word2vec:言葉の意味を捉える

AIを知りたい
先生、「word2vec」ってどういう意味ですか?難しそうでよくわからないです。

AIエンジニア
そうだね、少し難しいかもしれないね。「word2vec」は、コンピュータに言葉を理解させるための技術の一つだよ。言葉の意味を、その言葉の周りの言葉から推測するんだ。
AIを知りたい
周りの言葉から推測する、ってどういうことですか?
AIエンジニア
例えば、「王様」という言葉の近くには、「お城」や「家来」といった言葉がよく出てくるよね。そうするとコンピュータは、「王様」は「お城」や「家来」と関係が深い言葉だと学習する。これがword2vecの考え方だよ。
word2vecとは。
人工知能で使われる言葉、「ワードツーベック」について説明します。ワードツーベックは、「ある言葉の意味は、その言葉の周りの言葉によって決まる」という考え方を、人の脳の仕組みをまねたコンピューターの技術で実現した方法です。
言葉のベクトル表現

言葉の意味を数字の列で表す方法、これを言葉のベクトル表現と言います。言葉一つ一つに、まるで座標のように複数の数字を組み合わせたベクトルを割り当てるのです。このベクトルは、言葉の意味を反映するように作られています。
例えば、「王様」と「女王様」を考えてみましょう。どちらも国のトップであるという意味で共通点があります。言葉のベクトル表現では、この共通点がベクトルの近さに反映されます。「王様」と「女王様」に対応するベクトルは、互いに近い場所に位置するのです。これは、まるで地図上で近い場所にある都市が似たような文化や気候を持つように、ベクトル空間上で近い言葉は似た意味を持つことを示しています。
一方で、「王様」と「机」はどうでしょうか。王様は人間であり、統治を行う存在です。机は物であり、物を置くために使われます。この二つは全く異なる意味を持ちます。そのため、言葉のベクトル表現では、「王様」と「机」のベクトルは互いに遠く離れた場所に位置します。まるで地図上で遠く離れた都市が全く異なる文化や気候を持つように、ベクトル空間上で遠い言葉は異なる意味を持つことを示すのです。
このように、言葉の意味をベクトルとして数字で表すことで、計算機は言葉の意味を理解し、処理できるようになります。この技術は「word2vec」と呼ばれ、言葉の意味を計算機に理解させるための画期的な方法として注目されています。これにより、文章の自動分類や機械翻訳など、様々な場面で言葉の処理が大きく進歩しました。まるで言葉に隠された意味を計算機が読み解く魔法のような技術と言えるでしょう。
| 言葉1 | 言葉2 | 意味の近さ | ベクトルの距離 |
|---|---|---|---|
| 王様 | 女王様 | 近い | 近い |
| 王様 | 机 | 遠い | 遠い |
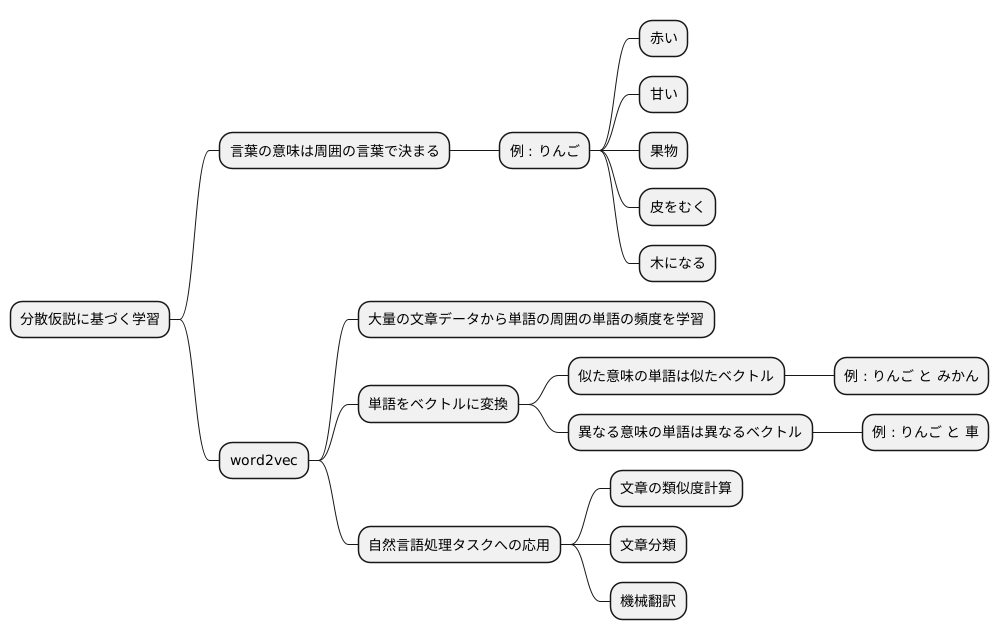
分散仮説に基づく学習

