
大規模言語モデルの弱点:得意と不得意

AIを知りたい
先生、大規模言語モデルってすごいけど、苦手なことってあるんですか?

AIエンジニア
そうだね。例えば、高度な専門知識が必要な仕事は難しいよ。法律や科学の計算などは、論理的に理解しているというより、学習したデータに基づいてそれっぽく答えているだけなんだ。
AIを知りたい
へえ、そうなんですね。じゃあ、最新のニュースとかも苦手なんですか?
AIエンジニア
学習した時点の情報しか知らないから、最新の情報は苦手だったけど、最近はインターネットで検索できるようになって、最新情報にも対応できるようになってきているよ。それと、すごく長い文章も苦手で、長すぎるとうまく理解できないこともあるんだ。
大規模言語モデルの不得意タスクとは。
人工知能の言葉で「大規模言語モデルの苦手な仕事」というものがあります。大規模言語モデルは、規模が大きくなるほど色々なことができるようになりますが、苦手な仕事も存在します。具体的には、高度な専門知識が必要な仕事です。法律や科学の計算などは、論理的に理解して答えを出すのが苦手です。専門的な知識を教えれば、少し理解しているように見える答えを出すこともありますが、最新の情報を学習していないため、正確な答えにならないこともあります。ただし、インターネットで検索できる新しいモデルも出てきており、最新情報にも対応できるようになってきています。また、長い文章を扱うのも苦手です。文章の繋がりを計算する仕組みはありますが、扱える文字数に限りがあるため、長すぎる文章では精度が落ちることがあります。しかし、どの仕事も数年のうちに大きく改善しており、今は苦手とされている分野もすぐに克服できるようになるでしょう。
万能ではない大規模言語モデル

近頃話題の大規模言語モデル、略して言語モデルは、目覚ましい進歩を遂げ、様々な作業をこなせるようになりました。まるで何でもできる魔法の箱のように見えるかもしれません。しかし、実際には得意な分野と不得意な分野があります。
言語モデルは、インターネット上の膨大な量の文章や会話といったデータを学習することで、言葉の使い方や並び方の規則性を学びます。この学習を通して、人間のように自然な文章を作り出したり、質問に答えたりすることができるようになります。まるで言葉を巧みに操る達人のようです。
しかし、言語モデルの能力は、学習したデータの種類や量に大きく左右されます。例えば、特定の専門分野に関するデータが少ない場合、その分野の質問にうまく答えられないことがあります。また、学習データに偏りがある場合、その偏りを反映した回答をしてしまう可能性もあります。そのため、どんな質問にも完璧に答えることは難しいのです。
言語モデルは、あくまでも道具の一つです。包丁が料理に役立つ道具であるように、言語モデルも文章作成や情報検索といった作業に役立つ道具です。包丁でネジを締められないように、言語モデルにもできないことがあります。
言語モデルをうまく活用するためには、その特性を正しく理解し、適切な作業に使うことが大切です。万能な解決策ではないことを認識し、得意な分野でその能力を発揮させることで、私たちの生活や仕事をより豊かに、より便利にしてくれるでしょう。まるで頼りになる助手のようです。
| 項目 | 内容 |
|---|---|
| 概要 | 大規模言語モデル(言語モデル)は様々な作業をこなせるが、得意・不得意な分野が存在する |
| 学習方法 | インターネット上の膨大な量の文章や会話データを学習し、言葉の使い方や並び方の規則性を学ぶ |
| 能力 | 自然な文章作成、質問への回答など。学習データの種類や量に大きく左右される |
| 限界 | 学習データが少ない分野への対応が難しい。学習データの偏りを反映した回答をしてしまう可能性がある |
| 活用方法 | 特性を理解し、適切な作業に使う。万能ではないことを認識し、得意な分野で能力を発揮させる |
| 役割 | 文章作成や情報検索といった作業に役立つ道具 |
専門知識の壁

