事前学習:巨大言語モデルの土台

AIを知りたい
先生、「事前学習」って一体何ですか?難しそうでよくわからないです。

AIエンジニア
そうだね、難しく感じるかもしれないね。簡単に言うと、AIに言葉を理解させるための最初の訓練のようなものだよ。たくさんの文章を読ませて、言葉の使い方や意味を覚えさせるんだ。
AIを知りたい
たくさんの文章を読ませることで、AIが言葉を覚えるんですね。まるで人間の子どもに言葉を教えているみたいですね!
AIエンジニア
まさにその通り!たくさんの文章から言葉のルールや知識を学ぶことで、AIは人間のように言葉を理解し、使えるようになるんだよ。
事前学習とは。
人工知能に関する言葉である「事前学習」について説明します。事前学習とは、人間でいうと、言葉を覚える前の、基礎的な学習のようなものです。言葉の力やたくさんの単語、色々な知識を学ぶために、機械に自分で学習させます。これは、大規模言語モデルを作るための最初の段階にあたります。学習には、たくさんの文章データを使います。具体的には、データをまず集め、次にデータを整理し、最後に、単語を予測する練習を機械にさせます。
はじめに

近年、言葉を操る人工知能が驚くほどの進化を見せています。この人工知能の中核を担っているのが、巨大言語モデルと呼ばれる技術です。まるで人が言葉を覚えるように、このモデルも多くの文章を読み込んで学習していきます。この学習過程は、事前学習と呼ばれ、人工知能が様々な仕事をこなせるようになるための土台作りにあたります。
人間が言葉を学ぶ際には、まず単語の意味や文の作り方といった基本を学びます。同じように、巨大言語モデルも膨大な量の文章データを読み込み、言葉の使い方や文の構成などを学び取っていきます。この事前学習では、特定の作業を教えるのではなく、言語に関する一般的な知識を幅広く吸収させることが重要です。まるでスポンジが水を吸うように、あらゆる種類の文章から知識を吸収することで、言語の構造や意味を理解していくのです。
この事前学習は、非常に時間と計算資源を必要とする大規模な作業です。しかし、この段階でしっかりと言語の基礎を学ぶことで、後の段階で様々な作業に対応できる柔軟性が生まれます。例えるなら、土台がしっかりとした建物は、どんな天候にも耐えられるのと同じです。事前学習によって築かれた強固な言語理解は、巨大言語モデルが様々なタスクをこなすための、なくてはならない基盤となっているのです。この事前学習という土台があるからこそ、質問への回答や文章の作成、翻訳など、多様な作業をこなせるようになるのです。まさに、巨大言語モデルの驚異的な能力の源泉と言えるでしょう。
言葉の学習準備

言葉の学習を始める準備は、家づくりに例えると、基礎工事をしっかり行うようなものです。まず、良質な学習データを集めることが大切です。これは、家を建てるための材料を集めるようなものです。学習データは、様々な種類の書籍、新聞記事、インターネット上の情報など、多様な情報源から集められます。まるで、木材やコンクリート、鉄筋など、様々な材料を集めるように、多様なデータを集めることで、より頑丈で、多様な表現に対応できる土台を作ることができます。
次に、集めたデータを整理する作業を行います。これは、集めた建築材料をきれいに整え、必要な形に加工するようなものです。この作業を前処理と言い、集めたデータの中に含まれる不要な情報を取り除いたり、整理したりする過程です。例えば、句読点や記号といった不要な文字を取り除いたり、同じ情報が重複している場合は一つにまとめたりします。また、文章を単語や文節に分割する作業も行います。この前処理を丁寧に行うことで、後の学習がスムーズに進み、より良い結果を得ることができます。前処理は、家の基礎工事と同じように、目に見えにくい部分ですが、学習全体の質を左右する非常に重要な作業です。
もし、前処理が不十分だと、ノイズと呼ばれる不要な情報が混ざったまま学習を進めることになります。これは、欠陥のある材料を使って家を建てるようなものです。完成した家は脆く、すぐに壊れてしまうかもしれません。同様に、ノイズの混ざったデータで学習したモデルは、正確な情報を理解できず、誤った判断をしてしまう可能性があります。そのため、言葉の学習準備において、データ収集と前処理は、質の高い家を建てるための基礎工事と同じくらい重要な工程と言えるでしょう。
言葉の予測学習