言葉の意味をコンピュータに理解させることは、自然言語処理における大きな課題です。そのための有効な手法の一つとして、分散仮説に基づく学習が挙げられます。これは、「ある言葉の意味は、その言葉の周囲に現れる言葉によって決まる」という考え方です。例えば、「りんご」という言葉を考えてみましょう。りんごは、「赤い」「甘い」「果物」「皮をむく」「木になる」といった言葉と一緒に使われることが多いでしょう。これらの言葉は、りんごの色、味、種類、食べ方、成り方など、りんごの様々な側面を表現しています。このように、周囲の言葉を観察することで、りんごという言葉が持つ意味を推測することができるのです。
分散仮説に基づく学習の代表的な手法として、word2vecが挙げられます。word2vecは、大量の文章データから、各単語の周囲に現れる単語の頻度を学習します。そして、この頻度情報に基づいて、各単語をベクトルと呼ばれる数値の列に変換します。このベクトルは、単語の意味を数値で表現したもので、似た意味を持つ単語は似たベクトルを持つように設計されています。例えば、「りんご」と「みかん」はどちらも果物なので、これらの単語のベクトルは似ているでしょう。一方、「りんご」と「車」は全く異なる意味を持つので、ベクトルも大きく異なるでしょう。
word2vecは、このようにして得られた単語ベクトルを用いることで、様々な自然言語処理タスクを効率的に行うことができます。例えば、文章の類似度計算や、文章分類、機械翻訳などに応用されています。word2vecの登場により、コンピュータは人間の言語理解にさらに近づいたと言えるでしょう。
二つの学習モデル

単語の意味をベクトル表現に変換する手法として知られるワードツーベックには、大きく分けて二つの学習の型があります。一つはシーボウ(連続単語袋)と呼ばれる型で、周りの単語から真ん中の単語を予測するように学習します。例えば、「私は猫が好きです」という文章があれば、「私」「猫」「好き」という言葉から「は」という言葉を予測する、といった具合です。
もう一つはスキップグラムと呼ばれる型で、真ん中の単語から周りの単語を予測するように学習します。同じく「私は猫が好きです」という文章を例に挙げると、「は」という言葉から「私」「猫」「好き」という言葉群を予測する、といった具合です。どちらの型も、人間の脳の仕組みを模倣した数理モデルを用いて学習を行います。
シーボウは、計算の手間が少なく済むという利点があります。そのため、大規模なデータを用いた学習に適しています。また、よく使われる単語のベクトル表現を正確に捉えることが得意です。一方で、スキップグラムは、あまり使われない単語のベクトル表現を捉えることが得意です。これは、少ない情報からでも単語の意味を推測する必要があるため、結果として低頻出語の表現学習に繋がります。
このように、二つの学習の型にはそれぞれ異なる特徴があります。扱う仕事の内容やデータの特性に合わせて、適切な型を選ぶことが重要です。例えば、よく使われる単語のベクトル表現が重要な仕事であればシーボウを、そうでなければスキップグラムを選ぶ、といった具合です。最適な型を選ぶことで、より精度の高いベクトル表現を得ることができ、様々な自然言語処理の仕事に役立てることができます。
| 学習の型 | 説明 | 利点 | 得意とする単語 |
|---|---|---|---|
| CBOW (シーボウ) (連続単語袋) |
周囲の単語から真ん中の単語を予測 | 計算の手間が少ない 大規模データ学習に適している |
よく使われる単語 |
| Skip-gram (スキップグラム) | 真ん中の単語から周囲の単語を予測 | 少ない情報から単語の意味を推測 | あまり使われない単語 |
類似度の計算

