の安全性を脅かす重大な問題です。例えば、自動運転車を考えてみましょう。もし、道路標識に敵対的な攻撃が仕掛けられた場合、自動運転車は標識を誤認識し、事故につながる可能性があります。また、医療診断の分野でも、画像診断に敵対的な攻撃が加えられると、誤診につながる恐れがあります。このように、人工知能の実用化が進むにつれて、敵対的な攻撃への対策はますます重要になっています。人工知能の安全性を高めるためには、このような攻撃を防ぐ技術の開発が不可欠です。
| 項目 | 説明 |
|---|---|
| 人工知能の現状 | 画像認識、音声認識等で成果を上げている。自動運転、医療診断などへの応用が期待される。 |
| 人工知能の弱点:敵対的な攻撃 | データに微小な変化を加えることで、人工知能を誤った判断に導く攻撃。 |
| 敵対的な攻撃の例 | パンダの絵にノイズを加えることで、テナガザルと誤認識させる。 |
| 敵対的な攻撃の特徴 | 人間には変化が分からない。人工知能のデータ認識の仕方が人間と異なることを示す。 |
| 敵対的な攻撃の危険性 | 自動運転車の事故、医療診断の誤診につながる可能性。 |
| 対策の必要性 | 人工知能の実用化に伴い、敵対的な攻撃への対策が重要。 |
実世界の脅威

現実の世界で起こりうる脅威について考えてみましょう。敵対的攻撃は、机上の空論ではありません。身近になりつつある自動運転車を例に考えてみます。もし、道路標識にわずかな細工が施され、人間の目にはわからないような変化が加えられていたとします。これは敵対的攻撃の一種であり、この細工によって、自動運転車は標識を誤って認識してしまうかもしれません。「止まれ」の標識を「進め」と認識してしまったら、どうなるでしょうか。交差点に進入し、重大な事故につながる恐れがあります。また、制限速度を示す標識を誤認識すれば、速度違反で検挙されるだけでなく、他の車との衝突事故を引き起こす可能性も否定できません。このように、敵対的攻撃は人の命を危険にさらす可能性がある深刻な問題なのです。
自動運転車だけでなく、医療の分野でも、人工知能の活用は進んでいます。例えば、レントゲン写真やCT画像から病気を診断する人工知能が実用化されつつあります。もし、これらの医療画像に敵対的攻撃が仕掛けられたらどうなるでしょうか。人工知能は病巣を見逃したり、健康な部分を病気と誤診したりするかもしれません。 誤診は、適切な治療の開始を遅らせ、患者の健康状態を悪化させる可能性があります。場合によっては、命に関わる重大な結果をもたらすことも考えられます。
これらのリスクを回避するためには、敵対的攻撃に対する防御策を強化することが必要不可欠です。様々な角度からの研究開発が求められており、人工知能を安全に活用するための対策は、喫緊の課題と言えるでしょう。人工知能が社会に広く浸透していく中で、敵対的攻撃に対する備えは、我々の生活の安全を守る上で、今後ますます重要になっていくでしょう。
| 分野 | 敵対的攻撃の例 | 潜在的な危険性 |
|---|---|---|
| 自動運転 | 道路標識への細工 | 誤認識による事故(例:交差点への進入、速度違反による衝突) |
| 医療 | 医療画像への細工 | 誤診による治療の遅延、健康悪化、重大な結果 |
攻撃手法の巧妙化

巧妙さを増す攻撃手法は、私たちの暮らしを脅かす大きな問題となっています。かつては、絵や写真にわずかなノイズを加えるといった単純な方法で、人工知能の判断を狂わせる攻撃が主流でした。まるで人の目には見えないほどの小さなゴミを写真に紛れ込ませ、人工知能が誤作動を起こすようなものです。しかし、近年の攻撃は、はるかに高度で複雑化しています。
例えば、現実世界に存在する物体を用いた攻撃が報告されています。道路標識にシールを貼ることで、自動運転車を誤った方向へ誘導するといった事例です。これは、単なるデータ上の操作ではなく、物理的な世界に干渉することで人工知能の判断を狂わせる、より現実的な脅威と言えるでしょう。また、人工知能の学習に用いるデータそのものを改ざんする攻撃も確認されています。人工知能は、大量のデータから学習し、物事を判断する能力を獲得します。もし、この学習データが意図的に操作されていれば、人工知能は間違った知識を習得し、誤った判断を下す可能性があります。これは、まるで教科書の内容を書き換えて、生徒に間違った知識を教え込むようなものです。
このような高度化する攻撃に対抗するためには、常に最新の攻撃手法に関する情報を収集し、適切な対策を講じる必要があります。家の鍵をこまめに変えるように、絶えず変化する攻撃の手口に対応していく必要があるのです。人工知能を守るための努力は、まるでいたちごっこのようです。攻撃者は常に新しい方法を模索し、防御側はそれに対応する新しい対策を開発する、終わりなき戦いが続いています。人工知能を安全に利用するためには、私たち一人ひとりがセキュリティ意識を高め、最新の脅威情報に注意を払うことが大切です。そうすることで、より安全で安心な社会を実現できるでしょう。
| 攻撃手法の進化 | 具体的な例 | 脅威の性質 |
|---|---|---|
| 単純な攻撃 (過去) | 画像へのノイズ混入 | データ上の操作 |
| 高度な攻撃 (現在) | 道路標識へのシール貼付による自動運転車への影響 | 物理世界への干渉 |
| 高度な攻撃 (現在) | 学習データの改ざん | 人工知能の知識操作 |
防御策の開発

