
Mixup:画像合成による精度向上

AIを知りたい
先生、「混ぜ合わせる」っていう意味の『Mixup』ってデータ拡張の手法がよく分かりません。もう少し詳しく教えてもらえませんか?

AIエンジニア
いいかい? 『Mixup』は二枚の絵を混ぜ合わせて新しい絵を作る手法だよ。例えば、猫の絵と犬の絵を混ぜると、猫のような犬、犬のような猫の絵ができるんだ。
AIを知りたい
なるほど。でも、なぜ絵を混ぜ合わせる必要があるんですか?
AIエンジニア
混ぜ合わせることで、AIが様々な絵のパターンを学習できるようになるからだよ。たとえば、少し猫っぽい犬の絵も学習することで、AIは純粋な犬の絵や猫の絵だけでなく、その間の微妙な特徴も理解できるようになるんだ。その結果、AIはより正確に絵を識別できるようになるんだよ。
Mixupとは。
人工知能で使う言葉に「混ぜ合わせ」というものがあります。(混ぜ合わせは、データを拡張する方法の一つです。)この方法では、二枚の絵を混ぜて新しい絵を作ります。この方法を使うと、ばらつきを抑える効果が出て、あいまいな絵の内容も認識できるようになるので、結果として精度が上がります。
混ぜ合わせる新たな手法

近頃、絵の認識の分野で話題になっている混ぜ合わせの新しい方法についてお話します。
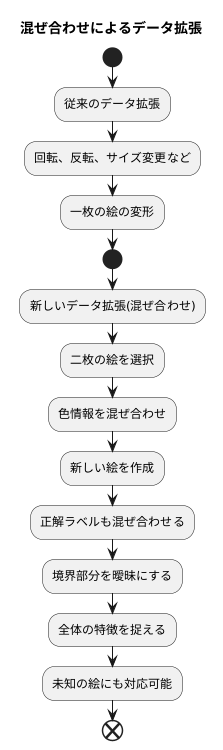
機械学習では、限られた学習データから人工的に新しいデータを作ることで、学習の効果を高める技術があります。これをデータ拡張と言います。今回ご紹介する混ぜ合わせの方法は、このデータ拡張の新しいやり方です。
従来のデータ拡張では、絵を回転させたり、反転させたり、大きさを変えたりするなど、一つの絵だけを変形していました。しかし、この新しい方法は、複数枚の絵を混ぜ合わせるという画期的な方法です。具体的には、二枚の絵を選び、それぞれの絵の色情報を少しずつ混ぜ合わせ、新しい絵を作り出します。混ぜ合わせる割合は、ランダムに決められます。同時に、それぞれの絵に対応する正解ラベルも、同じ割合で混ぜ合わせます。例えば、猫の絵と犬の絵を混ぜ合わせた場合、新しい絵の正解ラベルは、猫と犬の混合になります。
この方法を使うと、学習データのバリエーションを増やすだけでなく、絵の境界部分を曖昧にする効果があります。境界部分が曖昧になることで、機械学習モデルは、絵の細かい部分にとらわれすぎることなく、全体の特徴を捉えることができるようになります。結果として、未知の絵に対しても、より正確に認識できるようになります。
このように、複数枚の絵を混ぜ合わせる新しい方法は、絵の認識の分野で大きな進歩をもたらす可能性を秘めています。今後、様々な分野への応用が期待されます。
二枚の画像を合成

二枚の写真を組み合わせることで、新しい写真を作ることができます。これは、まるで絵の具を混ぜ合わせるように、二枚の写真の色の情報を混ぜ合わせて新しい色を作り出す作業です。この技術は「ミックスアップ」と呼ばれ、二枚の写真と、どれくらいの割合で混ぜるかを決める数値を使って行います。
混ぜ合わせる割合は、0から1の間の数字で表します。例えば、0.3という数字を選んだとしましょう。この場合、一枚目の写真の色の情報は30%、二枚目の写真の色の情報は残りの70%を使って新しい写真の色を作ります。具体的には、それぞれの色の明るさを表す数値に、この割合を掛け合わせて新しい数値を計算します。
例えば、一枚目の写真の赤色の明るさが100、二枚目の写真の赤色の明るさが50だとします。割合を0.3とすると、新しい写真の赤色の明るさは、100 × 0.3 + 50 × 0.7 = 65 となります。他の色についても同様に計算することで、二枚の写真が滑らかに融合したような、新しい写真が完成します。
この方法を使うことで、全く新しい写真を作ることができます。写真に写っているものが、元の写真とは少し違ったものになるため、学習に使う写真の数を増やすのと同じような効果があります。色々な種類の写真で学習させることで、写真のどこを見れば良いのかを、機械はより深く理解できるようになります。また、二枚の写真の特徴が混ぜ合わさることで、機械は写真の重要な特徴をよりうまく捉えられるようになると期待されています。まるで、色々なものを見聞きすることで、私たちの知識や理解が深まるのと同じように、機械も多くのデータから学ぶことで賢くなっていくのです。
| 項目 | 説明 |
|---|---|
| 技術名 | ミックスアップ |
| 入力 | 2枚の写真、混合割合 (0〜1) |
| 処理 | 写真1の色の情報 × 混合割合 + 写真2の色の情報 × (1 – 混合割合) |
| 出力 | 新しい写真 |
| 例 (混合割合 0.3) | 写真1の赤色の明るさ: 100 写真2の赤色の明るさ: 50 新しい写真の赤色の明るさ: 100 × 0.3 + 50 × 0.7 = 65 |
| 効果 | 学習データ増加効果 写真の重要な特徴の理解促進 |
正則化の効果

