深層学習のデータ量の重要性

AIを知りたい
先生、「バーニーおじさんのルール」って、ディープラーニングの学習には、モデルのパラメータ数の10倍以上のデータ量が必要だっていう経験則ですよね?でも、そんなに大量のデータを集めるのは大変じゃないですか?

AIエンジニア
そうだね。大量のデータを集めるのは大変だし、質の高いデータでないと、かえって学習の精度が悪くなることもあるんだ。だから、データの量だけでなく質も重要なんだよ。
AIを知りたい
質の高いデータって、具体的にはどんなデータなんですか?
AIエンジニア
例えば、画像認識のAIなら、ノイズやぼやけが少ない鮮明な画像データ、音声認識AIなら、クリアな音声データなどだね。目的に合わせて、適切に処理されたデータが必要になるんだよ。
ディープラーニングのデータ量とは。
人工知能の学習方法の一つである「深層学習」では、学習に使うデータの量が大切です。一般的に、学習をうまく行うには、深層学習のモデルの複雑さを表す「パラメータの数」の10倍以上のデータが必要だと言われています。これは「バーニーおじさんのルール」と呼ばれる経験則です。インターネットが普及して、たくさんのデータ(ビッグデータ)が使えるようになったことで、人工知能の進歩は大きく加速しました。
大量データ時代の幕開け

近頃は、技術の進歩が目覚ましく、特に情報のやり取りを行う網の広まりによって、世界中で計り知れない量の資料が集められ、積み重ねられています。このとてつもない量の資料は「大量データ」と呼ばれ、様々な場所で役立てられています。特に、人の知恵を模倣した機械の分野では、この大量データが、これまでとは全く異なる大きな変化をもたらしました。かつては、人の知恵を模倣した機械に物事を学習させるには、使える資料が限られていました。しかし、大量データの登場によって状況は一変しました。人の知恵を模倣した機械は、より複雑な模様や繋がりを学ぶことができるようになり、驚くほどの性能向上を成し遂げました。
具体例を挙げると、医療の分野では、大量データを用いて病気を早期に発見するための研究が進んでいます。膨大な数の医療記録や画像データを分析することで、従来の方法では見つけるのが難しかった病気の兆候を捉えることができる可能性があります。また、商業の分野では、顧客の購買履歴や行動パターンを分析することで、より効果的な販売戦略を立てることができます。それぞれの顧客に合わせた商品を提案したり、顧客が求めている情報を的確に提供することで、顧客満足度を高めることができます。さらに、交通の分野では、渋滞の解消や事故の防止に役立てられています。道路上の車の流れや交通量をリアルタイムで分析することで、渋滞が発生しやすい場所を予測し、適切な交通整理を行うことができます。また、過去の事故データを分析することで、事故の発生しやすい場所や状況を特定し、事故防止対策に役立てることができます。
このように、大量データは様々な分野で革新的な変化をもたらしており、人の知恵を模倣した機械の成長を支える重要な土台となっています。今後、ますます大量データの活用が進むことで、私たちの生活はさらに豊かで便利なものになっていくでしょう。大量データの時代はまさに幕を開けたばかりであり、今後どのような発展を遂げるのか、期待が高まります。
| 分野 | 大量データの活用例 | 期待される効果 |
|---|---|---|
| 医療 | 医療記録や画像データの分析 | 病気の早期発見 |
| 商業 | 顧客の購買履歴や行動パターンの分析 | 効果的な販売戦略の立案、顧客満足度の向上 |
| 交通 | 道路上の車の流れや交通量、過去の事故データの分析 | 渋滞の解消、事故の防止 |
データと学習効率の関係

