
R-CNN:物体検出の革新

AIを知りたい
先生、「R-CNN」って物体検出で使うって聞きましたけど、どんな仕組みなんですか?

AIエンジニア
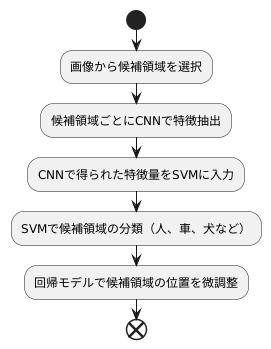
そうですね、R-CNNは画像の中から物体の場所を見つける技術です。まず、画像の中から物体がありそうな場所をいくつか四角で囲みます。次に、囲んだ部分を画像認識に強いCNNという技術を使って分析し、それぞれの四角が何の物体であるか、そして四角の位置をより正確に調整します。
AIを知りたい
なるほど。でも、物体がありそうな場所ってどうやって見つけるんですか?あと、CNNで分析した後はどうするんですか?
AIエンジニア
物体がありそうな場所を見つけるには、Selective Searchという方法を使います。色々な大きさの四角をたくさん作って、物体らしいものを囲むように調整していくんです。CNNで分析した後は、サポートベクトルマシン(SVM)という技術で物体の種類を判別し、最後に四角の位置を微調整します。ただ、この方法はちょっと時間がかかるのが欠点ですね。
R-CNNとは。
『R-CNN』という、人工知能で使われる言葉について説明します。R-CNNは、画像の中から物を見つけ出すための二段階方式の技術です。まず『Selective Search(選択的探索)』という方法で、物体の特徴を表していそうな四角い領域をいくつか選び出します。次に、選ばれた四角形をCNNという技術で処理し、特徴を取り出します。この特徴は、CNNの最終出力の手前の層から得られます。CNNで正しく処理するためには、四角形の大きさを揃える必要があります。そのため、選ばれた四角形の形を変えたり、大きさを調整したりします。最後に、得られた特徴をサポートベクトルマシン(SVM)という技術を使って種類分けし、さらに別の計算で四角形の位置を調整します。ただし、SVMは分類したい種類ごとに用意する必要があります。この方法は、候補となる四角形一つ一つにCNNを適用するため、処理に時間がかかります。R-CNNの仕組みや使い方を、Pythonというプログラミング言語を使って具体的に説明した記事を公開しています。下のリンクからご覧ください。
候補領域の選定

「候補領域の選定」とは、画像の中から物体が写っているであろう場所を絞り込む作業のことです。この作業は、まるで宝探しをする前に、宝が埋まっている可能性の高い場所を地図上でいくつか印をつけるようなものです。この印をつけた場所一つ一つを「候補領域」と呼び、四角形で表現します。
この候補領域を見つけるために、「選択的探索」と呼ばれる手法がよく使われます。この手法は、まるでジグソーパズルを組み立てるように、画像の色や模様といった特徴が似ている小さな領域を少しずつ繋げて、より大きなまとまりを作っていきます。例えば、青い空と白い雲、または赤いリンゴと緑の葉っぱといった具合です。そして、最終的に出来上がったまとまりを四角形で囲み、候補領域として抽出します。
この選択的探索を使う利点は、画像全体をくまなく調べる必要がないという点です。宝探しの例で言えば、山全体を探すのではなく、宝の地図に印がついている場所に絞って探すようなものです。これにより、処理の効率が大幅に向上します。しかし、この手法にも欠点があります。場合によっては、数百から数千個もの候補領域が抽出されることがあるのです。これは、宝の地図に印が多すぎて、結局どこを探せば良いのかわからなくなってしまうようなものです。つまり、候補領域が多すぎると、その後の処理に時間がかかってしまう可能性があるのです。そのため、候補領域の数を適切に絞り込む工夫が重要になります。
画像の変形と大きさ調整