言葉の予測学習とは、膨大な量の文章データをモデルに与え、次に来る言葉を予測させる学習方法です。まるで、子供が絵本を読んでもらい、次にどんな言葉が来るのかを想像する遊びのようなものです。例えば、「今日は晴れ」という文章の後に続く言葉を予測させる場合を考えてみましょう。モデルは、学習データの中で「今日は晴れ」という部分に似た表現を探し、その後にどのような言葉が続いているかを調べます。学習データの中に「今日は晴れですね」「今日は晴れだから」「今日は晴れで気持ちがいい」といった文章がたくさん含まれていれば、モデルは「ですね」「だから」「で」「気持ちがいい」といった言葉が後に続く可能性が高いことを学習します。
この学習を繰り返すことで、モデルは言葉同士の関係性や文脈を理解していきます。例えば、「今日は晴れ」の後に「寒い」という言葉が来ることは少ないと学習します。また、「今日は晴れ」の後に続く言葉として「ですね」のような相づちの言葉や、「だから」のような接続詞、「気持ちがいい」のような状態を表す言葉など、様々な種類の言葉があり、それぞれが持つ役割や意味の違いについても学習します。
さらに、多くの文章に触れることで、言葉の並び方の規則性や、より自然で滑らかな表現方法も学習していきます。まるで、子供がたくさんの物語を聞くことで、自然と語彙や表現力を豊かにしていくように、モデルもデータから言語の構造を学んでいきます。そして、最終的には、与えられた文章に対して、次に来る言葉を高い精度で予測できるようになるのです。この予測能力こそが、様々な言語処理タスクの基礎となる重要な能力であり、文章の生成や翻訳、質問応答など、様々な場面で活用されています。まさに、言葉を操るための土台となる能力を身につける学習なのです。

自己教師あり学習

近年、人工知能の分野で注目を集めているのが自己教師あり学習です。これは、人間が用意した正解データを使わずに、データ自身に潜む構造や規則性を学習する方法です。まるでパズルのように、データの一部を隠したり、順番をバラバラにしたりすることで、元の状態に戻すことを繰り返す中で、データの持つ本質的な特徴を捉えることができるのです。
例えば、文章を扱う場合を考えてみましょう。ある文章の一部を隠します。すると、隠された部分を予測するために、モデルは前後の文脈をよく理解する必要が出てきます。「桜が綺麗に咲いて、たくさんの人が___見物に訪れました。」という文章で、隠された部分が「花」だと予測するためには、「桜」「綺麗」「見物」といった周囲の言葉から、花見の情景を思い浮かべる必要があるからです。このように、隠された部分を予測するタスクを通して、モデルは言葉の意味や文法、文脈の理解といった能力を自然と身につけていくのです。
また、画像を扱う場合も同様です。画像の一部を隠して、隠された部分を復元させることで、モデルは画像全体の構造や物体の特徴を学習します。例えば、猫の顔の一部が隠されていても、残りの部分から耳や髭、目の形などを予測することで、全体像を復元し、猫の特徴を学習していくのです。
このように、自己教師あり学習は、大量のデータから効率的に学習を行うことができるため、近年の人工知能の発展に大きく貢献しています。特に、大量のラベル付きデータを作成することが難しい分野では、この自己教師あり学習が威力を発揮します。今後、さらに様々な分野への応用が期待される、重要な学習方法と言えるでしょう。
| 学習方法 | 概要 | 例(文章) | 例(画像) |
|---|---|---|---|
| 自己教師あり学習 | 正解データを使わず、データ自身に潜む構造や規則性を学習する方法。データの一部を隠したり、順番をバラバラにしたりすることで、元の状態に戻すことを繰り返す中で、データの持つ本質的な特徴を捉える。 | 「桜が綺麗に咲いて、たくさんの人が___見物に訪れました。」の隠された部分を予測するために、モデルは前後の文脈をよく理解する必要があり、「花」を予測することで言葉の意味や文法、文脈の理解といった能力を身につける。 | 画像の一部を隠して、隠された部分を復元させることで、モデルは画像全体の構造や物体の特徴を学習する。例えば、猫の顔の一部が隠されていても、残りの部分から全体像を復元し、猫の特徴を学習していく。 |
巨大言語モデルの能力向上