人工知能、とりわけ深層学習という手法において、学習に用いる情報の量は学習の効率に直結する大変重要な要素です。十分な量の情報を用いて学習を行うことで、人工知能はより正確で、様々な状況に対応できる能力の高いモデルを構築することができます。これは、人間が多くの経験を積むことで、より正確な判断力と様々な状況に対応できる能力を身につけることに似ています。
反対に、学習に用いる情報の量が不足している場合、人工知能は学習に用いた情報の特徴に過剰に適応してしまい、未知の情報に対してはうまく機能しなくなる「過学習」と呼ばれる現象が発生しやすくなります。これは、人間が限られた経験だけで判断してしまうと、それ以外の状況に対応できなくなることに似ています。過学習は人工知能の性能を低下させる大きな要因となるため、適切な量の情報を確保することは極めて重要です。ちょうど料理人が様々な食材や調理法を学ぶことで、より美味しい料理を作ることができるように、人工知能も多くの情報を学習することで、より高い性能を発揮できるようになります。
さらに、情報の量だけでなく質も重要です。学習に用いる情報に偏りがあると、人工知能はその偏りを反映したモデルを構築してしまいます。例えば、特定の地域の情報だけで学習させた場合、その地域特有の特徴に過剰に適応し、他の地域の情報にはうまく対応できない可能性があります。そのため、質の高い、偏りのない情報を十分な量確保することが、人工知能の性能向上には不可欠です。これは、人間が様々な人と関わることで、より広い視野を持つことができるようになることに似ています。人工知能も多様な情報を学習することで、より汎用性の高い能力を身につけることができるのです。
| 要素 | 詳細 | 人間へのアナロジー |
|---|---|---|
| 情報の量 | 十分な量の学習データは、正確で様々な状況に対応できる能力の高いAIモデル構築に不可欠。データ不足は過学習(学習データに過剰適応し未知データにうまく対応できない現象)を引き起こす。 | 多くの経験を積むことで、より正確な判断力と様々な状況に対応できる能力を身につける。限られた経験での判断は、それ以外の状況に対応できない。 |
| 情報の質 | 情報の偏りは、AIモデルの偏りにつながる。多様な情報による学習が汎用性の高いAIモデル構築には重要。 | 様々な人と関わることで、より広い視野を持つことができる。 |
経験則:バーニーおじさんのルール

近年の技術革新により、人工知能、特に深層学習は目覚ましい発展を遂げ、様々な分野で活用されています。しかし、高性能な深層学習モデルを構築するには、膨大な量のデータが必要となることがしばしば課題となります。そこで、データ量を見積もるための経験則として、「バーニーおじさんのルール」というものが広く知られています。
このルールは、深層学習モデルのパラメータ数の10倍以上のデータ量を学習に用いることが理想的であると提唱しています。パラメータとは、人工知能モデルが学習過程で調整する変数のことです。これらの変数は、モデルがデータからパターンや特徴を学習するために用いられます。モデルの複雑さは、パラメータの数に比例します。つまり、複雑なモデルは多くのパラメータを持ち、表現力が高い反面、過学習と呼ばれる現象に陥りやすい傾向があります。過学習とは、学習データに過剰に適合しすぎてしまい、未知のデータに対する予測性能が低下する状態を指します。
バーニーおじさんのルールは、この過学習を防ぎ、モデルが未知のデータに対しても高い予測性能を発揮できるようにするための指針となります。十分なデータ量を確保することで、モデルは学習データの特殊なパターンだけでなく、より一般的なパターンを学習できます。これにより、未知のデータに対しても安定した予測が可能となります。
具体的な例を挙げると、画像認識のタスクで100万個のパラメータを持つモデルを学習させる場合、バーニーおじさんのルールに従うと、1000万枚以上の画像データが必要となります。これは膨大な量に思えるかもしれませんが、複雑なモデルで高い精度を達成するには、それ相応のデータが必要となるのです。
ただし、バーニーおじさんのルールはあくまで経験則であり、全ての状況に当てはまるわけではありません。データの質やモデルの構造など、他の要素も学習結果に大きく影響します。したがって、このルールを一つの目安として活用しつつ、個々の状況に応じて適切なデータ量を検討することが重要です。
| 項目 | 説明 |
|---|---|
| バーニーおじさんのルール | 深層学習モデルのパラメータ数の10倍以上のデータ量を学習に用いることが理想的であるという経験則。 |
| パラメータ | 人工知能モデルが学習過程で調整する変数。モデルの複雑さを示す。 |
| 過学習 | 学習データに過剰に適合しすぎてしまい、未知のデータに対する予測性能が低下する状態。 |
| データ量 | モデルの学習に必要なデータ量。バーニーおじさんのルールではパラメータ数の10倍以上が推奨される。 |
| 目的 | 過学習を防ぎ、未知のデータに対しても高い予測性能を発揮するモデルを構築するため。 |
| 例 | 画像認識で100万パラメータのモデルの場合、1000万枚以上の画像データが必要。 |
| 注意点 | あくまで経験則であり、データの質やモデルの構造も学習結果に影響するため、状況に応じて適切なデータ量を検討する必要がある。 |
データ量の確保と工夫