写真や絵などの画像を扱う時、様々な形や大きさの画像を切り出すことがあります。例えば、ある写真から特定の人物や物を囲むように切り出すと、四角い切り抜きができますが、その大きさや縦横の比率はまちまちです。これを「候補領域」と呼びます。これらの候補領域をコンピュータで解析するためには、全ての領域を同じ大きさに揃える必要があります。なぜなら、画像解析によく使われる「畳み込みニューラルネットワーク」という技術は、一定の形と大きさのデータでないと上手く処理できないからです。
そこで、「R-CNN」という画像認識手法では、切り出した候補領域の形をあらかじめ決めた大きさに揃える処理を行います。具体的には、それぞれの候補領域を指定された大きさの四角に合うように変形するのです。例えば、正方形の領域を長方形に変形したり、逆に長方形を正方形に変形したりします。この変形処理のおかげで、畳み込みニューラルネットワークは安定して画像の特徴を捉えることができるようになります。
しかし、この変形処理には欠点もあります。無理やり画像の形を変えることで、画像が歪んでしまう可能性があるのです。例えば、細長い長方形の領域を正方形に無理やり変形すると、中の物が横に広がって見えたり、縦に縮んで見えたりします。また、重要な情報が切り取られてしまう可能性もあります。画像の端の部分が変形の過程で失われてしまい、その部分に写っていた重要な情報が見えなくなってしまうかもしれません。このように、画像の変形と大きさ調整は、画像認識において重要な処理であると同時に、歪みや情報欠落のリスクも抱えています。
畳み込みニューラルネットワークによる特徴抽出

画像認識の分野において、畳み込みニューラルネットワーク(CNN)は、その優れた性能で注目を集めています。特に、画像の中から特定の物体を検出する物体検出技術においては、CNNを用いた特徴抽出が重要な役割を担っています。まず、検出したい物体の候補となる領域を画像から切り出します。そして、これらの候補領域の大きさを統一し、CNNに入力します。
CNNは、人間の視覚野の働きを模倣した構造を持ち、複数の層が積み重なった構造をしています。最初の層は、画像の細かい特徴、例えばエッジや角などを抽出します。次の層は、前の層で抽出された特徴を組み合わせ、より複雑な特徴、例えば円や四角などを抽出します。このように、層が深くなるにつれて、より抽象的で高度な特徴が抽出されていきます。例えば、椅子の脚や背もたれといった特徴から、「椅子」という概念を認識できるようになります。
物体検出においては、R-CNNという手法がよく用いられます。R-CNNでは、CNNの出力層の一つ手前の全結合層の出力を特徴量として利用します。出力層は、最終的な識別結果を出力する層ですが、その手前の全結合層は、様々な特徴が統合された情報を保持しています。この情報は、各候補領域がどのような物体を表しているのかを判断するための重要な手がかりとなります。例えば、候補領域が「猫」を表しているのか、「犬」を表しているのかを判断するために必要な情報が含まれています。
このように、CNNを用いることで、画像から階層的な特徴を抽出することができ、物体の種類や形状などを高精度で識別することが可能になります。この技術は、自動運転や医療画像診断など、様々な分野で応用され、私たちの生活をより豊かに、そして安全なものにするために役立っています。
分類と位置の調整

画像の中から物を見つける技術について説明します。この技術では、まず画像の中から、物らしき場所をいくつか選び出します。この選ばれた場所を候補領域と呼びます。次に、それぞれの候補領域について、それが一体何なのかを調べます。この調べる作業には、畳み込みニューラルネットワーク(CNN)と呼ばれる技術と、サポートベクトルマシン(SVM)と呼ばれる技術を組み合わせて使います。
CNNは、画像の特徴を捉えるのが得意です。CNNを使って画像の特徴を数値化し、その数値をSVMに渡します。SVMは、渡された数値に基づいて、候補領域が何であるかを分類します。例えば、「人」、「車」、「犬」などといった具合です。SVMは分類の精度が高いことで知られています。
しかし、候補領域が「人」だと分かったとしても、その位置が正確とは限りません。候補領域は、大まかな四角形で表されているため、実際の人の位置とは少しずれている可能性があります。そこで、位置のずれを修正するために、回帰モデルと呼ばれる技術を使います。回帰モデルは、CNNから得られた特徴量と、実際の人の位置との関係を学習します。そして、その学習結果に基づいて、候補領域の位置を微調整します。これにより、人の位置をより正確に特定することができます。
ただし、SVMを使う際には注意点があります。SVMは、分類したい種類ごとに用意する必要があります。つまり、「人」を分類するためのSVM、「車」を分類するためのSVM、といった具合です。そのため、多くの種類の物体を検出したい場合、たくさんのSVMが必要になります。これは、計算量が増えることを意味し、処理に時間がかかる可能性があります。
処理時間の課題