ことばどうしの意味の近さを計算するには、ワードツーベックという技術で作られたことばのベクトルを使うことができます。このベクトルは、ことばの意味を数値で表したものです。意味の近さを測るには、一般的にコサイン類似度という方法が使われます。これは、二つのベクトルが作る角度の余弦(コサイン)を計算することで求めます。
コサイン類似度の値は、-1から1までの範囲になります。1に近いほど、二つのことばの意味は近く、似ていることを示します。逆に、-1に近いほど、二つのことばの意味は遠く、似ていないことを示します。例えば、「王様」と「女王様」という二つのことばを考えてみましょう。これらのことばは、どちらも君主を指すことばであり、意味が近いことから、高いコサイン類似度を示します。つまり、1に近い値になります。一方、「王様」と「机」という二つのことばを考えてみましょう。これらのことばは、意味が全く異なるため、低いコサイン類似度を示します。つまり、-1に近い値になります。
このようにして計算されたことばどうしの意味の近さは、様々な場面で役立ちます。例えば、類義語を検索する際に、入力されたことばに近い意味を持つことばを見つけ出すことができます。また、文章を分類する際にも、文章に含まれることばの意味に基づいて、どのカテゴリに属するかを判断することができます。他にも、文章全体の類似度を計算することで、似ている文章を見つけることも可能です。このように、ワードツーベックとコサイン類似度を組み合わせることで、ことばの意味を捉え、様々な自然言語処理の作業に役立てることができます。
| 項目 | 説明 |
|---|---|
| ワードツーベック | 単語をベクトルで表現する技術。ベクトルは単語の意味を数値で表す。 |
| コサイン類似度 | 単語ベクトル間の類似度を計算する方法。値の範囲は-1から1。 |
| コサイン類似度の値の意味 | 1に近い: 類似度が高い、-1に近い: 類似度が低い |
| 例:「王様」と「女王様」 | 意味が近いため、コサイン類似度は1に近い値。 |
| 例:「王様」と「机」 | 意味が遠いため、コサイン類似度は-1に近い値。 |
| 応用例 | 類義語検索、文章分類、類似文章検索など |
応用例と発展

