
系列から系列への変換:Seq2Seqモデル

AIを知りたい
先生、『Seq2Seq』って一体どんなものなんですか?なんか難しそうでよくわからないです。

AIエンジニア
そうだね、少し難しいかもしれないね。『Seq2Seq』は、簡単に言うと、文章を読み込んで、別の文章を作る技術のことだよ。例えば、日本語の文章を読み込んで、それを英語の文章に変換するような時に使われるんだ。
AIを知りたい
へえー、すごいですね!でも、どうやって文章を読み込んで、別の文章を作れるんですか?
AIエンジニア
文章を単語のつながりとして捉えて、読み込んだ文章の意味を理解する部分と、理解した意味に基づいて新しい文章を作る部分の二つに分けて処理しているんだ。それぞれの部分を「エンコーダ」と「デコーダ」と呼ぶんだよ。エンコーダで文章の特徴を掴んで、デコーダでその特徴に基づいて新しい文章を生成する。だから、翻訳だけでなく、文章の要約や質疑応答などにも使えるんだよ。
Seq2Seqとは。
ある言葉について説明します。その言葉は「シーク・ツー・シーク」と読みます。これは、人工知能に関係する言葉です。この仕組みは、文章などの順番に並んだデータを扱うのが得意です。仕組みの中には、「エンコーダ」と「デコーダ」と呼ばれる二つの部分があります。どちらも、物事の変化を順々に記録していくのが得意な仕組みを使っています。まず「エンコーダ」が文章を読み込んで、文章の意味や内容を捉えます。次に「デコーダ」がその意味や内容をもとにして、目的に合った単語を並べて出力します。
時系列データとSeq2Seq

時間を追って変化していく性質を持つデータのことを、時系列データと言います。私たちの周りには様々な時系列データが存在します。例えば、毎日変動する株価や、刻々と変わる気温、聞こえてくる音声、そして私たちが日々使っている言葉なども、全て時系列データです。時系列データの特徴は、データ一つ一つに意味があるだけでなく、データの並び順、つまり時間の流れに沿った変化そのものにも重要な意味があるということです。そのため、普通のデータと同じように扱うことはできません。このような時系列データを扱うための強力な道具として、深層学習という分野で「系列から系列への変換」を可能にするモデルが登場しました。これは、入力と出力の両方が系列データであることを意味し、シーケンス・ツー・シーケンスモデル、略してSeq2Seqモデルと呼ばれています。
Seq2Seqモデルは、ある系列データを入力として受け取り、別の系列データを出力として生成することができます。これはまるで、入力系列を理解し、それを別の系列へと翻訳しているかのようです。Seq2Seqモデルが最も活用されている例として、機械翻訳が挙げられます。日本語の文章を入力すると、それを理解し、対応する英語の文章を出力するのです。他にも、文章の要約や、質問応答システムなど、様々な応用が考えられます。例えば、長い文章を入力すると、その要約を生成したり、質問を入力すると、適切な答えを生成したりといった具合です。Seq2Seqモデルは、入力系列を一度別の表現に変換し、それから出力系列を生成するという二段階の仕組みを持っています。この仕組みのおかげで、様々な長さの系列データを柔軟に扱うことができるのです。時系列データは、私たちの生活の様々な場面で見られる重要なデータであり、Seq2Seqモデルは、その可能性を大きく広げる技術と言えるでしょう。
| 項目 | 説明 |
|---|---|
| 時系列データ | 時間とともに変化するデータ。例:株価、気温、音声、言葉など。データの並び順(時間経過)が重要。 |
| Seq2Seqモデル | 系列データを入力として受け取り、別の系列データを出力する深層学習モデル。「系列から系列への変換」を行う。 |
| Seq2Seqモデルの例 | 機械翻訳(日本語→英語)、文章要約、質問応答システム |
| Seq2Seqモデルの仕組み | 入力系列を別の表現に変換し、それから出力系列を生成する二段階の処理。様々な長さの系列データを柔軟に扱える。 |
エンコーダとデコーダ