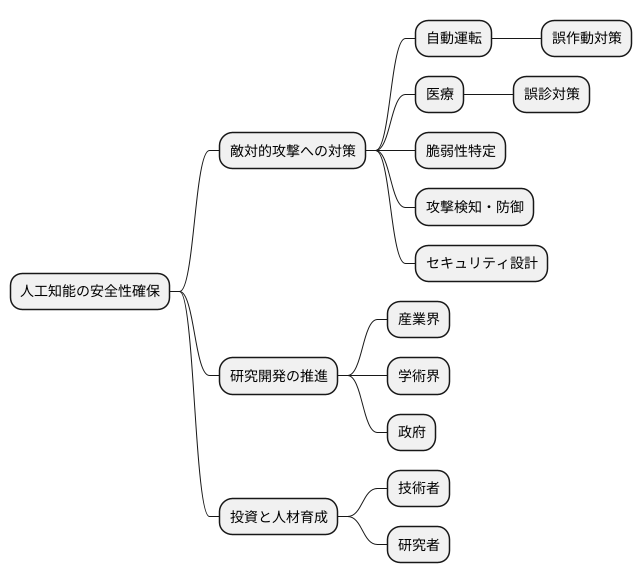
機械学習モデルを狙った悪意ある攻撃、いわゆる敵対的攻撃への対策として、様々な防御策の研究開発が盛んに行われています。こうした攻撃は、入力データにわずかな変更を加えることで、モデルの判断を誤らせる巧妙なものです。例えば、画像認識モデルの場合、人の目には認識できない程度のノイズを画像に加えることで、全く異なる物体として認識させてしまうことが可能です。自動運転システムに適用された場合、標識を誤認識させて事故を誘発するなど、深刻な事態を引き起こす危険性も孕んでいます。
こうした脅威に対抗するために、いくつかのアプローチが試みられています。一つは、敵対的攻撃を検知するシステムの開発です。入力データに不自然なノイズが含まれていないか、統計的な手法や機械学習を用いて検知することで、攻撃を未然に防ぐ試みです。また、攻撃の影響を受けにくい、頑健なモデルの開発も重要な研究分野です。様々なノイズを含むデータで学習させることで、多少の改変では誤認識しないモデルを作ることが期待されます。さらに、攻撃を受けた後のモデルの挙動を分析し、攻撃の種類や特徴を把握することで、より効果的な防御策を考案する研究も進められています。
しかしながら、防御策の開発と攻撃手法の開発は、まるでいたちごっこの様相を呈しています。新たな防御策が登場するたびに、それを突破する新しい攻撃手法が編み出されるため、完全な防御策を確立することは非常に困難です。そのため、敵対的攻撃への対策は、長期的な視点に立った継続的な研究開発が不可欠であり、攻撃者と防御側の終わりなき競争が続くものと考えられます。
強固なモデル構築

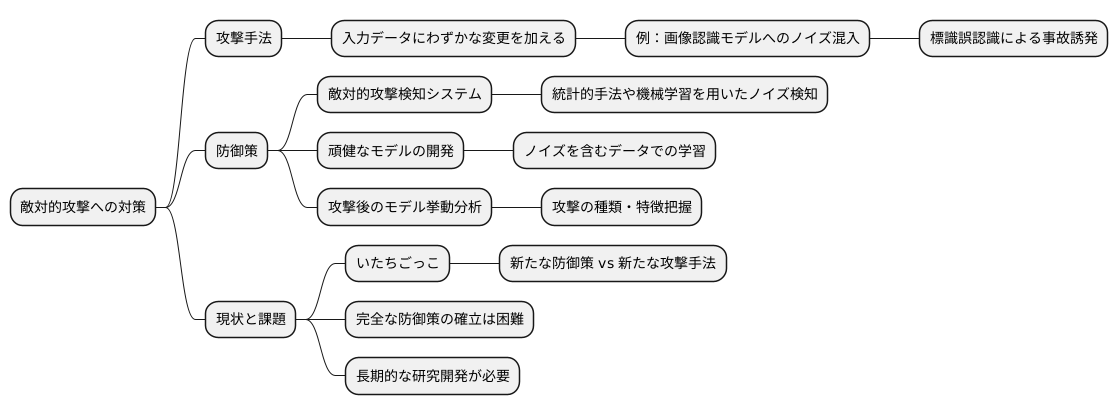
近年の技術革新に伴い、人工知能は目覚ましい発展を遂げ、社会の様々な場面で活用されています。それと同時に、人工知能の安全性と信頼性を確保することも重要な課題となっています。悪意ある攻撃者による様々な工作、いわゆる敵対的攻撃から人工知能モデルを守るためには、強固なモデルを構築することが不可欠です。
強固なモデルとは、様々な攻撃に対して耐性を持つ人工知能モデルのことです。例えば、入力データに微小な変化を加えることで人工知能の判断を誤らせる攻撃や、大量の偽データを用いて人工知能の学習を妨害する攻撃など、様々な攻撃手法が知られています。これらの攻撃からモデルを守るためには、多様な攻撃手法を想定した訓練を行う必要があります。また、攻撃を検知し、適切に対処する仕組みを組み込むことも重要です。
強固なモデルの構築に加えて、人工知能システム全体の安全対策も重要です。人工知能モデルは、データの収集、前処理、モデルの学習、推論、出力といった一連の過程を経て動作します。それぞれの過程でセキュリティ上の脆弱性が存在すると、攻撃者に悪用される可能性があります。そのため、システム全体を包括的に見直し、セキュリティ対策を講じる必要があります。
人工知能の開発者や利用者は、敵対的攻撃のリスクを正しく認識し、適切な対策を講じることで、人工知能の安全な活用を推進していく必要があります。これは、人工知能技術の発展と普及にとって、なくてはならない要素と言えるでしょう。人工知能が社会に広く浸透していくためには、安全性と信頼性を確保し、人々の生活を豊かにする技術として発展していくことが求められています。
今後の展望

