勾配消失問題:深層学習の壁

AIを知りたい
先生、「勾配消失問題」って、どういう意味ですか?難しそうでよくわからないです。

AIエンジニア
そうですね、少し難しいですね。簡単に言うと、たくさんの層が重なった複雑な人工知能を学習させるときに、うまく学習が進まなくなる問題のことです。ちょうど、高い山の頂上を目指して進むのに、進むほど坂がなくなって平らになり、どこに進めば頂上なのかわからなくなるようなイメージです。人工知能も、進むべき方向がわからなくなるのです。
AIを知りたい
なるほど。坂が平らになるというのは、どういうことですか?
AIエンジニア
人工知能の学習では、出力と正解の差を計算し、その差を小さくするように学習を進めます。この差を小さくするための道筋を「勾配」と言います。層が多いと、この勾配の計算を何度も繰り返すうちに、勾配の値がどんどん小さくなって、ほぼゼロになってしまう。だから「勾配消失問題」と呼ばれるのです。坂が平らになるというのは、この勾配がゼロに近づくことを意味します。すると、人工知能はどちらに進めば正解に近づけるのかわからなくなり、学習が進まなくなるのです。
勾配消失問題とは。
人工知能に関わる言葉で「勾配消失問題」というものがあります。これは、深い階層を持つニューラルネットワークを学習させる際に、うまく学習が進まなくなる問題です。具体的には、学習の過程で、出力側から入力側に向かって、層を遡りながら調整量を計算していくのですが、この調整量がほぼゼロになってしまうために起こります。層が深くなるにつれて、この調整量が小さくなっていく活性化関数を使うと、この問題が起こりやすくなります。例えば、シグモイド関数のように、調整量の最大値が0.25といった小さな値になる活性化関数が、この問題の代表例です。
問題の概要

深層学習という技術は、人間のように物事を学ぶことができる計算機の仕組みですが、幾重にも積み重なった層の奥深くまで学習を進めるのが難しいという壁に直面しています。これが勾配消失問題と呼ばれるものです。
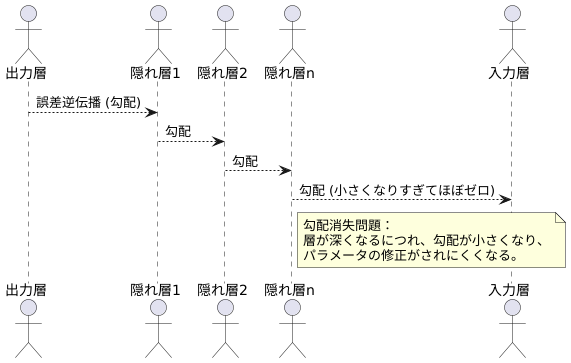
層を何層にも重ねた構造を持つニューラルネットワークは、丁度、高層ビルのようなものです。学習を進めるということは、このビルの屋上から地上に向かって情報を伝えるようなものです。この情報を伝える方法は、誤差逆伝播法と呼ばれ、出力層から入力層に向けて、どのくらい修正すべきかという指示を伝えていきます。
しかし、層が深くなるにつれて、この指示はだんだん弱くなってしまいます。高層ビルから地上にメッセージを伝えることを想像してみてください。階を降りるごとに、メッセージは伝言ゲームのように変化し、最終的には最初のメッセージがほとんど分からなくなってしまいます。これが勾配消失問題で起こっていることです。
指示を伝える際に使われる数値は勾配と呼ばれ、パラメータ(重み)を修正する量を示す重要な値です。層が深くなると、この勾配の値が小さくなりすぎて、ほぼゼロに近づいてしまいます。ゼロに近い値では、パラメータの修正はほとんど行われず、学習は停滞してしまいます。つまり、モデルは適切な重みを学習することができず、本来期待される性能を発揮できなくなってしまうのです。
勾配消失問題は、特に層の数が多くなったニューラルネットワークで顕著に発生します。これは、勾配の計算が何度も繰り返されるため、勾配の値が指数関数的に小さくなる可能性があるからです。丁度、長い鎖の端を少し引っ張っても、反対側の端はほとんど動かないのと同じです。この問題に対処するために、様々な工夫が凝らされていますが、それはまた別のお話です。
活性化関数との関係

