
モデル圧縮:小さく賢く、速く

AIを知りたい
先生、「モデル圧縮」って、なんとなくわかるんですけど、もっと詳しく教えてください。

AIエンジニア
いいかい? モデル圧縮は、例えるなら、大きな荷物を小さくまとめて、運ぶ手間を減らすようなものなんだ。中身はなるべくそのままに、小さく軽くして、運びやすくする技術だよ。
AIを知りたい
なるほど。でも、中身を変えずに小さくするって、具体的にどうやるんですか?
AIエンジニア
いくつか方法があるんだけど、例えば「蒸留」は、大きな荷物の内容を、小さな荷物にうまく詰め替えるようなもの。「枝切り」は、荷物の中から不要なものを取り除くこと。「量子化」は、荷物の細かい情報を少しだけ粗くすることで、全体の情報量を減らすようなものだよ。
モデル圧縮とは。
人工知能でよく使われる「模型を小さくする技術」について説明します。この技術は、模型の正確さを保ちつつ、データの大きさを減らす方法です。深い学びの分野では、模型の正確さを上げるために層を増やすなどして複雑にしますが、計算量が増えてしまい、費用と時間がかかってしまうという問題があります。そこで、機械学習では模型を小さくする技術が必要になります。代表的な方法として「まねる」「枝を落とす」「数字を丸める」の3つがあります。
モデル圧縮とは

近年の機械学習、とりわけ深層学習の進歩には目を見張るものがあります。画像の認識や自然言語の処理、音声の認識など、様々な分野で目覚ましい成果を上げています。しかし、高い精度を持つモデルは、多くの場合、莫大な計算資源と記憶容量を必要とします。これは、携帯端末や組み込み機器など、資源が限られた環境への導入を難しくする大きな要因となっています。そこで注目を集めているのが「モデル圧縮」です。
モデル圧縮とは、モデルの精度を保ちつつ、あるいはわずかに精度が下がってもよいようにしながら、モデルの大きさを小さくする技術です。例えるなら、洋服の整理と似ています。クローゼットにたくさんの服があふれていると、場所を取ってしまいます。そこで、着ない服を処分したり、圧縮袋を使って小さくしたりすることで、スペースを節約できます。モデル圧縮もこれと同じように、モデルの中に不要な情報や重複している情報を整理したり、より効率的な表現方法に変換したりすることで、モデルのサイズを縮小します。
モデル圧縮には様々な方法があります。代表的なものとしては、枝刈り、量子化、蒸留などが挙げられます。枝刈りは、モデルの中にあまり重要でない部分を特定し、それを削除することでモデルを小さくする手法です。量子化は、モデルのパラメータを表現するのに必要なビット数を減らすことで、モデルのサイズを小さくする手法です。蒸留は、大きなモデルの知識を小さなモデルに伝達することで、小さなモデルでも高い精度を実現する手法です。
これらの手法を用いることで、計算にかかる費用と記憶容量の使用量を減らし、推論の速度を上げることができます。まさに、限られた資源で最高の性能を引き出すための工夫と言えるでしょう。この技術により、高性能な人工知能をより多くの機器で利用できるようになり、私たちの生活はより便利で豊かになることが期待されます。
| 手法 | 説明 | メリット |
|---|---|---|
| 枝刈り | モデルの重要でない部分を削除 | モデルのサイズ縮小、計算速度向上 |
| 量子化 | パラメータ表現のビット数を削減 | モデルのサイズ縮小、メモリ使用量削減 |
| 蒸留 | 大きなモデルの知識を小さなモデルに伝達 | 小さなモデルでも高精度を実現 |
モデル圧縮の必要性

