
大規模言語モデルの知識:可能性と限界

AIを知りたい
先生、大規模言語モデルの知識って、どれくらい最新の情報まで知っているんですか?たとえば、つい最近のニュースのこととかもわかるんですか?

AIエンジニア
いい質問だね。大規模言語モデルは、学習した時点までの情報を持っているんだ。だから、たとえば、去年のニュースは知っているかもしれないけど、今日のニュースは知らない可能性が高いんだよ。
AIを知りたい
じゃあ、常に最新の情報を反映しているわけではないんですね。ということは、古い情報に基づいて間違った答えを返すこともあるんですか?
AIエンジニア
その通り。だから、大規模言語モデルの言うことをすべて鵜呑みにするのではなく、自分で確認することも大切なんだよ。特に、最新の情報が必要な場合は、ニュースサイトなどを参考にするといいね。
大規模言語モデルの知識とは。
人工知能で使われる『大規模言語モデルの知識』について説明します。大規模言語モデルというのは、インターネットなどにたくさんある文章を学習して、たくさんの知識を蓄えているものです。この知識のもとになっているのは、ニュース記事や研究論文、ウェブサイト、本、ネット掲示板への書き込みなど、色々な情報源です。そのため、大規模言語モデルは、常識や文化、社会、科学、技術など、幅広い分野の質問に答えることができます。しかし、大規模言語モデルの知識は、学習した時点の情報までしかないという限界があります。最近の出来事や新しい情報については、学習データに含まれていないため、情報が古くなっていることがあります。さらに、大規模言語モデルは、自分で体験したり、現実世界で感じたりした知識を持っていないため、そういった状況での理解や返答は苦手です。また、大規模言語モデルの知識は、学習データの質に大きく左右されます。間違った情報や偏りがあるデータで学習させると、大規模言語モデルの性能が下がってしまう可能性があります。
はじめに

ここ数年、人工知能の研究開発が盛んに行われており、中でも、大規模言語モデルは大きな注目を集めています。このモデルは、人間が書いた膨大な量の文章を読み込むことで学習し、まるで人間のように自然な文章を書いたり、質問に答えたりすることができるのです。このような能力は、モデルが学習を通して得た、莫大な知識に基づいています。この文章では、大規模言語モデルが持つ知識の源、その秘めた可能性、そして限界について詳しく調べていきます。
大規模言語モデルは、インターネット上に公開されているニュース記事、小説、ブログ記事、百科事典など、様々な種類の文章データを読み込むことで知識を獲得します。学習データが多ければ多いほど、モデルはより多くの知識を蓄え、より複雑な課題に対応できるようになります。まるで、人が多くの本を読むことで知識を深めていくように、大規模言語モデルもまた、大量のデータを取り込むことで知識を豊かにしていくのです。
大規模言語モデルの可能性は計り知れません。例えば、文章の自動生成、翻訳、要約、質疑応答など、様々な分野で活用が期待されています。また、創造的な文章作成や、新しい知識の発見にも役立つ可能性を秘めています。将来的には、人間の知的活動を支援する、なくてはならない存在になるかもしれません。
しかし、大規模言語モデルには限界も存在します。学習データに偏りがあると、モデルの出力にも偏りが生じることがあります。例えば、学習データに女性に関する情報が少ない場合、女性に関する質問に対して適切な回答を生成できない可能性があります。また、大規模言語モデルは、あくまでも学習データに基づいて文章を生成しているため、真偽を判断する能力は持ち合わせていません。そのため、出力された情報が必ずしも正しいとは限らないのです。これらの限界を理解した上で、適切に利用していくことが重要です。大規模言語モデルの知識の源泉、可能性、そして限界について多角的に考察することで、この技術への理解を深め、より良い活用方法を探っていきましょう。
| 項目 | 説明 |
|---|---|
| 知識の源 | インターネット上のニュース記事、小説、ブログ記事、百科事典など、様々な種類の文章データ |
| 可能性 | 文章の自動生成、翻訳、要約、質疑応答、創造的な文章作成、新しい知識の発見など |
| 限界 | 学習データの偏りによる出力の偏り、真偽判断能力の欠如 |
知識の源

