
行動価値関数:最良の行動を探る

AIを知りたい
『行動価値関数』って、状態価値関数とどう違うんですか?どちらも報酬に関係しているように見えるんですが…

AIエンジニア
良い質問ですね。どちらも報酬に関係していますが、視点が違います。状態価値関数は、ある状態にいることの価値、つまり、その状態から最終的にどれだけの報酬が得られるかを表します。一方、行動価値関数は、ある状態で特定の行動をとることの価値を表します。
AIを知りたい
なるほど。状態にいることの価値と、行動することの価値…違いが少し見えてきました。もう少し具体的に教えていただけますか?
AIエンジニア
例えば、迷路を考えてみましょう。状態価値関数は、迷路のある地点にいることの価値を表します。ゴールに近いほど価値は高いですよね。行動価値関数は、その地点で、例えば「右に進む」「左に進む」といったそれぞれの行動の価値を表します。ゴールへの近道となる行動の価値は高くなります。
行動価値関数とは。
人工知能の分野で使われる「行動価値関数」という言葉について説明します。行動価値関数は、ある状況から次の状況に移るときに、どのような行動をとるべきかを数値で表したものです。
人工知能の学習方法の一つである強化学習では、最終的に得られる報酬の合計を最大にすることが目標です。この目標を達成するために重要なのが「状態価値関数」と「行動価値関数」です。
状態価値関数は、ある状況にいることの価値を表すのに対し、行動価値関数は、ある状況で特定の行動をとることの価値を表します。人工知能のエージェントは、行動価値関数の値が最大になる行動を選ぶことで、報酬を最大にするための最適な行動を見つけ出すことができます。例えば、迷路を解く場合、エージェントは行動価値関数を基に、ゴールまでの最短ルートを見つけることができます。
行動価値関数の定義

行動価値関数は、強化学習において中心的な役割を担います。強化学習とは、機械が周囲の状況と関わり合いながら、試行錯誤を通じて学習していく仕組みのことです。学習を行う主体であるエージェントは、様々な行動をとり、その結果に応じて報酬を受け取ります。この報酬を最大化することを目指して学習を進めていきます。
行動価値関数は、ある状況下で、特定の行動をとった場合に、将来どれだけの報酬を得られるかを予測するものです。言いかえると、それぞれの状況でどの行動を選ぶのが最も有利かを判断するための指針となります。もう少し詳しく説明すると、状態sにおいて行動aを選択したとき、将来にわたって得られる報酬の合計を割引率γで割り引いた値の平均が、行動価値関数Q(s, a)と定義されます。
ここで出てくる割引率γは、将来得られる報酬を現在の価値に換算するための係数で、0から1の間の値をとります。割引率が0に近いほど、将来の報酬は現在の価値に比べて軽視され、逆に1に近いほど、将来の報酬も現在の価値と同程度に重視されます。
例えば、割引率が0に近い場合、エージェントは目先の報酬を優先するようになり、長期的な利益をあまり考慮しなくなります。逆に割引率が1に近い場合、エージェントは長期的な報酬を重視し、目先の報酬を多少犠牲にしても将来の大きな報酬を得るための行動を選択します。このように、割引率の値はエージェントの行動に大きな影響を与えるため、適切な値を設定することが重要です。行動価値関数を用いることで、エージェントは最適な行動戦略を学習し、様々な課題を効率的に解決できるようになります。
| 項目 | 説明 |
|---|---|
| 強化学習 | 機械が試行錯誤を通じて学習する仕組み |
| エージェント | 学習を行う主体 |
| 報酬 | エージェントが行動の結果に応じて受け取るもの |
| 行動価値関数 Q(s, a) | 状態sで行動aをとった場合に将来得られる報酬の合計を割引率γで割り引いた値の平均 |
| 割引率 γ | 将来の報酬を現在の価値に換算するための係数 (0~1) |
| 割引率γ が0に近い場合 | 目先の報酬を優先、長期的な利益を軽視 |
| 割引率γ が1に近い場合 | 長期的な報酬を重視、目先の報酬を多少犠牲にする |
状態と行動の重要性