機械学習モデルを訓練する際、しばしば過学習という問題に直面します。過学習とは、モデルが訓練データの特徴を細部まで記憶しすぎてしまい、新しいデータに対してうまく対応できなくなる現象です。例えるなら、特定の教科書の内容は完璧に暗記できるのに、応用問題になると全く解けない生徒のような状態です。
この過学習を防ぐための有効な手法の一つが正則化です。正則化とは、モデルが訓練データに過度に適応しすぎるのを防ぎ、より汎用的な能力を身につけるように促すための調整です。様々な正則化の手法がありますが、その中の一つにMixupという興味深い方法があります。
Mixupは、二枚の画像を混ぜ合わせることで、新しいデータを人工的に作り出す技術です。例えば、猫と犬の画像を混ぜ合わせると、猫の特徴と犬の特徴を併せ持った、どちらともつかない曖昧な画像が生成されます。一見すると奇妙な方法ですが、この混ぜ合わせた画像を訓練データに加えることで、モデルの学習に大きな変化が現れます。
混ぜ合わせた画像を使うことで、モデルはデータの多様性をより多く経験することになります。猫と犬の画像が完全に分離したデータで学習するよりも、様々な中間的な特徴を持つ画像を学習することで、モデルは本質的な特徴を捉える能力を高めることができます。つまり、猫と犬を見分ける上で本当に重要な特徴は何なのかを、より深く理解できるようになるのです。
このように、Mixupはデータの多様性を人工的に高めることで、モデルが特定の訓練データに固執するのを防ぎ、より汎用的な特徴を学習することを促します。その結果、過学習が抑えられ、未知のデータに対しても高い識別性能を発揮できるようになるのです。
中間の識別

混ぜ合わせる手法を取り入れることで、見分ける仕組みは、絵の中間的な特徴も捉えられるようになります。たとえば、犬と猫の絵を組み合わせた場合、見分ける仕組みは「犬と猫の中間」といった概念を学ぶことができます。これは、従来の絵を見分ける仕組みでは難しかったことで、混ぜ合わせる手法の大きな利点の一つです。
具体的には、二つの絵をある割合で重ね合わせ、新しい絵を作り出します。合わせて作られた絵と、元の二つの絵の混ぜ合わせた割合に対応する答えをセットにして、見分ける仕組みを学習させます。例えば、犬の絵と猫の絵を37の割合で混ぜ合わせた場合、答えも犬と猫を37の割合で混ぜ合わせたものになります。
この中間的な特徴を学ぶことで、見分ける仕組みはより柔軟な見分け方を身につけ、微妙な違いを持つ絵に対しても高い正しさで見分けられるようになると考えられます。従来の手法では、はっきりとした違いを持つ絵を見分けることは得意でしたが、似たような絵を見分けることは苦手でした。混ぜ合わせる手法を使うことで、この弱点を克服し、より実用的な場面で活用できる見分ける仕組みを作ることが可能になります。
例えば、医療分野における画像診断では、病気の初期段階では、健康な状態との違いがわずかであることがよくあります。混ぜ合わせる手法を用いて学習した見分ける仕組みは、このような微妙な違いも見逃さず、早期診断に役立つ可能性があります。また、工場の検品作業などでも、わずかな傷や汚れを見つける必要がある場合に、この技術が役立つと考えられます。このように、混ぜ合わせる手法は、絵を見分ける技術の活用範囲を大きく広げる可能性を秘めています。
| 手法 | 説明 | 利点 | 適用例 |
|---|---|---|---|
| 混ぜ合わせる手法 | 2つの絵をある割合で重ね合わせ、新しい絵を作成。作成した絵と元の絵の混ぜ合わせた割合に対応する答えをセットで学習。 | 中間的な特徴を捉えることで、微妙な違いを持つ絵も高精度で識別可能。 | 医療画像診断(初期段階の病気識別)、工場の検品作業(わずかな傷や汚れの検出) |
| 従来の手法 | (明示的に記述されていないが、文脈から推測) はっきりとした違いを持つ絵の識別。 | (明示的に記述されていない) | (明示的に記述されていない) |
精度向上への貢献