巨大言語モデルは、広く知られた知識に関する問いにはある程度的確に回答できますが、高度な専門知識が求められる仕事は不得意としています。たとえば、法律や医療、あるいは自然の仕組みを探る学問といった分野では、専門用語や複雑な概念を正しく理解し、適切な判断をすることが必要です。巨大言語モデルは、学習に使われた情報をもとに、もっともらしい文章を作り出すことはできますが、内容を本当に理解しているわけではありません。そのため、専門的な知識に基づいた判断や推論は難しく、間違った情報を示してしまう可能性もあります。
法律の分野を考えてみましょう。裁判で争われている事柄について、巨大言語モデルに判例を調べて意見をまとめるように指示したとします。すると、一見筋の通った文章が生成されます。しかし、その文章は、過去の判例から表面的に言葉を組み合わせただけで、法律の精神や判例が示す真の意味を理解しているわけではありません。そのため、実際には適用できない判例を根拠にしたり、重要な論点を欠落させたりするといった問題が起こる可能性があります。医療の分野でも同様です。患者の症状を入力して診断を求めても、巨大言語モデルは医学の専門家のように症状を総合的に判断することはできません。誤った診断を下し、適切な治療の機会を逃してしまう危険性さえあります。
自然科学の分野では、新しい発見や理論の構築が常に求められています。巨大言語モデルは既存の知識を組み合わせることはできますが、独創的な発想や仮説の検証を行うことはできません。複雑な数式や実験データの解析も苦手です。このように、巨大言語モデルを専門分野で役立てるには、追加の学習や外部のデータベースとの連携といった工夫が必要となります。専門家による確認や修正も欠かせません。巨大言語モデルは便利な道具ですが、その限界を理解し、適切な使い方をすることが重要です。
| 分野 | 巨大言語モデルの得意点 | 巨大言語モデルの不得意点 | 問題点 | 対策 |
|---|---|---|---|---|
| 法律 | 判例を調べて文章を作成 | 法律の精神や判例の真の意味を理解できない、適切な判例適用ができない、重要な論点の欠落 | 適用できない判例を根拠にする、重要な論点を欠落させる | 追加学習、外部データベース連携、専門家による確認・修正 |
| 医療 | 患者の症状を入力して文章を作成 | 症状を総合的に判断できない | 誤診、適切な治療機会の喪失 | 追加学習、外部データベース連携、専門家による確認・修正 |
| 自然科学 | 既存の知識を組み合わせる | 独創的な発想、仮説検証、複雑な数式・実験データ解析 | 新しい発見や理論構築ができない | 追加学習、外部データベース連携、専門家による確認・修正 |
情報の鮮度

知識の宝庫と言われる大規模言語モデルも、実は情報の鮮度には限界があります。学習に使われたデータは特定の時点までの情報で構成されているため、それ以降の世界の変化を捉えることはできません。まるで、過去の新聞を熟読した博識な人のようです。過去の出来事については詳細な知識を持っていますが、今日のニュースや最新の流行については全く知らないのです。
そのため、大規模言語モデルに最新の情報を反映させるには、定期的な更新が必要です。人の脳が新しい知識を学び続けるように、モデルにも継続的な学習が必要です。また、外部の情報源と連携させることで、常に最新の情報を取り込む試みもされています。これは、新聞を読むだけでなく、テレビやインターネットで最新の情報を得るようなものです。
近年、インターネットに接続できる大規模言語モデルが登場しました。これにより、情報の鮮度という課題は解決されつつあります。まるで、いつでもどこでも最新の情報を調べられる携帯端末を持ったようなものです。しかし、インターネット上の情報は玉石混交です。情報の信頼性や正確性を見極めることは、依然として重要な課題です。大規模言語モデルの出力は、あくまでも参考情報として捉え、他の情報源と照らし合わせ、多角的に検討することが大切です。さもなければ、誤った情報に惑わされてしまうかもしれません。情報の鮮度を保ちつつ、その真偽を見極める目を養うことが、大規模言語モデルを正しく活用する上で不可欠です。
| 大規模言語モデルの特性 | 例え | 課題と解決策 |
|---|---|---|
| 情報の鮮度に限界 学習データの時点までの情報 |
過去の新聞を読んだ博識な人 過去の出来事には詳しいが、最新の情報は知らない |
定期的な更新 継続的な学習 外部の情報源との連携 |
| インターネット接続型が登場 最新情報取得が可能 |
最新の情報を調べられる携帯端末 | 情報の信頼性・正確性の見極め 他の情報源との照合 多角的な検討 |
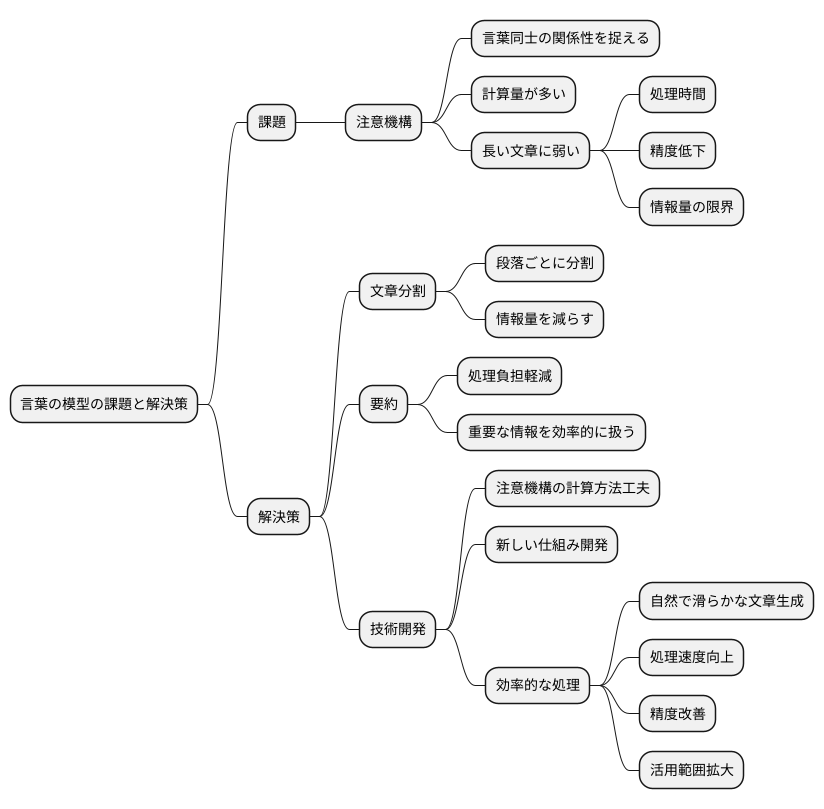
長い文章の処理