神経回路網の学習において、勾配消失問題は深刻な課題です。この問題の発生には、活性化関数の選び方が大きく関わってきます。活性化関数は、人工神経細胞の出力を整える役割を持ち、入力された情報を加工して次の層に伝えます。この活性化関数には様々な種類があり、それぞれ異なる特徴を持っています。
活性化関数の多くは、非線形変換を行うことで、複雑な模様を学習することを可能にしています。しかし、活性化関数の中には、勾配の値が小さくなりやすいものがあります。勾配とは、誤差を減らすための指標となる数値であり、この値が小さすぎると学習がうまく進みません。例えば、シグモイド関数と呼ばれる活性化関数は、出力値を0から1の間に滑らかに変換する際に用いられます。しかし、この関数は勾配の値が比較的小さく、最大でも0.25にしかなりません。
誤差逆伝播法は、出力層で得られた誤差を各層に逆方向に伝播させ、各層の重みを調整することで学習を進める手法です。この手法では、勾配の値を各層で掛け合わせるため、勾配が小さいと層を深くするにつれて誤差が消失してしまうのです。特に、何層にも積み重なった深い神経回路網では、この影響が顕著に現れ、勾配消失問題の主な原因となります。シグモイド関数の他に、双曲線正接関数も勾配消失問題を引き起こしやすい活性化関数として知られています。これらの活性化関数を用いる際には、勾配消失問題に注意する必要があります。
| 活性化関数 | 特徴 | 勾配消失問題 |
|---|---|---|
| シグモイド関数 | 出力値を0から1の間に滑らかに変換 | 発生しやすい (最大勾配0.25) |
| 双曲線正接関数 | 発生しやすい | |
| (その他) | 非線形変換を行い、複雑な模様を学習可能 | 活性化関数によっては発生 |
対策と解決策

深層学習の過程で、勾配消失問題は精度向上を阻む大きな壁となります。この問題に対処するには、いくつかの有効な対策が存在します。まず活性化関数の選択が挙げられます。古くから用いられてきたシグモイド関数では、層が深くなるにつれて勾配が非常に小さくなってしまう、いわゆる勾配消失問題が発生しやすい性質があります。そこで、近年では正規化線形関数、ReLUが広く採用されています。この関数は、入力が正の値ならばそのまま出力し、負の値ならば零を出力するという単純な仕組みです。この単純さ故に計算の負担も軽く、勾配消失問題の抑制にも高い効果を発揮します。
次に、重みの初期値の設定も重要な要素です。適切な初期値を設定しなければ、学習の開始直後から勾配消失問題に陥る可能性があります。適切な初期値を選ぶことで、学習をスムーズに進めることができます。様々な初期化方法が提案されていますが、適切な方法はモデルの構造やデータの性質によって異なります。
さらに、バッチ正規化と呼ばれる手法も効果的です。これは、各層への入力を正規化する手法で、学習の進行を安定させ、勾配消失問題の発生を抑える働きがあります。入力値の分布を調整することで、学習がより効率的に進みます。
これらの対策は単独で用いるだけでなく、組み合わせて使うことで、より大きな効果を発揮します。それぞれの対策の効果を理解し、モデルやデータの特性に合わせて適切に組み合わせることで、勾配消失問題の影響を最小限に抑え、精度の高い深層学習モデルを構築することが可能になります。
| 対策 | 説明 | 利点 |
|---|---|---|
| 活性化関数の変更 (ReLU) | シグモイド関数に代わり、入力が正ならそのまま、負なら0を出力する関数 | 計算負荷が軽く、勾配消失問題を抑制 |
| 重みの初期値の設定 | 適切な初期値を選択 | 学習初期からの勾配消失問題を回避、学習をスムーズ化 |
| バッチ正規化 | 各層への入力を正規化 | 学習の安定化、勾配消失問題の抑制、学習効率向上 |
影響を受けるモデル