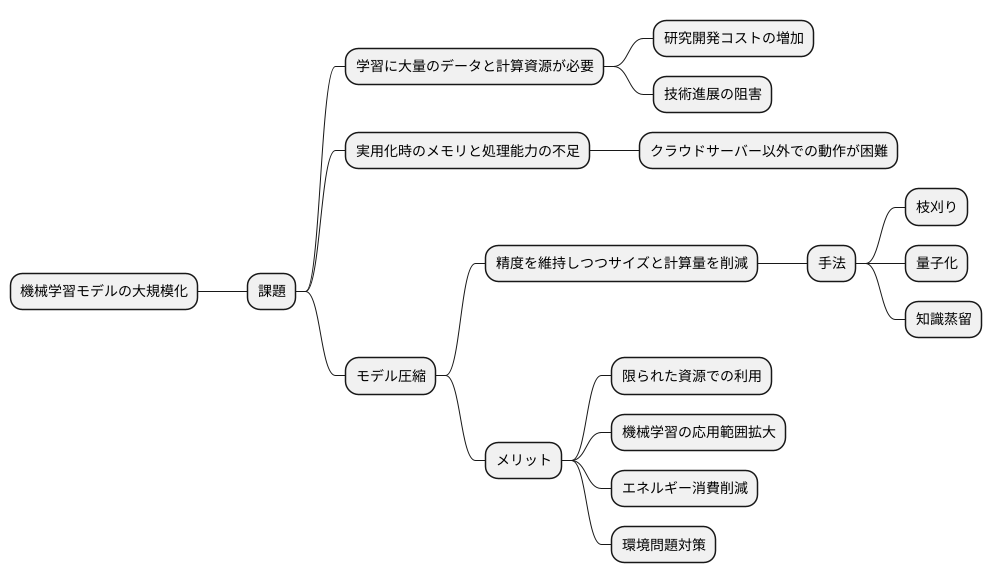
近年の機械学習モデル、特に深層学習モデルは目覚ましい成果を上げていますが、その裏ではモデルの大規模化が急速に進んでいます。高精度な予測を行うためには、数多くの層と膨大なパラメータが必要となるためです。しかし、この大規模化は様々な課題を生み出しています。
まず、モデルの学習には大量のデータと計算資源が必要となります。高性能な計算機と潤沢な電力供給がなければ、学習に数日から数週間かかることもあります。これは研究開発のコスト増加に直結し、新しい技術の進展を阻害する要因になりかねません。
さらに、学習が完了したモデルを実用化する際にも、多くのメモリと高い処理能力が必要です。クラウドサーバーのような恵まれた環境であれば問題ありませんが、スマートフォンや家電製品のような限られた計算資源しかない機器では、そのままでは動作させることができません。このような機器は身の回りに溢れており、それらに高度な機械学習モデルの恩恵をもたらすためには、モデルを小型化・軽量化する必要があります。
そこで注目されているのがモデル圧縮という技術です。モデル圧縮は、精度をなるべく落とさずにモデルのサイズと計算量を削減する手法の総称です。具体的には、不要なパラメータを削除する枝刈り、パラメータの値を量子化する量子化、複数の層を1つの層にまとめる知識蒸留など、様々な方法があります。
モデル圧縮によって、限られた資源しかない機器でも高度な機械学習モデルが利用できるようになります。これは、機械学習の応用範囲を大きく広げることに繋がります。また、処理に必要なエネルギー消費も削減できるため、環境問題への対策としても有効です。このように、モデル圧縮は機械学習の持続的な発展にとって不可欠な技術と言えるでしょう。
代表的な圧縮手法

様々な情報を小さくまとめる技術、いわゆる圧縮技術は、限られた資源を有効に活用するために欠かせません。この技術は、画像や音声といったデータだけでなく、人工知能の中核を担う「モデル」にも適用されています。モデルを小さく軽くする「モデル圧縮」は、処理速度の向上や省電力化といった多くの利点をもたらします。そして、このモデル圧縮を実現する代表的な方法として、「蒸留」「枝刈り」「量子化」の3つの手法が挙げられます。
まず、「蒸留」は、例えるなら、熟練の職人(教師モデル)が、弟子(生徒モデル)に技術を伝授するような手法です。巨大で複雑な教師モデルが持つ知識や判断能力を、より小さくシンプルな生徒モデルに受け継がせることで、教師モデルの高い性能は維持しつつ、軽量で扱いやすいモデルを実現します。まるで、熟練の職人の技を凝縮した秘伝の書を弟子に渡すように、効率的に知識を伝達するのです。
次に、「枝刈り」は、木を剪定するように、不要な枝葉を落とすことで、モデル全体の大きさを縮小する手法です。人工知能のモデルは、無数の繋がり(パラメータ)によって構成されていますが、その中には、全体の性能に影響が少ないものも含まれています。まるで、木の成長に必要のない枝を剪定するように、これらの重要度の低いパラメータを特定し、削除することで、モデルを軽量化し、処理速度の向上を図ります。
最後に、「量子化」は、情報を表現する際の細かさを調整することで、データ量を削減する手法です。例えば、色の濃淡を32段階で表現していたものを8段階で表現するように、モデルのパラメータを表現するのに必要なビット数を減らします。これは、高精細な画像を少し粗く表示するようなもので、情報の精度を多少落とす代わりに、メモリ使用量を大幅に削減し、処理の効率化を実現します。
このように、それぞれの圧縮手法には異なる特徴があり、目的に合わせて最適な手法を選択することが重要です。これらの技術は、人工知能をより身近なものにするために、重要な役割を担っています。
| 手法 | 概要 | 例え | メリット |
|---|---|---|---|
| 蒸留 | 巨大な教師モデルの知識を小さい生徒モデルに転移 | 熟練職人が弟子に技術伝授 | 高性能維持、軽量化 |
| 枝刈り | 重要度の低いパラメータを削除 | 木の剪定 | 軽量化、処理速度向上 |
| 量子化 | パラメータ表現のビット数を削減 | 画像の解像度を下げる | メモリ使用量削減、処理効率化 |
蒸留

