
ルールベース機械翻訳:黎明期の機械翻訳

AIを知りたい
先生、「ルールベース機械翻訳」って、どういう仕組みなんですか?なんか難しそうでよくわからないです。

AIエンジニア
簡単に言うと、人間が作った翻訳の規則に基づいて、コンピュータが翻訳を行う仕組みだよ。例えば、「私はご飯を食べます」を英語に翻訳する場合、「私は→I」「ご飯→rice」「食べます→eat」のように、単語や文法のルールを大量にコンピュータに覚えさせて、それを使って翻訳させるんだ。
AIを知りたい
なるほど。辞書みたいな感じで、単語を一つずつ置き換えていくんですね。でも、それだと複雑な文章はうまく翻訳できないんじゃないですか?
AIエンジニア
その通り!単語だけでなく、文法のルールも覚えさせる必要があるし、ことわざや慣用句など、例外的な表現にも対応させないといけない。だから、ルールを作るのがとても大変で、時間もかかるんだ。完璧なルールを作るのは難しいから、どうしても翻訳の精度に限界があったんだよ。
ルールベース機械翻訳とは。
人工知能に関わる言葉である「規則による機械翻訳」について説明します。規則による機械翻訳は、1970年代の終わり頃までは広く使われていた方法です。機械翻訳の中でも最も古い方法ですが、翻訳の精度を上げるにはとても長い時間が必要だったので、まだ実用的なレベルには達していませんでした。
初期の機械翻訳

機械による言葉の置き換え、いわゆる機械翻訳の始まりは、ルールに基づいた翻訳、つまりルールベース機械翻訳でした。これは、人が言葉の文法や単語の対応関係などを計算機に教え込むことで翻訳を可能にする方法です。外国語を学ぶ際に、文法書や辞書を使うのと同じように、計算機にも言葉のルールを一つ一つ丁寧に教えていくのです。
具体的には、まず文法の規則を計算機に記憶させます。例えば、「英語の文は主語+動詞+目的語の順序」といった基本的なルールから、「関係代名詞を使う場合の決まり」といった複雑なルールまで、様々な文法規則を教え込むのです。次に、単語と単語の対応関係、例えば「英語の”apple”は日本語の”りんご”」といった対応を大量に覚えさせます。まるで巨大な辞書を計算機の中に作り上げるような作業です。
そして、翻訳したい文章を計算機に入力すると、計算機はまず文の構造を解析します。主語はどこで、動詞はどこかと、まるで人が文章を読むように文を理解しようとします。次に、記憶している文法規則に基づいて、文章の各部分をどのように変換すればよいかを判断します。さらに、単語の対応関係を参照しながら、一つ一つの単語を置き換えていきます。こうして、元の文章とは異なる言語の文章が生成されるのです。
この方法は、初期の機械翻訳を支えた重要な技術でした。しかし、言葉は生き物のように常に変化し、文脈によって意味も変わります。そのため、全てのルールを教え込むことは難しく、複雑な文章や比喩表現などは正確に翻訳できない場合もありました。それでも、ルールベース機械翻訳は、後の機械翻訳技術の礎となり、より高度な翻訳技術へと発展していくための重要な一歩となりました。
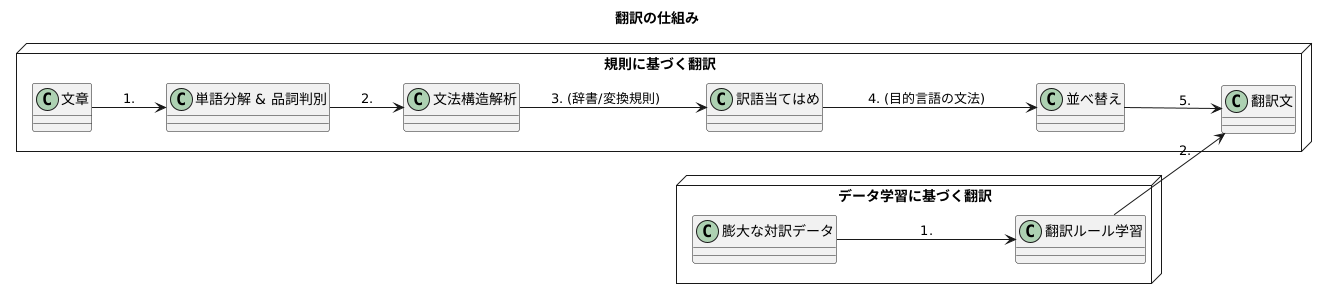
翻訳の仕組み