言葉の意味をベクトルで表す技術であるワードツーベックは、様々な分野で活用され、私たちの生活を便利にしています。具体的には、異なる言語間で文章を置き換える機械翻訳や、長い文章を短くまとめる文章要約、投げかけられた質問に適切に答える質問応答システム、書き言葉から書き手の感情を読み取る感情分析などで、既に実用化が進んでいます。
例えば、機械翻訳では、ワードツーベックによって単語の意味の繋がりを捉えることで、より自然で正確な翻訳が可能になります。また、文章要約では、文章中の重要な単語を特定し、それらに基づいて要約を作成することで、情報の把握を容易にします。質問応答システムでは、質問の意味を理解し、膨大なデータの中から適切な回答を抽出する際に、ワードツーベックが重要な役割を果たします。感情分析では、書き言葉に含まれる感情表現を捉え、書き手の感情や意図を推測するのに役立ちます。
さらに、ワードツーベックを発展させた技術も登場しています。例えば、文章や段落全体をベクトル化するドックツーベックは、文章の意味をより深く理解することを可能にし、文章の分類や検索、文章間の類似度判定など、様々な応用が期待されています。このように、ワードツーベックは自然言語処理の分野に革新をもたらし、人工知能による言葉の理解を飛躍的に向上させています。今後も、様々な分野での更なる応用と発展が期待され、私たちの生活をより豊かにする重要な技術と言えるでしょう。
| 技術 | 説明 | 活用例 |
|---|---|---|
| ワードツーベック | 言葉をベクトルで表す技術 | 機械翻訳、文章要約、質問応答システム、感情分析 |
| 機械翻訳 | 異なる言語間で文章を置き換える | より自然で正確な翻訳 |
| 文章要約 | 長い文章を短くまとめる | 情報の把握を容易にする |
| 質問応答システム | 投げかけられた質問に適切に答える | 質問の意味を理解し、適切な回答を抽出 |
| 感情分析 | 書き言葉から書き手の感情を読み取る | 書き手の感情や意図を推測 |
| ドックツーベック | 文章や段落全体をベクトル化するワードツーベックの発展技術 | 文章の分類、検索、文章間の類似度判定 |
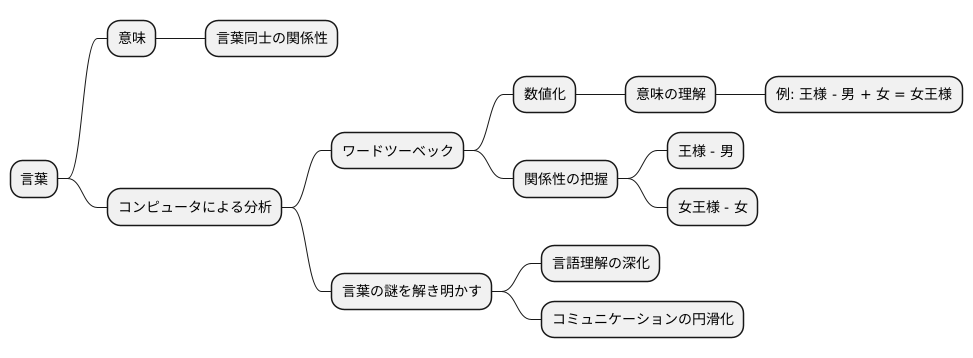
言葉の理解を深める

言葉というものは、単なる記号の羅列ではなく、それぞれが持つ意味や、他の言葉との関係性によって成り立っています。言葉の意味を深く理解することは、私たち人間が互いを理解し、社会を築いていく上で非常に大切なことです。そのために、近年ではコンピュータを用いて言葉の分析を行う研究が盛んに行われています。
「ワードツーベック」と呼ばれる技術は、言葉を数値の列に変換することで、コンピュータが言葉を扱えるようにする技術です。この技術は、言葉をただ数値化するだけでなく、言葉の意味をより深く理解するための道具としても役立ちます。例えば、「王様」という言葉から「男」という言葉を差し引き、「女」という言葉を足し合わせると、「女王様」という言葉に近い結果が得られます。これはまるで、コンピュータが言葉の意味を理解し、計算しているかのようです。
このような計算が可能になるのは、「ワードツーベック」が言葉の意味を適切に数値化し、言葉同士の関係性を捉えているからです。言葉は、それぞれが独立して存在しているのではなく、互いに関連し合いながら意味を成しています。「王様」と「男」、「女王様」と「女」のような関係性を、コンピュータが数値的に捉えることで、人間が言葉を使うときの意味の構造や、言葉の使われ方の特徴を明らかにすることができます。
「ワードツーベック」は、言葉の謎を解き明かすための強力な武器となる可能性を秘めています。この技術によって、私たちは言葉の奥深くに潜む意味や関係性をより深く理解し、言葉を通して世界をより豊かに捉えることができるようになるでしょう。今後の研究の進展によって、言葉の理解がさらに深まり、私たちのコミュニケーションがより円滑になることが期待されます。