知識の泉とも呼べる大規模言語モデルは、インターネットという広大な海に存在する膨大な量の文章データから知識を吸収しています。そのデータの種類は実に様々で、日々更新される新聞記事や専門家によって書かれた学術論文、知識の宝庫である書籍やあらゆる情報を発信するウェブサイト、個人の意見や考えが綴られたブログ記事、さらには人々の交流が活発な会員制交流サイトへの投稿まで、多岐にわたります。これらの多様な情報源こそが、大規模言語モデルが様々な分野の知識を学ぶための土台となっています。学習に用いるデータが多ければ多いほど、大規模言語モデルの知識は豊かになり、複雑で難しい質問にも答えることができるようになります。
大規模言語モデルは、これらの文章データを読み解くことで、言葉の意味や文の構成方法、言葉が使われる状況、そして世界で起こっている出来事に関する知識を学びます。この学習方法は、私たち人間が読書を通して知識を蓄える方法とよく似ています。まるで、膨大な数の書物を読破した博識な学者のように、大規模言語モデルは様々な情報を記憶し、整理しています。ただし、私たち人間とは異なり、大規模言語モデルは感情や経験に基づいた知識は持っていません。喜びや悲しみ、怒りや恐怖といった感情、そして実際に体験した出来事を通して得られる知識は、大規模言語モデルには存在しないのです。大規模言語モデルの知識は、あくまでも文章データから得られた情報に基づいているということを忘れてはなりません。この点を理解した上で、大規模言語モデルを適切に活用していくことが重要です。
| 項目 | 説明 |
|---|---|
| データソース | 新聞記事、学術論文、書籍、ウェブサイト、ブログ記事、会員制交流サイトへの投稿など |
| データ量 | 膨大 |
| 学習方法 | 文章データを読み解く |
| 学習内容 | 言葉の意味、文の構成方法、言葉が使われる状況、世界で起こっている出来事 |
| 知識の特徴 | 多様な分野、感情や経験に基づいた知識は持たない |
| 人間との類似点 | 読書を通して知識を蓄えるのと類似 |
| 人間との相違点 | 感情や経験に基づいた知識を持たない |
可能性