「系列変換モデル」とも呼ばれるSeq2Seqモデルは、入力されたデータの並びを別のデータの並びに変換する技術です。このモデルの中核を担うのが、符号器と復号器という二つの重要な部品です。
まず、符号器は入力となるデータの並びを受け取ります。そして、その並びに含まれる情報を、決まった長さのベクトルに変換します。このベクトルは、入力データの並びが持つ意味や文脈をぎゅっと凝縮したものと捉えることができ、「文脈ベクトル」とも呼ばれています。たとえば、「こんにちは」という日本語を英語に変換する場合、「こんにちは」という並びが符号器によって文脈ベクトルに変換されます。
次に、復号器は符号器が作った文脈ベクトルを受け取ります。そして、それを基に、目的とする出力の並びを作り出します。先ほどの例で言えば、復号器は「こんにちは」の文脈ベクトルから、「Hello」という英語の並びを生成します。
符号器と復号器は、多くの場合、「回帰型ニューラルネットワーク」と呼ばれる仕組みでできています。これは、時間とともに変化するデータを扱うのに適した技術です。回帰型ニューラルネットワークは、過去の情報を記憶する能力があるため、データの並びの順番に関する情報をうまく捉えることができます。
このように、符号器と復号器が連携することで、Seq2Seqモデルは様々な系列変換タスクをこなすことができます。例えば、機械翻訳、文章要約、質疑応答システムなど、幅広い分野で応用されています。これらのタスクでは、入力と出力が異なる長さの並びになることが一般的ですが、Seq2Seqモデルは柔軟に対応できます。
再帰型ニューラルネットワーク

再帰型ニューラルネットワーク(再帰型神経回路網)は、時系列データのような連続したデータを扱うのに優れた、特別な構造を持つ神経回路網の一種です。まるで人間の記憶のように、過去の情報を保持しながら処理を進めることができます。この過去の情報を記憶する仕組みが「隠れ状態(隠れた状態)」です。
隠れ状態は、回路網内部に存在する一種のメモ帳のようなもので、過去の入力データの影響を蓄積します。再帰型神経回路網は、新しいデータが入力されるたびに、現在の入力とこの隠れ状態を組み合わせて、新たな隠れ状態を作り出します。この処理を繰り返すことで、過去の情報が現在の処理に影響を与え続けるのです。まるで、文章を読む際に前の単語を覚えておくことで、文章全体の理解を深めていくようなものです。
例えば、「空は青い」という文章を考えます。「空」という単語が入力されると、その情報が隠れ状態に保存されます。次に「は」が入力されると、回路網は「空」の情報が保存された隠れ状態と「は」の情報を組み合わせて、新たな隠れ状態を作ります。最後に「青い」が入力されると、回路網は「空」と「は」の情報が反映された隠れ状態と「青い」の情報を組み合わせて最終的な出力を生成します。このように、各単語は独立して処理されるのではなく、前の単語の影響を受けながら処理されるため、単語間の関係性や文脈を理解することが可能になります。
系列変換モデル(系列変換器)と呼ばれる構造では、符号化器と復号化器という二つの再帰型神経回路網が用いられます。符号化器は、入力系列を受け取り、最後の入力までの全ての情報を隠れ状態に蓄積します。この最終的な隠れ状態は「文脈ベクトル(文脈の情報を持ったベクトル)」と呼ばれ、入力系列全体の要約のような役割を果たします。そして、この文脈ベクトルが復号化器に渡されます。復号化器は、受け取った文脈ベクトルを初期状態として、出力系列を一つずつ生成していきます。このように、再帰型神経回路網は、自然言語処理をはじめ、音声認識、機械翻訳など、様々な分野で活用されています。
機械翻訳への応用

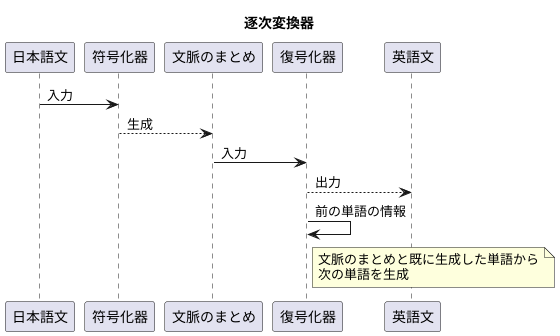
逐次変換器というものは、言葉の置き換えの分野で目覚ましい成果をあげました。これまでの言葉の置き換えの手法は、文を単語や短い言葉の繋がりに区切って置き換えていましたが、逐次変換器では文全体を一度に扱うことができます。そのため、より自然でなめらかな置き換えが実現できるのです。
たとえば、日本語の文を英語に置き換える場面を考えてみましょう。逐次変換器は符号化器と復号化器という二つの部分からできています。まず、符号化器が日本語の文を受け取ります。そして、その文全体の意味を捉えた情報を文脈のまとめとして作成します。次に、復号化器がこの文脈のまとめを基に、英語の文を作り出していきます。
この時、復号化器は文脈のまとめだけでなく、既に作り出した単語の情報も利用します。たとえば、「こんにちは」という日本語を「Hello」と置き換えた後、「お元気ですか」という続きを置き換える際には、「Hello」に続く言葉としてふさわしいものを選びます。このように、一つ前の単語を踏まえることで、文脈に合った自然な置き換えが作られていくのです。
従来の手法では、単語や句ごとに置き換えるため、文全体の流れが失われてしまうことがありました。しかし、逐次変換器は文全体を一度に扱うことで、前後の関係を理解し、より自然な置き換えを実現しています。これにより、言葉の置き換えの精度は飛躍的に向上し、異なる言葉を話す人々の意思疎通をよりスムーズにするものと期待されています。
様々な応用