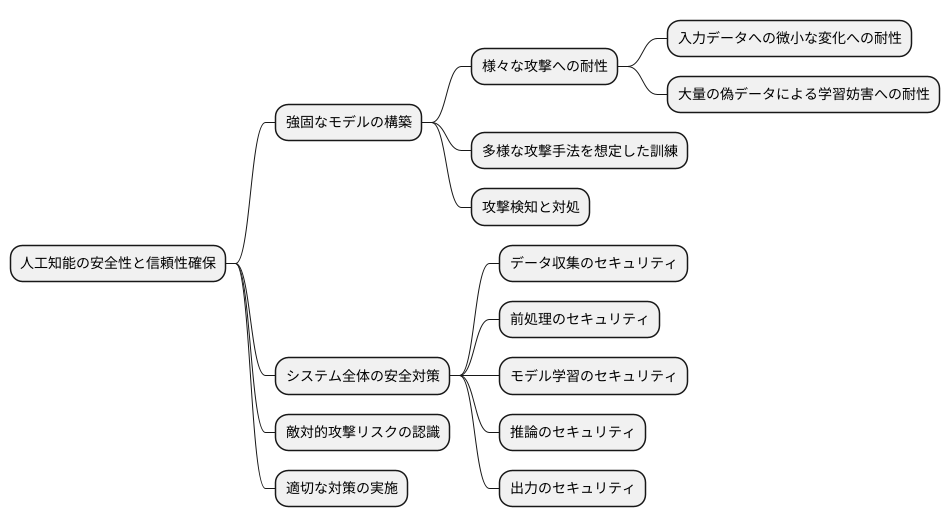
人工知能技術は、目覚ましい速さで進歩を続けています。それと同時に、人工知能を欺く、いわゆる敵対的攻撃のやり方も巧妙さを増していくと考えられます。今後、人工知能が私たちの暮らしの様々な場面で使われるようになれば、敵対的攻撃による危険性も大きくなるでしょう。そのため、人工知能の安全性を守ることは、これまで以上に大切な課題となるでしょう。様々な組織が協力して、敵対的攻撃から人工知能を守るための研究開発を進めることで、安全で安心して使える人工知能社会を作っていく必要があるでしょう。
特に、車の自動運転や医療など、人の命に直接関わる分野では、敵対的攻撃への対策が最優先事項となるはずです。例えば、自動運転車を騙して誤作動させたり、医療診断画像を改ざんして誤診を誘発したりするといった攻撃は、重大な事故につながる恐れがあります。このような事態を防ぐためには、人工知能システムの脆弱性を見つける研究や、攻撃を検知して防御する技術の開発が不可欠です。また、人工知能システムの設計段階からセキュリティを考慮することも重要です。堅牢なシステムを構築することで、敵対的攻撃の影響を最小限に抑えることができます。
人工知能は、私たちの社会をより便利で豊かにする可能性を秘めています。しかし、その恩恵を安全に享受するためには、人工知能の進化とともに、その安全性を守るための努力を続ける必要があるでしょう。産業界、学術界、そして政府が一体となり、敵対的攻撃に対する研究開発を推進することで、安全で信頼できる人工知能社会を実現していきましょう。そのためには、継続的な投資と人材育成も必要不可欠です。将来を見据え、次世代を担う技術者や研究者の育成にも力を入れていく必要があるでしょう。人工知能技術の進歩と安全性の確保は、車の両輪のように共に進めていくべき課題です。