蒸留とは、例えるなら熟練の職人が長年の経験で培った知識や技術を弟子に伝えるように、巨大な学習済みモデルが持つ豊富な知識をより小さなモデルへと受け継がせる技術です。巨大なモデルは、膨大な量のデータから学習することで、様々な課題に対する高い能力を獲得しています。しかし、その大きさゆえに運用コストが高く、実用化の壁となることもあります。そこで、蒸留という手法を用いて、巨大モデルのエッセンスとも言える知識を凝縮し、コンパクトなモデルに移植することで、規模を縮小しつつも高い性能を維持することが可能になります。
具体的には、巨大なモデルの出力値、つまり予測結果を教師データとして利用し、小さなモデルを学習させます。通常の学習では、正解ラベルが教師データとなりますが、蒸留では巨大なモデルの出力値がその役割を担います。巨大なモデルは、正解ラベルだけでなく、データに含まれる隠れたパターンや関係性も捉えているため、その出力値には正解ラベル以上の情報が含まれています。小さなモデルは、この豊富な情報を吸収することで、巨大なモデルの思考過程を模倣するように学習し、結果として高い精度を実現できるのです。
蒸留は、まるで職人が弟子の成長を見守るように、巨大なモデルが小さなモデルの学習を導くプロセスと言えます。効率的な学習を実現するだけでなく、限られた資源でも高性能なモデルを利用できるため、様々な分野への応用が期待されています。例えば、スマートフォンなどの計算資源が限られた環境でも高度な処理を可能にするなど、その可能性は大きく広がっています。また、巨大なモデルの学習にかかる時間やコストを削減する効果も期待できます。まさに、知識の継承という名の通り、未来への技術発展を支える重要な技術と言えるでしょう。
| 項目 | 内容 |
|---|---|
| 蒸留とは | 巨大な学習済みモデルの知識をより小さなモデルに継承させる技術 |
| 目的 | 巨大モデルの運用コストの高さ、実用化の難しさの克服。規模を縮小しつつ高い性能を維持。 |
| 具体的な方法 | 巨大モデルの出力値(予測結果)を教師データとして、小さなモデルを学習させる。 |
| 利点 |
|
| 応用例 | スマートフォンなど計算資源が限られた環境での高度な処理 |
| その他 | 巨大モデルは正解ラベル以上の情報(隠れたパターンや関係性)を出力値に含むため、小さなモデルは思考過程を模倣するように学習できる。 |
枝刈り