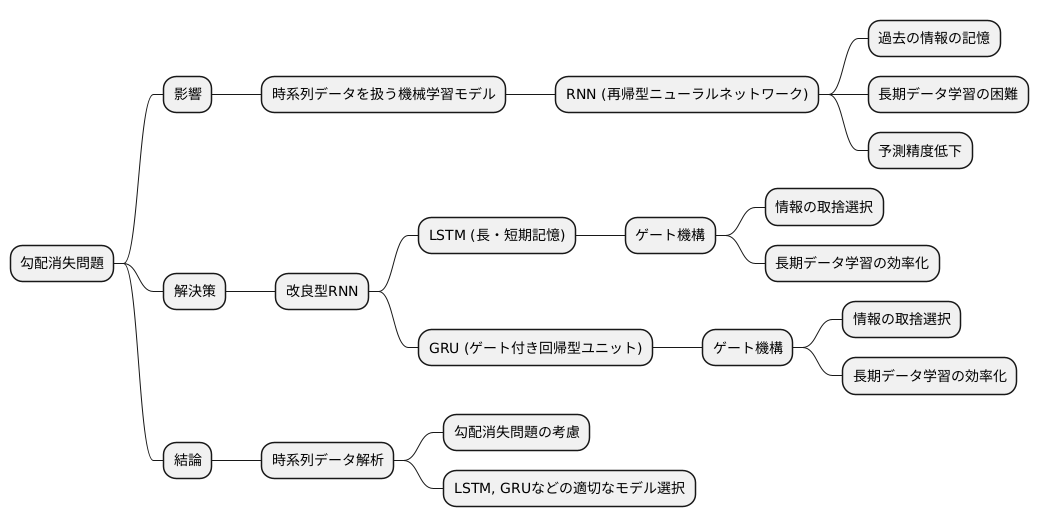
勾配消失問題は、時間の流れに沿ったデータを扱う様々な機械学習モデルに大きな影響を与えます。特に、過去の情報を記憶しながら学習を進める再帰型ニューラルネットワーク(RNN)は、この問題の影響を受けやすいです。
RNNは、過去の情報を現在の状態に反映させることで、データの繋がりを学習します。しかし、学習するデータの時間範囲が長い場合、過去の情報の影響が薄れていく現象、つまり勾配消失問題が発生します。これは、鎖の反応のように、過去の情報が現在の状態に伝わる際に、その影響が徐々に小さくなっていくイメージです。結果として、RNNは長期的なデータの繋がりを捉えることが難しくなり、予測精度が低下します。
この問題に対処するために、改良型のRNNが開発されています。長・短期記憶(LSTM)やゲート付き回帰型ユニット(GRU)といったモデルは、情報の取捨選択を行う仕組みを備えています。これらのモデルは「ゲート」と呼ばれる機構を用いて、重要な情報を保持し、不要な情報を捨てることで、長期的なデータの繋がりを効果的に学習できます。ゲートは、水門のように、情報の伝達量を調整する役割を果たします。
このように、LSTMやGRUは、勾配消失問題の影響を受けにくい構造を持つため、音声認識や自然言語処理など、時系列データを扱う様々な分野で広く利用されています。そのため、時系列データの解析を行う際には、勾配消失問題を考慮し、LSTMやGRUなどの適切なモデルを選ぶことが非常に重要です。
今後の展望

深層学習という技術は、まるで生き物のように絶えず進化を続けています。中でも、勾配消失問題への対策研究は、この分野の進歩を大きく左右する重要な課題です。
この問題は、幾重にも積み重なった層を持つ深層学習モデルの奥深くで、学習の指針となる情報が薄れて消えてしまう現象です。例えるなら、高い山の頂上から麓へ情報を伝える際に、途中でメッセージが失われてしまうようなものです。このため、モデル全体がうまく学習できず、本来の力を発揮できません。
様々な角度からの挑戦が、この問題解決に向けて行われています。活性化関数と呼ばれる、学習の効率を高めるための工夫もその一つです。より良い活性化関数を開発することで、情報が消えずに伝わるように工夫しています。また、学習の進め方そのものを見直す研究も盛んです。山の頂上から麓まで、より確実に情報を伝えるための、新しい伝達方法を模索していると言えるでしょう。さらに、モデルの構造そのものを工夫することで、情報伝達の効率を高める試みも進んでいます。山の地形を変えることで、よりスムーズに情報が流れるようにするイメージです。
計算機の性能向上も、この問題解決に貢献しています。より高速で強力な計算機は、複雑な計算を素早くこなし、これまで不可能だった規模の大きなモデルの学習を可能にします。
これらの研究が進むにつれて、勾配消失問題のより効果的な解決策が生まれることが期待されます。深層学習は、画像認識や自然言語処理など、様々な分野で応用されていますが、勾配消失問題への対策が進むことで、さらに多くの分野で活用されるようになるでしょう。深層学習の秘めたる可能性は計り知れず、今後の発展に大きな期待が寄せられています。勾配消失問題への深い理解は、深層学習モデルの設計と最適化において欠かせない要素であり、今後の深層学習の進歩に大きく貢献していくと考えられます。