何かを学ぶとき、自分がどのような状況にいるのか、そして何ができるのかを理解することはとても大切です。行動価値関数もこれと同じで、状態と行動という二つの考え方が基本となっています。
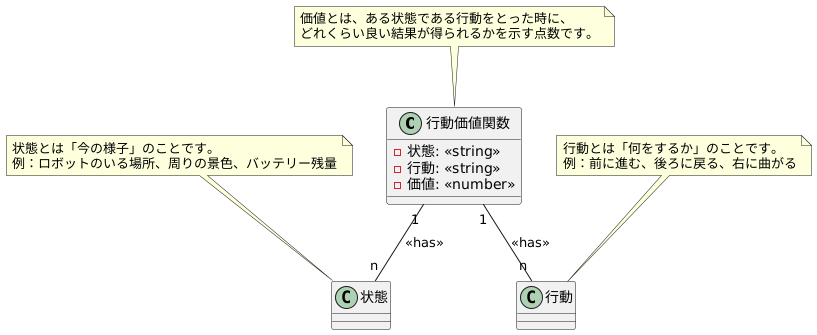
状態とは、簡単に言うと「今の様子」のことです。例えば、迷子になったロボットを想像してみてください。ロボットのいる場所、周りの景色、障害物の有無など、ロボットを取り巻くすべてのものが状態となります。迷路の構造や、ロボットのバッテリー残量なども状態の一部と言えるでしょう。状態は、状況を詳しく説明する情報のかたまりなのです。
次に、行動とは「何をするか」です。迷子になったロボットなら、「前に進む」「後ろに戻る」「右に曲がる」「左に曲がる」といった選択肢が考えられます。ロボットの腕や足、車輪の動きなど、ロボットが実際にできることが行動です。
行動価値関数は、この状態と行動の組み合わせに対して、それぞれに点数をつけます。この点数は、その状態である行動をとった時に、どれくらい良い結果が得られるかを示しています。例えば、ロボットが前に進んだらゴールに近づいた、壁にぶつかってしまった、などです。行動価値関数は、まるで宝の地図のように、どの行動をとれば良いかを教えてくれるのです。
どの状態でも、行動価値関数はそれぞれの行動に点数をつけます。点数が高い行動は良い結果につながりやすく、低い行動はあまり良くない結果につながりやすいことを示しています。ロボットは、この点数を参考にしながら、最も高い点数の行動を選び、ゴールを目指します。このように、状態と行動を理解することで、行動価値関数がどのように働くのかを深く理解することができます。
最適な行動の選択

強化学習とは、試行錯誤を通じて学習する人工知能の一種です。目的は、環境と相互作用しながら、長期的に得られる報酬を最大化することです。どのようにして、この目的を達成するのでしょうか。その鍵となるのが「行動価値関数」です。
行動価値関数は、ある状態において特定の行動をとった場合に、将来にわたってどの程度の報酬が期待できるかを示す指標です。例えば、迷路を考えてみましょう。各分岐点で、右に行くか左に行くか、いくつかの選択肢があります。行動価値関数は、それぞれの選択肢について、最終的にゴールにたどり着くまでの報酬を予測します。この予測は、過去の経験に基づいて学習されます。最初はランダムな行動をとり、成功や失敗から学び、徐々に正確な予測ができるようになります。
最適な行動の選択は、まさにこの行動価値関数に基づいて行われます。各状態において、行動価値関数が最大となる行動を選択することで、エージェントは長期的な報酬を最大化できると期待されます。これは、目先の利益にとらわれず、将来の報酬を見越した行動をとることを意味します。迷路の例では、一見すると遠回りに見える道でも、最終的にゴールまでの距離が短い場合、行動価値関数は高い値を示すでしょう。エージェントは、この高い値に基づいて、遠回りな道を選択し、結果的に最短経路でゴールにたどり着くことができます。
このように、行動価値関数は、強化学習において最適な行動戦略を見つけるための重要なツールです。過去の経験から学び、将来の報酬を予測することで、エージェントは複雑な環境でも最適な行動を選択し、目標を達成することが可能になります。まさに、試行錯誤を通じて賢くなる仕組みと言えるでしょう。
行動価値関数の学習