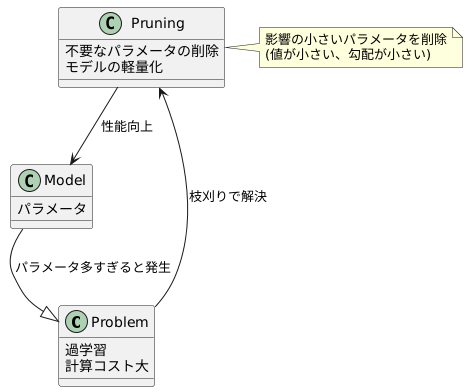
木を育てる時と同じように、機械学習のモデルも、大きくなりすぎると問題が生じることがあります。木の枝葉が伸び過ぎると、全体に栄養が行き渡らず、果実が大きくならないように、モデルのパラメータ数が多すぎると、学習データだけに特化しすぎてしまい、新しいデータに対してうまく対応できなくなる「過学習」という状態に陥ってしまいます。また、計算に多くの時間や資源が必要になり、非効率です。そこで、「枝刈り」という手法が登場します。
枝刈りは、名前の通り、木から不要な枝葉を切り落とすように、モデルから不要なパラメータを取り除く技術です。木の剪定によって、残った枝葉により多くの栄養が行き渡り、果実の成長が促進されるように、モデルも枝刈りによって必要なパラメータのみが残るため、効率的に学習できます。
具体的には、パラメータ一つ一つが、モデルの精度にどれくらい影響を与えるかを調べます。その結果、影響が小さいパラメータは重要度が低いと判断し、モデルから削除します。例えば、パラメータの値そのものが非常に小さい場合や、学習の過程で値がほとんど変化しない(勾配が小さい)場合は、そのパラメータはモデルの出力に大きな影響を与えていないと考えられます。これらのパラメータを取り除くことで、モデルはより小さく、より速くなります。まるで、贅肉を落として身軽になったランナーのようです。
このように、枝刈りは、モデルの複雑さを軽減し、過学習を防ぎ、計算の効率を高める、重要な技術です。特に、限られた計算資源で複雑な問題を解く必要がある場合に、その真価を発揮します。まるで熟練の庭師が木を美しく整えるように、枝刈りはモデルの性能を最大限に引き出すための、大切な技術なのです。
量子化

情報を扱う時、その情報をどれくらい細かく表現するかは大切な問題です。情報の粒度を調整することで、必要な記憶容量を減らし、処理速度を上げることができるのです。これを量子化と言います。
例えば、色の濃さを考えてみましょう。本来、色の濃さは無限に細かく表現できます。しかし、コンピュータで扱うためには、この無限の濃さを有限の段階に分けなければなりません。これが量子化の考え方です。段階を細かくすれば、元の情報により近い表現ができますが、多くの記憶容量が必要になります。反対に、段階を粗くすれば、記憶容量は少なくて済みますが、情報の細部は失われてしまいます。
この量子化は、様々な情報に適用できます。画像の色情報以外にも、音声データや、人工知能で使うモデルのパラメータなども量子化できます。人工知能のモデルは、膨大な数値の集まりでできています。これらの数値を量子化することで、モデルのサイズを小さくし、計算を速くすることが可能になります。
量子化の方法には、いくつか種類があります。均一量子化は、数値を等間隔の段階に分ける方法です。簡単で扱いやすい反面、情報の偏りがあると、無駄が生じることがあります。例えば、ある範囲に数値が集中している場合、他の範囲にはほとんど数値がないにも関わらず、等間隔に段階を分けてしまうため、記憶容量を効率的に使えません。
一方、非均一量子化は、数値の分布に合わせて段階の間隔を調整する方法です。数値が集中している範囲は細かく段階を分け、そうでない範囲は粗く段階を分けることで、より効率的に情報を表現できます。しかし、この方法では、段階を決めるための計算が複雑になります。
近年は、量子化を高速に行うための専用の計算機も開発されています。これらの計算機を使うことで、量子化のメリットはさらに大きくなり、限られた計算資源でより高度な処理を行うことが可能になります。
| 項目 | 説明 |
|---|---|
| 量子化 | 情報の粒度を調整し、有限の段階に分割する処理。記憶容量削減、処理速度向上に効果あり。 |
| 色の濃さの量子化 | 無限の濃さを有限の段階に分割。段階が細かいほど高精度だが、記憶容量が増加。 |
| 量子化の適用例 | 画像の色情報、音声データ、人工知能モデルのパラメータなど。 |
| 均一量子化 | 数値を等間隔の段階に分割。簡単だが、情報の偏りがあると非効率。 |
| 非均一量子化 | 数値の分布に合わせて段階の間隔を調整。効率的だが、計算が複雑。 |
| 量子化計算機 | 量子化を高速に行うための専用計算機。限られた計算資源で高度な処理が可能に。 |