翻訳とは、ある言語で書かれた文章を別の言語の文章に変換する作業のことです。その仕組みは様々ですが、大きく分けて規則に基づく方法と膨大なデータから学習する方法があります。
規則に基づく翻訳の仕組みは、まず文章を単語ごとに分解し、品詞を判別します。例えば、「私は猫が好きです」という文章であれば、「私」は名詞、「は」は助詞、「猫」は名詞、「が」は助詞、「好き」は形容詞、「です」は助動詞と判断されます。次に、文法規則に基づいて単語の繋がりを解析します。「私」が主語、「猫」が目的語であることを特定し、文章全体の構造を把握します。そして、あらかじめ用意された辞書や変換規則を参照しながら、それぞれの単語に対応する訳語を当てはめていきます。「私」は「I」、「猫」は「cat」、「好き」は「like」といった具合です。最後に、目的語の言語の文法規則に沿って訳語を並べ替え、「I like a cat.」という翻訳文を作り上げます。
このように、規則に基づく翻訳は、人間が設定した文法規則や辞書を用いて、機械的に文章を変換していく作業と言えます。しかし、言語は例外や微妙なニュアンスに富んでおり、全ての状況を規則で網羅することは困難です。そのため、近年では、大量のデータから翻訳のパターンを学習する新しい翻訳方法が主流になりつつあります。この方法では、人間が規則を設定する代わりに、コンピュータが膨大な量の対訳データから翻訳のルールを自動的に学習します。これにより、より自然で正確な翻訳が可能となっています。
精度の課題

規則に基づいた機械翻訳は、分かりやすい仕組みで、初期の機械翻訳で大きな役割を果たしました。しかし、正確さには問題がありました。言葉は非常に複雑で、全ての文法や例外を網羅するのは難しいです。そのため、規則に基づいた機械翻訳では、複雑な文の構造や慣用句などを正しく翻訳するのが難しいことがありました。例えば、「腹が立つ」を直訳して「stomach stands up」とすると、英語話者には意味が通じません。これは、慣用表現を言葉通りに翻訳してしまう例です。また、「雨」や「雪」など、状況に応じて様々な表現を持つ言葉も、規則だけで全てを網羅するのは困難です。
加えて、言葉は常に変化しており、新しい言葉や言い回しが生まれてきます。これらの変化に対応するには、いつも新しい規則を追加する必要があり、維持管理に多くの手間がかかっていました。規則を一つ追加する度に、他の規則との整合性を確認する必要があり、膨大な作業量となる場合もありました。このような維持管理の大変さも、規則に基づいた機械翻訳の大きな課題でした。
さらに、異なる言葉の間には、文の構造や表現方法に大きな違いがあります。日本語は、主語が省略されることがよくありますが、英語では主語を明確にする必要があります。このような言葉ごとの違いを全て規則で表現するのは非常に困難で、翻訳の正確さを向上させる上で大きな壁となっていました。これらの問題は、後の機械翻訳技術の進歩に繋がる重要なきっかけとなりました。より高度な翻訳を実現するために、新たな方法の開発が必要とされたのです。
| 項目 | 説明 | 例 |
|---|---|---|
| 仕組み | 分かりやすい規則に基づく | – |
| 役割 | 初期の機械翻訳で大きな役割 | – |
| 問題点 | 正確さに欠ける | – |
| 課題1 | 言葉の複雑さ(文法、例外) | – |
| 課題2 | 複雑な文構造、慣用句の翻訳 | 「腹が立つ」→「stomach stands up」 |
| 課題3 | 状況依存表現の多様性 | 「雨」「雪」 |
| 課題4 | 言葉の変化への対応(新規規則追加、維持管理) | – |
| 課題5 | 異なる言語間の構造、表現の差異 | 日本語の主語省略 vs 英語の主語必須 |
| 結果 | 後の機械翻訳技術の進歩のきっかけ | – |
膨大な作業時間

質の高い言葉の置き換えを機械でできるようにするためには、たくさんの言葉の決まりや単語帳を作る必要があります。これは、言葉の専門家や翻訳をする人にとって、とても時間のかかる仕事です。一つの言葉の組み合わせの決まりを作るだけでも、数年もの長い期間がかかることもありました。さらに言葉は地域や時代によって変わるため、一度作った決まりをいつも新しくしていく必要もあります。この決まりを維持するための作業も、決まりに基づいた機械翻訳の大きな負担となっていました。
例えば、ある言葉が別の言葉に置き換えられるとき、文脈によって適切な訳語が異なる場合があります。「走る」という言葉一つとっても、「車が走る」「人が走る」「川が走る」など、それぞれ異なる言葉への置き換えが必要です。このような複雑なルールを全て人間の手で作成し、維持していくのは大変な作業です。しかも、新しい言葉や表現が次々と生まれる現代社会において、この作業は終わりがありません。
このように、時間と労力をかけて決まりをきちんと作っても、完璧な翻訳の正しさを得ることは難しく、実際に使えるようにするには限界がありました。たとえ多くの専門家が長い時間をかけてルールを作り上げたとしても、全ての例外や微妙なニュアンスを網羅することは不可能です。そのため、ルールベースの機械翻訳は、ある程度の精度で翻訳することはできても、人間の翻訳者のような自然で正確な翻訳を生み出すことは困難でした。この限界が、より高度な翻訳技術の開発へとつながっていくのです。
| 課題 | 詳細 | 影響 |
|---|---|---|
| ルール作成の負担 |
|
機械翻訳の大きな負担 |
| 文脈への対応の難しさ |
|
完璧な翻訳の正しさを得ることが困難 |
| ルールの限界 |
|
自然で正確な翻訳が難しい / より高度な技術の開発促進 |
歴史的意義