画像中の物体を認識する技術の一つである領域畳み込みニューラルネットワーク(R-CNN)は、処理に時間がかかるという大きな課題を抱えています。これは、R-CNNの仕組みが原因となっています。
R-CNNは、まず画像の中から物体が存在する可能性のある領域を数百から数千個も選び出します。この選び出す作業を提案領域抽出と言い、代表的な手法の一つに選択的探索があります。選択的探索自体も処理に時間を要しますが、R-CNNの処理時間の多くは、選び出した領域一つ一つを畳み込みニューラルネットワーク(CNN)に入力して特徴を抽出する部分に費やされます。
畳み込みニューラルネットワークは、画像の特徴を捉えるのが得意な仕組みですが、一つ一つの領域を順番に処理していくため、領域の数が多いほど処理時間が長くなってしまうのです。例えば、動画のように連続した画像から物体を検出する場合には、処理時間の遅さが大きな足かせとなります。また、大量の画像を扱う場合にも、処理時間の長さが作業全体の効率を下げてしまう可能性があります。
この問題を解決するために、画像処理装置(GPU)を用いた並列処理など、様々な工夫が凝らされています。並列処理とは、複数の領域を同時に処理することで、全体的な処理時間を短縮する技術です。しかし、これらの工夫を施しても、まだ人間の目と同じように遅延なく物体を検出する「リアルタイム処理」を実現するには至っていません。R-CNNの処理速度の遅さは、実用化に向けて大きな壁となっているのです。そのため、より高速な物体検出手法の開発が、現在も盛んに行われています。
応用例と発展

領域畳み込みニューラルネットワーク(R-CNN)は、画像中の物体の位置を特定し、種類を判別する物体検出技術に革新をもたらしました。この技術は、様々な場面で活用されています。例えば、自動運転の分野では、人や車、自転車などの周りの状況を把握するために使われています。これにより、安全な運転支援が可能となります。また、医療の分野では、レントゲン写真やCT画像から病気を示す兆候を見つけるのに役立っています。医師の診断を支援し、早期発見に繋がることが期待されています。さらに、街中や建物に設置された監視カメラの映像を解析することで、不審な行動を素早く見つけることができます。防犯対策として、安全な社会づくりに貢献しています。また、ロボットに搭載することで、周囲の環境を認識し、適切な行動をとることができるようになります。このように、R-CNNは幅広い分野で応用され、私たちの生活をより便利で安全なものにしています。
しかし、初期のR-CNNには、処理速度が遅いという欠点がありました。リアルタイムでの物体検出には不向きで、応用範囲が限られていました。この問題を解決するために、改良版のFast R-CNN、Faster R-CNNが開発されました。これらの改良版では、処理方法を工夫することで、計算量を大幅に削減し、処理速度を向上させました。これにより、動画のような動きの速い映像に対しても、ほぼ同時に物体を検出することが可能になりました。例えば、スポーツの試合中継で、ボールの動きをリアルタイムで追跡したり、工場の生産ラインで、製品の欠陥を瞬時に見つけるといったことが可能になります。R-CNNは、物体検出技術の基礎を築き、その後の技術発展に大きく貢献しました。改良版の登場により、実用性が飛躍的に向上し、様々な分野での応用が進んでいます。今後も更なる発展が期待され、私たちの生活をより豊かにする技術となるでしょう。
| 分野 | 活用例 | 効果 |
|---|---|---|
| 自動運転 | 人、車、自転車などの検出 | 安全な運転支援 |
| 医療 | レントゲン、CT画像の解析 | 病気の兆候の早期発見 |
| 防犯 | 監視カメラの映像解析 | 不審な行動の検知 |
| ロボット | 周囲の環境認識 | 適切な行動の実現 |
| R-CNNの種類 | 特徴 | 活用例 |
|---|---|---|
| 初期のR-CNN | 処理速度が遅い | – |
| Fast R-CNN, Faster R-CNN | 処理速度の向上 | スポーツ中継、生産ラインでの欠陥検出 |