系列から系列への変換を学習する仕組みである系列変換モデルは、機械翻訳以外にも多くの場面で使われています。このモデルは、入力と出力がどちらも連続したデータである場合にうまく機能します。具体的には、文章を短くまとめる作業、人とコンピュータが言葉を交わすこと、音声を文字に変換すること、画像を言葉で説明することなど、様々な応用が考えられます。
文章を短くまとめる作業では、長い文章を入力として与え、短い要約文を作成します。例えば、ニュース記事全体を入力として、その記事のや短い概要を生成することができます。これは大量の情報を効率的に把握するのに役立ちます。
人とコンピュータが言葉を交わすことも、系列変換モデルで実現できます。ユーザーが入力した言葉に対して、自然で適切な返答を生成することで、人間とコンピュータの間で会話のようなやり取りを可能にします。例えば、お店への問い合わせに対する自動応答システムや、雑談を楽しむためのチャットボットなどが考えられます。
音声を文字に変換することも、このモデルの応用の一つです。音声データを入力として、それに対応するテキストデータを出力します。会議の音声を議事録に書き起こしたり、音声検索で文字を入力する代わりに声で検索したりする際に活用されています。
画像を言葉で説明することも可能です。画像を入力として与えると、その画像の内容を説明する文章が生成されます。例えば、風景写真を入力すると、「青い空の下に広がる緑の草原に、一頭の馬が草を食んでいる」といった説明文が生成されます。これは視覚障碍者向けの支援技術としても役立ちます。
このように、系列変換モデルは様々な分野で活用されている大変便利な技術と言えるでしょう。入力と出力が連続したデータである限り、様々な応用が考えられ、今後も更なる発展が期待されます。
| タスク | 入力 | 出力 | 例 |
|---|---|---|---|
| 文章要約 | 長い文章 | 短い要約文 | ニュース記事 → 記事の短い概要 |
| 対話生成 | ユーザー入力 | 自然な返答 | 質問 → 回答、雑談 |
| 音声認識 | 音声データ | テキストデータ | 会議音声 → 議事録、音声検索 |
| 画像キャプション生成 | 画像データ | 説明文 | 風景写真 → 「青い空の下に広がる緑の草原に、一頭の馬が草を食んでいる」 |
モデルの改良

系列変換モデルは、文章の翻訳や要約など、様々な場面で活用されています。このモデルの中でも、系列対系列(Seq2Seq)モデルは代表的な存在です。基本的なSeq2Seqモデルは、符号化器と復号化器の二つの部分から成り立っています。符号化器は、入力された文章を一連の数値情報に変換する役割を担い、復号化器は、その数値情報をもとに、目的とする文章を生成します。
しかし、基本的なSeq2Seqモデルには、長い文章を扱うのが苦手という課題がありました。文章が長くなるにつれて、重要な情報が失われてしまい、正確な変換が難しくなるのです。この課題を解決するために、様々な改良が加えられてきました。
注目機構(Attention機構)は、Seq2Seqモデルの改良において重要な役割を果たしました。これは、復号化器が各単語を生成する際に、入力文章のどの部分に注目すべきかを学習する仕組みです。例えるなら、翻訳を行う際に、原文のどの単語に注目しながら訳文を生成するかを自動的に判断するようなものです。これにより、より正確で文脈に沿った出力が可能になり、長い文章でも高い精度を維持できるようになりました。
さらに、変換器モデル(Transformerモデル)が登場しました。これは、従来のSeq2Seqモデルで使われていた再帰型ニューラルネットワーク(RNN)を使わずに、注目機構のみで系列変換を行うモデルです。RNNは、文章を単語ごとに順番に処理していくため、並列処理ができず、学習に時間がかかるという欠点がありました。一方、変換器モデルは、並列処理が可能であるため、学習速度が大幅に向上し、より大規模なデータで学習できるようになりました。
これらの改良により、Seq2Seqモデルはますます高性能化し、機械翻訳や文章要約、対話システムなど、様々な分野で活躍が期待されています。今後の更なる発展にも注目が集まっています。