近年の言葉の模型は、文章中の繋がりに目を向ける仕組みを使って意味を理解しています。この仕組みは「注意機構」と呼ばれ、言葉同士の関係性を捉えるのに役立ちます。しかし、この仕組みは多くの計算を必要とするため、特に長い文章を扱うのが苦手です。ある一定の長さを超える文章を入力すると、処理に時間がかかったり、言葉の意味を正確に捉えられなくなったりすることがあります。これは、言葉の模型が一度に扱える情報量に限界があるためです。
この問題を解決するために、長い文章をいくつかの短い部分に分けて処理する方法があります。例えば、文章全体を段落ごとに分割し、それぞれの段落を言葉の模型に与えることで、一度に処理する情報量を減らすことができます。また、文章全体の意味を短い言葉でまとめる「要約」の技術も有効です。要約された文章を言葉の模型に入力することで、処理の負担を軽減し、重要な情報を効率的に扱うことができます。
さらに、言葉の模型が一度に扱える情報量を増やすための研究も進んでいます。例えば、注意機構の計算方法を工夫したり、新しい仕組みを開発したりすることで、より長い文章を効率的に処理できるようになることが期待されます。これらの技術開発によって、将来はもっと自然で滑らかな長い文章の生成や理解が可能になるでしょう。また、長い文章を扱う上での処理速度の向上や精度の改善も見込まれます。これらの進歩は、様々な分野で言葉の模型の活用範囲を広げることに繋がると考えられます。
進化し続ける技術

近ごろ、よく耳にするようになった「大規模言語モデル」。まるで人が書いたかのような文章を生成したり、難しい質問に答えたりと、まさに日進月歩で進化を続けています。今でさえ目覚ましい発展を見せていますが、その歩みは止まることなく、現在苦手としている仕事も、近い将来には難なくこなせるようになるでしょう。
このめざましい進化の背景には、研究開発のたゆまぬ努力があります。開発者たちは、モデルの規模を大きくしたり、学習させる情報の質を高めたりすることで、大規模言語モデルの性能を飛躍的に向上させているのです。たとえば、より多くの情報を扱えるようにモデルの規模を拡大することで、複雑な内容の文章を理解し、生成することが可能になります。また、質の高い情報を学習させることで、より正確で信頼性の高い結果を出せるようになります。こうした地道な積み重ねが、数年後には今抱えている多くの問題を解決してくれるでしょう。
大規模言語モデルは、私たちの暮らしや仕事に大きな変化をもたらす可能性を秘めています。想像してみてください。あらゆる情報を瞬時に探し出し、整理してくれる。外国語をまるで母国語のように操り、世界中の人々と自由に会話ができる。創造的な文章を生成し、新しいアイデアを生み出す。そんな未来が、すぐそこまで来ているのです。
大規模言語モデルの進化から目を離さず、最新の技術をよく理解することで、その潜在能力を最大限に引き出すことができます。今後の発展に大きな期待を寄せながら、その特性を正しく理解し、上手に活用していくことが大切です。そうすることで、より豊かで便利な社会を築き、より創造的で充実した人生を送ることができるようになるでしょう。
| 項目 | 内容 |
|---|---|
| 現状 | まるで人が書いたかのような文章生成、難しい質問への回答が可能。 |
| 将来展望 | 現在苦手な仕事もこなせるようになる。 |
| 進化の背景 | 研究開発のたゆまぬ努力(モデル規模の拡大、学習情報質の向上など) |
| 具体的な進化例 | モデル規模拡大 → 複雑な文章の理解・生成 質の高い情報学習 → 正確で信頼性の高い結果 |
| 将来への影響 | 暮らしや仕事に大きな変化をもたらす可能性あり。 例:情報検索・整理、多言語コミュニケーション、創造的な文章生成、新アイデア創出 |
| 私たちへの提言 | 進化から目を離さず、最新技術を理解し、潜在能力を最大限に引き出し、特性を正しく理解し、上手に活用していく。 |