機械学習を行う上で、学習に用いる情報の量は結果の良し悪しを大きく左右すると言えます。十分な量の情報を集めることができれば、より正確で信頼性の高い結果を得られる可能性が高まります。しかしながら、現実は常に十分な情報量を確保できるとは限りません。そこで、限られた情報からいかに効果的に学習させるか、様々な工夫が日々研究されています。
情報を増やすための方法の一つとして、「情報拡張」と呼ばれる技術が挙げられます。これは、元々ある情報を加工し、実際には存在しないけれども学習に使える似た情報を人工的に作り出す手法です。例えば、写真の情報を扱う場合、写真を回転させたり、左右反転させたり、明るさを調整したりすることで、元の写真とは少し違う新しい写真を作り出せます。このようにして、少ない元データから多くのバリエーションを生み出し、あたかも大量の情報を持っているかのように学習させることができます。
写真以外にも、音声や文章など様々な情報に対して、それぞれに合った加工方法を用いることで情報拡張は行われます。音声であれば、音の高さを少し変えたり、ノイズを混ぜたり、再生速度を調整したりすることで新しい音声データを作り出せます。文章であれば、同義語に置き換えたり、語順を入れ替えたりすることで、似た意味を持つ別の文章を生成できます。
また、情報拡張以外にも、複数の情報のかたまりを組み合わせて学習に用いるといった方法も有効です。それぞれのかたまりに含まれる情報の量は少なくても、組み合わせることで全体としての情報量は増え、学習の精度向上に繋がることが期待できます。このように、限られた情報から最大限の効果を引き出すための様々な工夫が凝らされ、機械学習の技術は進歩し続けています。
| 課題 | 解決策 | 具体例 |
|---|---|---|
| 機械学習には大量の情報が必要だが、現実には十分な情報量を確保できない場合がある | 情報拡張(少ない元データから人工的に似た情報を生成) | – 写真:回転、左右反転、明るさ調整 – 音声:音の高さを変更、ノイズ追加、再生速度調整 – 文章:同義語置換、語順変更 |
| 同上 | 複数の情報のかたまりを組み合わせて学習 | それぞれのかたまりに含まれる情報の量は少なくても、組み合わせることで全体としての情報量は増え、学習の精度向上に繋がる |
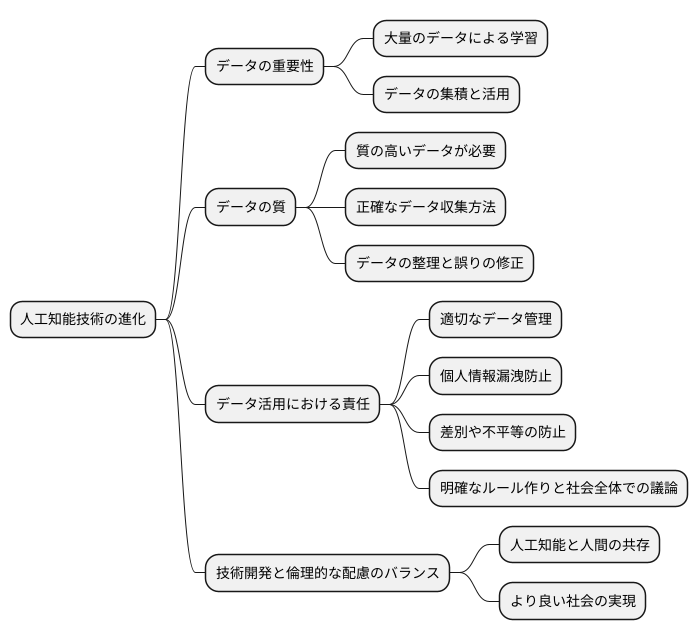
データの質の重要性

人工知能の学習において、データは欠かせない要素です。そして、そのデータの量だけでなく、質にも注意を払う必要があります。なぜなら、質の低いデータを使って人工知能を学習させると、期待通りの成果が得られないどころか、間違った方向に学習を進めてしまう可能性があるからです。
例えば、人工知能に画像から猫を認識させる学習をさせるとします。もし、学習データの中に犬の画像が猫として誤ってラベル付けされているデータが混ざっていたらどうなるでしょうか。人工知能は、その誤った情報も一緒に学習してしまい、猫と犬を区別する能力が正しく育たなくなってしまうかもしれません。このように、学習データに含まれる間違いやノイズは、人工知能の学習を妨げる大きな要因となります。
質の高いデータを集めるためには、まずデータの収集段階から注意深く行う必要があります。正確な測定機器を使用したり、複数人で確認作業を行うなど、データの正確性を高めるための工夫が必要です。また、すでに収集済みのデータを使う場合でも、内容に誤りがないか、学習目的に合っているかなどを確認し、必要に応じて修正や加工を行う必要があります。
さらに、人工知能の学習目的も重要な要素です。例えば、猫の種類を判別させる人工知能を作りたい場合、様々な種類の猫の画像データを集める必要があります。しかし、もし学習データに特定の種類の猫の画像ばかりが含まれていたら、他の種類の猫を正しく認識できない可能性があります。つまり、学習目的に合った適切なデータを集めることが重要なのです。
このように、質の高いデータは、人工知能の学習効率を高め、より正確で信頼性の高い結果を得るために不可欠です。人工知能の開発においては、データの量だけでなく、質にも十分に配慮する必要があることを忘れてはなりません。
今後の展望と課題