言葉の意味を機械に理解させ、異なる言葉へと置き換える機械翻訳は、長い年月をかけて発展してきました。その発展の過程で、基礎となる重要な技術として確立されたのが、規則に基づいた機械翻訳です。これは、まるで人が翻訳をするように、言葉の並び方や文法の規則を細かく定め、それを機械に教え込む手法です。
人間が言語を扱う複雑な過程を、明確な規則として書き表す作業は、大変な労力を要しました。しかし、その努力によって築かれた言葉の構造や文法に関する知識は、その後の機械翻訳技術の発展に大きく貢献しました。現在主流となっている統計的な手法や、人間の脳の仕組みを模倣した神経回路網を用いる手法など、最新の技術の中にも、規則に基づいた機械翻訳の考え方が息づいています。
膨大なデータから言葉のつながりを学習する統計的手法や、文脈を理解し、より自然な翻訳を可能にする神経回路網といった新しい技術が登場した現在でも、規則に基づいた機械翻訳は完全に過去の物になったわけではありません。特定の専門分野の用語や、限られた範囲の言葉を扱う場合には、その正確さと効率性の高さから、現在も活用されています。例えば、法律や医学といった専門性の高い分野では、正確な翻訳が求められます。このような場面では、厳密に定義された規則に基づいて翻訳を行う手法が有効です。
このように、規則に基づいた機械翻訳は、機械翻訳の進化における礎石としての役割を果たし、その知見は現代の技術にも受け継がれています。過去の技術を土台として、機械翻訳は更なる進化を続けていくでしょう。
| 機械翻訳技術 | 説明 | 利点 | 欠点 | 現在 |
|---|---|---|---|---|
| 規則ベース | 文法規則や辞書に基づいて翻訳 | 正確、特定分野に有効 | 複雑な文や新しい表現に弱い、構築に時間と労力が必要 | 特定専門分野(法律、医学など)で活用 |
| 統計ベース | 大量のデータから言語のパターンを学習 | 自然な翻訳、大量データで高精度 | データに依存、文脈理解が不十分な場合がある | 主流 |
| ニューラルネットワーク | 人間の脳の仕組みを模倣した学習 | 文脈理解、自然な翻訳 | 大量のデータと計算資源が必要、解釈が難しい | 主流 |
今後の展望

機械翻訳の世界は、日進月歩で進化を続けています。統計的機械翻訳やニューラル機械翻訳といった手法は、膨大な量のデータを学習に用いることで、高い翻訳精度を達成しています。しかし、これらの手法は、学習データが少ない言語や専門分野においては、十分な性能を発揮できないという課題を抱えています。例えば、稀少言語の翻訳や、医学・法律といった専門性の高い分野の翻訳では、データ不足のために誤訳が生じやすいという問題があります。
このような状況下で、改めて注目を集めているのが、ルールベース機械翻訳です。ルールベース機械翻訳は、言語学の専門家によって作成された規則に基づいて翻訳を行う手法です。データ量が少なくても、専門家の知識を活用することで、一定水準の翻訳精度を確保できる点が大きな強みです。そのため、今後、このルールベース機械翻訳と、統計的機械翻訳やニューラル機械翻訳といった他の手法を組み合わせることで、より高精度で、様々な状況に対応できる翻訳システムの開発が期待されています。
具体的には、ルールベース機械翻訳を、他の手法では対応が難しい部分を補う役割として活用することで、より精度の高い翻訳が可能になると考えられます。例えば、ある特定の言い回しや慣用句などは、データが少ないために他の手法では正確に翻訳できない場合がありますが、ルールベース機械翻訳でその部分を補うことで、自然で正確な翻訳を実現できます。また、医学や法律といった特定の分野に特化した翻訳システムの開発においても、ルールベース機械翻訳の技術は、専門用語や表現の正確な翻訳を支える上で、今後も重要な役割を担うと考えられます。このように、様々な機械翻訳手法の長所を組み合わせることで、より高精度で、より多くの場面で活用できる機械翻訳システムの実現につながると期待されています。
| 機械翻訳手法 | 概要 | 長所 | 短所 | 今後の展望 |
|---|---|---|---|---|
| 統計的機械翻訳/ニューラル機械翻訳 | 膨大なデータを用いて学習 | データが豊富な言語/分野で高精度 | データが少ない言語/分野では性能不足 | 各手法の長所を組み合わせることで、高精度で様々な状況に対応できる翻訳システムの開発が期待される。ルールベース機械翻訳は、他の手法では対応が難しい部分を補う役割として活用される。 |
| ルールベース機械翻訳 | 言語学専門家が作成した規則に基づき翻訳 | データ量が少なくても一定水準の精度確保可能 専門家の知識を活用 |
– | |
| ハイブリッド機械翻訳 | ルールベースと統計的/ニューラル機械翻訳の組み合わせ | 高精度、様々な状況への対応力向上 | – |