大規模言語モデル(LLM)は、様々な分野での活用が期待される大きな可能性を秘めています。
まず、質問応答システムでは、まるで人と会話するように、自然な言葉で質問を投げかけるだけで、的確な答えを得ることが可能になります。これは、情報収集を容易にし、学習や研究の効率を高めることに繋がります。また、文章生成においても、LLMは力を発揮します。例えば、メールの作成や記事の執筆、物語の創作など、様々な文章を自動で生成することが可能になります。これは、作業時間の短縮や創造的な表現の支援に役立ちます。
翻訳の分野でも、LLMは大きな変化をもたらします。異なる言語間でのコミュニケーションを円滑にし、国際的な交流やビジネスの拡大に貢献します。さらに、膨大な量の文章を要約する作業も、LLMは得意とします。長い論文や報告書などを短時間で要約することで、情報収集の効率化に繋がります。
LLMは、人間では処理しきれないほどの大量の情報を、高速で分析することができます。この能力は、複雑な問題の解決や、より良い意思決定を支援することに役立ちます。例えば、医療の現場では、患者の症状や検査結果から、適切な診断や治療方針を導き出すサポートをすることが期待されています。ビジネスの分野では、市場の動向や顧客のニーズを分析し、効果的な戦略策定を支援することが考えられます。
LLMは、常に学習を続け、進化し続ける存在です。新しい情報や知識を吸収することで、より高度な作業をこなせるようになったり、今まで対応できなかった分野に進出したりすることが可能になります。そして、この進化は私たちの生活をより豊かにし、社会の発展に大きく貢献していくと考えられています。今後のLLMの更なる発展に、大きな期待が寄せられています。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 質問応答システム | 自然な言葉での質問への的確な回答 | 情報収集の容易化、学習・研究の効率化 |
| 文章生成 | メール作成、記事執筆、物語創作 | 作業時間の短縮、創造的な表現の支援 |
| 翻訳 | 異なる言語間でのコミュニケーション | 国際的な交流やビジネスの拡大 |
| 要約 | 論文や報告書の要約 | 情報収集の効率化 |
| 医療 | 診断や治療方針の支援 | – |
| ビジネス | 市場分析、戦略策定支援 | – |
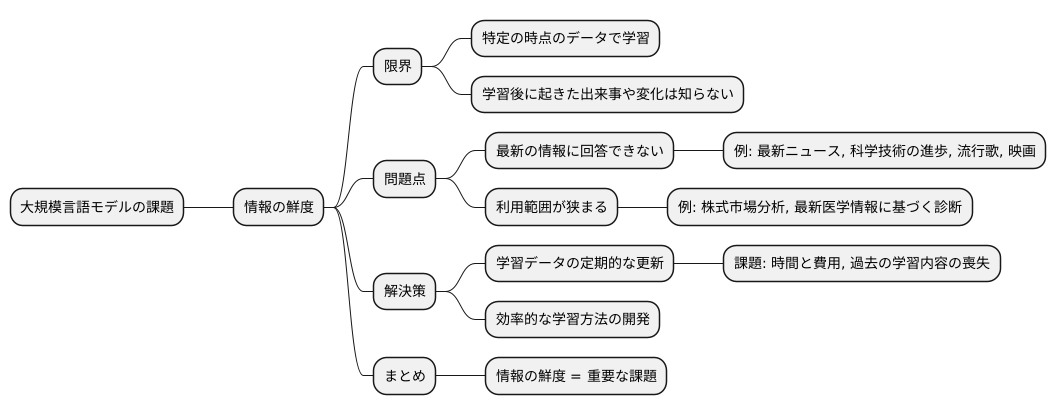
限界:時間のずれ

大規模言語モデルは、膨大な量の情報を蓄えており、様々な質問に答えることができます。しかし、その知識には限界があり、情報の鮮度という問題があります。これらのモデルは、特定の時点に収集されたデータで学習されます。つまり、学習後に起きた出来事や変化については知らないのです。
例えば、最新のニュースや科学技術の進歩について質問しても、学習データに含まれていないため、適切な回答は期待できません。最新の流行歌や話題の映画についても同様です。学習時点以降に発表されたものについては、情報を持っていません。
この情報のずれは、大規模言語モデルの利用範囲を狭める一因となっています。常に最新の情報を必要とする分野、例えば刻々と変化する株式市場の分析や、最新の医学情報に基づく診断などには、そのままでは不向きです。
この問題を解決するには、大規模言語モデルの学習データを定期的に更新する必要があります。しかし、膨大なデータを扱うため、更新には多大な時間と費用がかかります。また、頻繁に更新を行うと、過去の学習内容が失われる可能性もあります。過去の情報を維持しつつ、最新の情報を追加していくためには、効率的な学習方法を開発する必要があります。
情報の鮮度を保つことは、大規模言語モデルが真に役立つ道具となるために、今後克服すべき重要な課題と言えるでしょう。
限界:現実世界の欠如