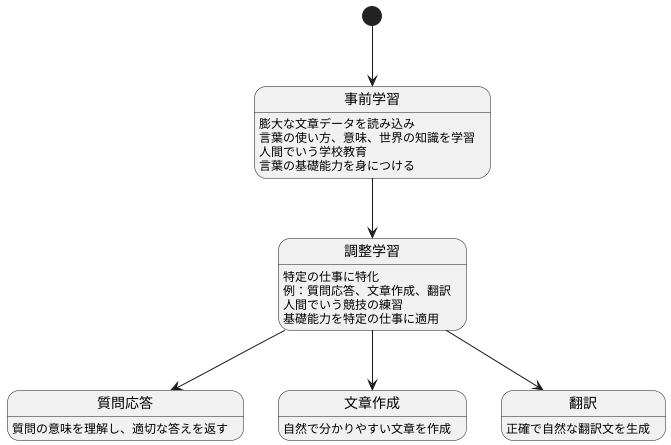
{巨大な言語モデルは、人間のように言葉を扱うことを目指して作られた、とても大きな計算機プログラムです。このプログラムは、膨大な量の文章データを読み込む「事前学習」を通して、言葉の使い方や意味、世界の知識などを学びます。この事前学習は、まるで人間が学校で様々な教科を学ぶようなもので、言葉を操るための基礎能力を身につける段階と言えます。
事前学習を終えたモデルは、特定の仕事に特化するための「調整学習」と呼ばれる訓練を受けます。例えば、質問に答える、文章を作る、言葉を翻訳するといった具体的な仕事内容に合わせて、モデルの能力をさらに磨き上げるのです。この調整学習は、スポーツ選手が基礎トレーニングを積んだ後に、特定の競技の練習をすることと似ています。基礎トレーニングで体幹や筋力を鍛え、調整学習で競技特有の技術を磨くことで、より高いパフォーマンスを発揮できるようになるのです。
巨大言語モデルも同様に、事前学習で言葉の基礎を学び、調整学習で特定の仕事に合わせた能力を身につけることで、様々な場面で活躍できるようになります。例えば、質問に答える仕事であれば、質問の意味を正確に理解し、適切な答えを返すことができるようになります。文章を作る仕事であれば、自然で分かりやすい文章を作成できるようになります。また、言葉を翻訳する仕事であれば、正確で自然な翻訳文を生成できるようになります。
このように、事前学習は巨大言語モデルの潜在能力を引き出すための重要なステップです。事前学習によって培われた言葉に関する幅広い知識と能力は、その後の調整学習を通して様々な仕事に活かされ、私たちの生活をより豊かにしていく可能性を秘めていると言えるでしょう。
今後の展望

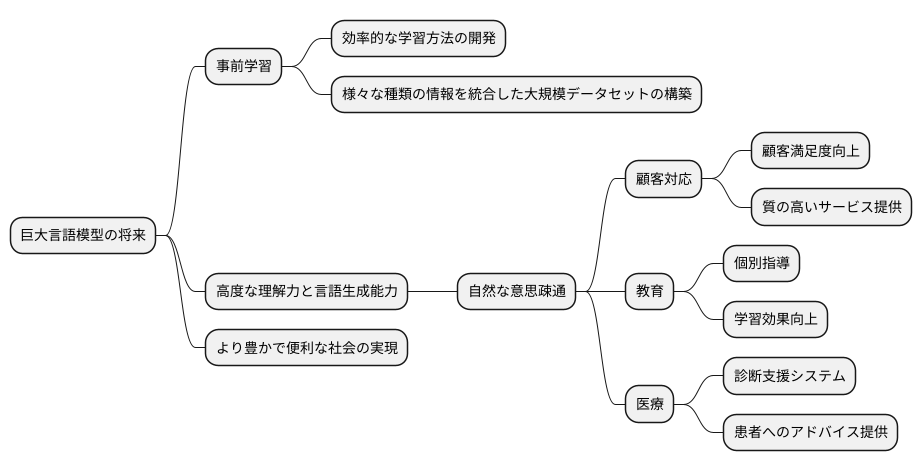
巨大言語模型の将来は、事前学習という土台の上に築かれると言っても過言ではありません。この技術は、まさに巨大言語模型の進化を支える屋台骨であり、今後ますます発展していくことが予想されます。
現在、研究者たちは様々な角度から事前学習の改良に取り組んでいます。例えば、限られた計算資源でより効率的に学習を進める方法の開発や、言語だけでなく画像や音声など様々な種類の情報を統合した大規模データセットの構築などが精力的に行われています。これらの研究が実を結べば、巨大言語模型はより高度な理解力と言語生成能力を獲得し、私たちの生活を一変させる可能性を秘めています。
より洗練された自然言語処理技術が実現すれば、人と機械の間の意思疎通は格段にスムーズになり、まるで人と人が会話するように自然なやり取りが可能になるでしょう。これは、単なる言葉のやり取りに留まらず、私たちの生活の様々な場面に大きな変化をもたらします。
例えば、顧客からの問い合わせに即座に対応できる高度な対話型システムが実現すれば、企業は顧客満足度を向上させ、より質の高いサービスを提供できるようになります。また、教育の現場では、生徒一人ひとりの理解度に合わせた個別指導が可能になり、学習効果の向上が期待できます。さらに、医療分野においては、医師の診断を支援するシステムや、患者の症状を理解し適切なアドバイスを提供するシステムなど、様々な応用が考えられます。このように、事前学習技術の進歩は、様々な分野で革新的なサービスを生み出し、より豊かで便利な社会を実現するための鍵となるでしょう。まるで魔法の呪文のように、私たちの未来を輝かしいものに変えてくれる可能性を秘めているのです。