行動価値関数は、ある状態である行動をとった時に、将来どれだけの良い結果が得られるかを表す数値です。この関数は、機械学習の分野、特に強化学習において中心的な役割を果たします。人間や動物が試行錯誤を通じて学習するように、機械もまた、様々な行動を試してみて、その結果得られた報酬をもとに、どの行動が良いか悪いかを学習していきます。この学習方法を、行動価値関数の学習と呼びます。
具体的には、学習する機械(エージェント)は、周囲の状況(環境)とやり取りしながら、様々な状態と行動を経験します。そして、各行動の結果として得られた報酬を元に、行動価値関数を更新していきます。例えば、迷路を解くロボットの場合、状態はロボットの現在位置、行動は上下左右への移動、報酬はゴールに到達した時に得られる点数などとなります。ロボットは迷路の中で様々な行動を試すことで、どの行動がゴールへの近道となるかを学習していきます。
この学習を実現する代表的な手法の一つに、時間差分学習があります。時間差分学習では、現在の状態と行動に対する価値を、次の状態の価値と得られた報酬を使って更新します。分かりやすく言うと、将来得られる報酬を予想しながら、現在の行動の価値を評価していく方法です。例えば、ある行動をとった結果、次の状態がより良い状態になり、高い報酬が得られると予想できれば、その行動の価値は高く評価されます。
この更新作業を何度も繰り返すことで、行動価値関数は徐々に真の価値に近づき、エージェントはどの行動が最適かを判断できるようになります。迷路の例で言えば、ロボットは何度も迷路を探索することで、ゴールまでの最短経路を学習し、効率的にゴールに到達できるようになります。
学習の過程では、「探索」と「利用」のバランスが重要です。探索とは、未知の状態や行動を試すことで、新しい情報を得ることを指します。利用とは、現在の知識に基づいて、最も良いと思われる行動を選択することを指します。新しい行動を試すことでより良い行動が見つかる可能性もありますが、既知の最良の行動を繰り返した方が確実な結果が得られる場合もあります。この二つのバランスを適切に保つことで、効率的な学習を実現できます。例えば、迷路の探索では、いつも同じ道を通るだけでなく、ときどき未知の道に進むことで、より近道を見つける可能性が高まります。しかし、常に未知の道ばかり選んでいると、ゴールに到達するまでに時間がかかってしまう可能性もあります。そのため、探索と利用のバランスを適切に調整することが重要です。
応用事例

行動価値関数は、実に様々な場面で役立っています。機械の制御、遊び、資源のやりくり、病気の診断など、幅広い分野で応用され、成果を上げています。
例えば、機械の制御では、機械が周りの状況に応じて最も良い動きを学ぶために、この行動価値関数が使われます。具体的には、ロボットに目的となる動作を教え込む際、試行錯誤を通じて成功への道筋を見つけ出すのに役立ちます。うまく動けば価値が高いと判断し、失敗すれば価値が低いと判断することで、次第に最適な行動パターンを学習していくのです。
遊びの分野では、コンピュータが人間に勝つように学習する場面で使われます。例えば、囲碁や将棋のような複雑なゲームでは、膨大な選択肢の中から最善の一手を導き出す必要があります。行動価値関数を用いることで、過去の対戦データやシミュレーション結果を元に、どの手が勝利に繋がりやすいかを学習し、より強い人工知能を作り出すことが可能になります。
資源のやりくりでは、限られた資源を最も効率的に分配するために活用されます。資源の種類や量、需要の変動などを考慮しながら、どこにどれだけ資源を割り当てるかを決定する必要があり、行動価値関数は複雑な状況下でも最適な分配方法を見つけ出す手助けとなります。
病気の診断では、患者の状態に基づいて最適な治療法を選ぶ際に役立ちます。患者の年齢や症状、過去の治療歴など様々な情報を元に、どの治療法が最も効果的かを判断する必要があります。行動価値関数を用いることで、過去の症例データなどを分析し、患者一人ひとりに合わせた最適な治療法を提案することが可能になります。
近年では、深層学習と組み合わせることで、さらに複雑な問題にも対応できるようになってきており、今後の発展がますます期待されています。
| 分野 | 説明 |
|---|---|
| 機械の制御 | 機械が周りの状況に応じて最も良い動きを学ぶ。ロボットに目的となる動作を教え込む際、試行錯誤を通じて成功への道筋を見つけ出す。 |
| 遊び | コンピュータが人間に勝つように学習する。囲碁や将棋のような複雑なゲームで、膨大な選択肢の中から最善の一手を導き出す。 |
| 資源のやりくり | 限られた資源を最も効率的に分配する。資源の種類や量、需要の変動などを考慮しながら、どこにどれだけ資源を割り当てるかを決定する。 |
| 病気の診断 | 患者の状態に基づいて最適な治療法を選ぶ。患者の年齢や症状、過去の治療歴など様々な情報を元に、どの治療法が最も効果的かを判断する。 |