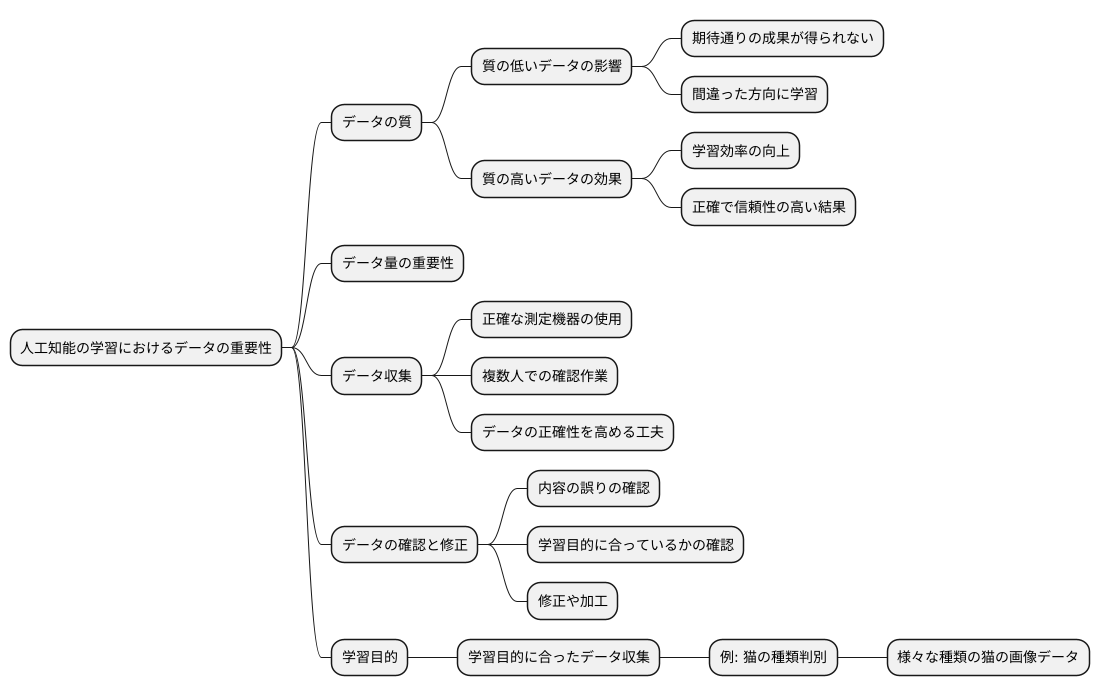
人工知能技術は、まるで生き物のように日々進化を続けています。 この進化を支えているのが、大量のデータです。人工知能は、データから知識やパターンを学び、様々な作業をこなせるようになります。そのため、今後、より高性能な人工知能を実現するためには、データの集積と活用がますます重要になってきます。
膨大なデータを扱うようになると、データの質にも注意を払う必要があります。いくらデータが多くても、質が悪ければ、人工知能の学習効果は上がりません。質の高いデータを集めるためには、正確なデータ収集方法を確立し、データの整理や誤りの修正といった地道な作業が必要です。データの量と質、この両輪をうまく回していくことが、優れた人工知能を生み出す鍵となります。
それと同時に、データ活用には責任が伴います。集めたデータを適切に管理し、個人の情報漏洩などを防ぐ必要があります。また、人工知能が差別的な判断を下したり、社会的な不平等を助長したりする可能性も考慮しなければなりません。こうした倫理的な問題に適切に対処するためには、明確なルール作りや社会全体での議論が必要です。
人工知能技術は、私たちの社会を大きく変える力を持っています。この力を最大限に活かし、より良い社会を築くためには、技術開発と倫理的な配慮のバランスを保つことが大切です。人工知能と人間が共存できる未来を目指し、技術開発と社会的な議論を進めていく必要があるでしょう。