大規模言語モデルは、膨大な量の文章データから学習を行います。そのため、言葉の繋がりや文法、知識などを習得することができます。しかし、学習に用いるのは文章データのみであるため、人間が五感を通じて得る現実世界の経験や感覚情報は持ち合わせていません。
例えば、リンゴについて説明する文章を読めば、リンゴは赤い果物で、甘酸っぱい味がすると理解できます。しかし、実際にリンゴを手に取って重さを感じたり、香りを嗅いだり、味わったりした経験はありません。そのため、「熟したリンゴの重さはどれくらいか」や「リンゴの香りはどんな香りか」といった、現実世界の感覚に基づく質問には、的確な答えを返すことが難しいです。文章で説明された知識は持っていても、実体験に基づく理解が欠けているからです。
同様に、人間の感情や倫理観についても、言葉で説明された内容は理解できても、実際に体験したわけではないため、深い理解はできません。例えば、「悲しみ」という言葉の意味や、悲しみを表す表現は理解できても、実際に悲しみを感じた時の心の痛みや苦しさは理解できません。倫理的なジレンマに直面した際の葛藤や、道徳的な判断の難しさも、実体験がないため、真に理解することは難しいのです。
このように、現実世界の経験や感覚情報の欠如は大規模言語モデルの大きな限界となっています。この限界を克服するために、様々な研究開発が行われていますが、人間のように現実世界を理解し、経験に基づいた判断ができるようになるには、まだ多くの課題が残されています。
| 項目 | 大規模言語モデルの特徴 | 具体例(リンゴ) | 具体例(感情・倫理観) |
|---|---|---|---|
| 学習データ | 膨大な量の文章データ | リンゴの説明文を読む | 悲しみや倫理の言葉の定義を読む |
| 知識の習得 | 言葉の繋がり、文法、知識などを習得 | リンゴは赤い果物で甘酸っぱい味だと理解 | 悲しみという言葉の意味や表現を理解、倫理的な言葉の定義を理解 |
| 限界 | 現実世界の経験や感覚情報の欠如 | リンゴの重さ、香り、味などの感覚情報はなし | 悲しみの感情、倫理的ジレンマの葛藤などは理解できない |
| 課題 | 人間のように現実世界を理解し、経験に基づいた判断をすることができない | 熟したリンゴの重さや香りを答えるのが難しい | 実際に悲しみを感じた時の心の痛みや苦しさ、倫理的なジレンマに直面した際の葛藤などを理解することが難しい |
限界:データの質への依存

言語モデルは、膨大な量の文章データから学習します。そのため、学習に用いるデータの質が、モデルの性能を大きく左右します。質の低いデータで学習すると、モデルは間違った知識や偏った考え方を身につけてしまう可能性があります。これは、まるで子どもに間違ったことを教え込むようなものです。子どもは教えられたことをそのまま信じてしまうように、言語モデルも質の低いデータから学習した内容を正しいものとして扱ってしまいます。
データの質の問題は多岐に渡ります。例えば、学習データに誤情報が含まれていると、モデルも誤った情報を生成するようになります。また、特定の集団に対する偏見が含まれていると、モデルもその偏見を反映した出力を生成する可能性があります。例えば、過去のデータから「医者は男性である」という偏った学習をした場合、モデルは「医者」と入力されると、男性を連想するような文章を生成してしまうかもしれません。
高品質な言語モデルを開発するためには、質の高い学習データを用意することが不可欠です。そのためには、データの収集、選別、整理といった様々な作業が必要です。まず、信頼できる情報源からデータを収集し、その中からモデルの学習に適したデータを選別します。次に、データに含まれる誤りや不整合を修正する「データクリーニング」と呼ばれる作業を行います。さらに、データに偏りがないかを確認し、必要に応じて修正を加えます。これらの作業は、まるで料理人が食材を丁寧に下ごしらえするように、質の高いモデルを作るための重要な土台となります。
データの質を高める努力は、言語モデルの信頼性を高めることに繋がります。信頼できる情報を提供するモデルは、様々な場面で役立ちます。例えば、正確な情報に基づいた検索結果を提供したり、誤りのない文章を作成したりすることができます。質の高いデータは、モデルの性能向上だけでなく、社会全体の利益にも繋がるのです。そのため、言語モデルの開発においては、データの質向上に常に気を配る必要があります。
| 問題点 | 具体例 | 対策 | 効果 |
|---|---|---|---|
| 質の低い学習データ | 誤情報、偏見(例:医者は男性) | 信頼できる情報源からのデータ収集、データクリーニング、偏りの修正 | モデルの信頼性向上、正確な情報提供、誤りのない文章作成 |