画像を認識する技術の向上は目覚ましく、私たちの生活にも様々な恩恵をもたらしています。例えば、商品の自動分類や顔認証システムなど、多くの場面で画像認識技術が活用されています。こうした技術の進歩に大きく貢献しているのが、様々な工夫によって認識精度を高めるための研究です。その中で、特に注目されているのが「混ぜ合わせ」という手法です。
この「混ぜ合わせ」は、複数の画像を混ぜ合わせて新たな画像を作り出すことで、学習データの量を人工的に増やす技術です。具体的には、二つの画像を選び、それぞれの画像と、その画像に対応する正解ラベルを特定の割合で混ぜ合わせます。例えば、猫の画像と犬の画像を混ぜ合わせることで、猫と犬の特徴を併せ持つ新たな画像が生成されます。この混ぜ合わせた画像を学習データに加えることで、より多様なデータで学習することが可能となり、結果として認識精度が向上します。
「混ぜ合わせ」の効果は、様々な画像認識の課題で確認されています。特に、画像に写っている物体を特定する「画像分類」の分野では、従来の方法に比べて大きな成果を上げています。これは、「混ぜ合わせ」によって学習データが増えるだけでなく、過学習を防ぐ効果もあるためと考えられています。過学習とは、学習データに特化した認識の仕方を覚えてしまい、未知のデータに対してはうまく認識できない状態を指します。混ぜ合わせによって多様なデータで学習することで、特定のデータに偏ることなく、より汎用的な認識能力を獲得できます。
「混ぜ合わせ」は、比較的簡単な仕組みでありながら高い効果を発揮するため、画像認識の分野で広く利用されることが期待されています。今後の研究によって、さらに性能が向上する可能性もあり、将来が楽しみな技術と言えるでしょう。より精度の高い画像認識技術は、自動運転や医療診断など、様々な分野での応用が期待されており、私たちの生活をより豊かに、そして安全なものにしてくれると信じています。
| 手法 | 説明 | 効果 | 応用分野 |
|---|---|---|---|
| 混ぜ合わせ | 複数の画像を混ぜ合わせて新たな画像を作り出し、学習データの量を人工的に増やす技術 | 学習データの増加、過学習の防止、認識精度の向上 | 画像分類、自動運転、医療診断など |
今後の展望

混ぜ合わせ学習は、画像認識の分野に大きな進歩をもたらした革新的な技術です。今後、この技術を土台とした新たなデータ拡張手法の開発や、他の技術との組み合わせによる更なる性能向上が期待されます。具体的には、混ぜ合わせ学習の手法を改良し、より多様なデータを生成することで、学習データの不足を補い、モデルの汎化性能を向上させることが期待されます。また、混ぜ合わせ学習と他のデータ拡張手法や正則化手法を組み合わせることで、モデルの頑健性を高め、より安定した学習を実現することができるでしょう。
混ぜ合わせ学習の応用範囲は画像認識だけに留まりません。自然言語処理や音声認識といった他の機械学習分野への展開も期待されています。例えば、自然言語処理では、異なる文章を混ぜ合わせることで、より多様な表現を学習させることができます。音声認識では、異なる音声データを混ぜ合わせることで、雑音に対する耐性を向上させることが期待できます。このように、混ぜ合わせ学習は、様々な分野で機械学習モデルの学習をより効果的に行うための強力なツールとなるでしょう。
さらに、混ぜ合わせ学習は、より高度な人工知能の実現に重要な役割を果たすと考えられます。現状の人工知能は、学習データに過剰に適合し、未知のデータに対する予測精度が低下する問題を抱えています。混ぜ合わせ学習は、学習データの偏りを軽減し、モデルの汎化性能を向上させることで、この問題の解決に貢献すると期待されます。また、混ぜ合わせ学習は、説明可能な人工知能の実現にも貢献する可能性を秘めています。混ぜ合わせ学習を用いることで、モデルがどのような特徴に基づいて判断を行っているかをより明確に理解できるようになる可能性があります。今後、混ぜ合わせ学習は、人工知能の更なる発展を支える基盤技術として、幅広い分野で活用されていくことでしょう。
| 項目 | 内容 |
|---|---|
| 技術概要 | 画像認識分野で大きな進歩をもたらした革新的な技術。今後、新たなデータ拡張手法の開発や他技術との組み合わせによる性能向上が期待される。 |
| 画像認識への応用 | 手法改良により多様なデータを生成し、学習データ不足を補い、モデルの汎化性能向上に貢献。他手法との組み合わせでモデルの頑健性向上、安定学習を実現。 |
| 他分野への応用 | 自然言語処理:異なる文章を混ぜ合わせ、多様な表現学習 音声認識:異なる音声データを混ぜ合わせ、雑音耐性向上 |
| 高度なAI実現への貢献 | 学習データの偏りを軽減し、モデルの汎化性能向上。未知データへの予測精度低下問題解決に貢献。説明可能なAI実現にも貢献可能性あり。 |