
Mixup:画像合成による精度向上

AIを知りたい
先生、『Mixup』ってデータ拡張の手法の一つですよね?どういうものか教えてください。

AIエンジニア
そうだね。『Mixup』は2枚の画像を混ぜ合わせて新しい画像を作るデータ拡張の手法だよ。たとえば、犬の画像と猫の画像を混ぜて、犬と猫の特徴を持った新しい画像を作るんだ。
AIを知りたい
混ぜ合わせるって、具体的にはどうするんですか?
AIエンジニア
それぞれの画像に重み付けをして重ね合わせるんだよ。例えば、犬の画像に0.7、猫の画像に0.3の重みを付けて混ぜると、犬の特徴が強い新しい画像ができる。混ぜ合わせた画像の正解ラベルも、元の画像のラベルを同じ重みで混ぜ合わせるんだ。つまり、この例では「犬:0.7、猫:0.3」といった具合になるね。この手法を使うと、学習データを増やすだけでなく、過学習を防いだり、画像の中間の部分を識別できるようになったりする効果があるんだよ。
Mixupとは。
人工知能でよく使われる『混ぜ合わせ』という手法について説明します。この手法は、データを拡張する方法の一つで、二枚の絵を混ぜ合わせて新しい絵を作ります。この混ぜ合わせることで、データの偏りを減らし、あいまいな絵も識別できるようになり、結果として精度が向上します。
混ぜ合わせる新たな手法

近頃、絵を描くように画像を混ぜ合わせる斬新な手法が、画像認識の分野で話題を呼んでいます。この手法は「混ぜ合わせ」と呼ばれ、限られた学習データから新たなデータを人工的に作り出す技術である「データ拡張」の一種です。データ拡張は、いわば画家のパレットのように、限られた絵の具から様々な色を作り出すことで、より豊かな表現を可能にする技術です。「混ぜ合わせ」は、このデータ拡張の手法の中でも特に独創的で、二つの画像を異なる比率で重ね合わせることで、全く新しい画像を生成します。まるで絵の具を混ぜ合わせるように、二つの画像が滑らかに融合し、新しい画像が誕生するのです。
例えば、猫と犬の画像を混ぜ合わせると、猫のような犬、あるいは犬のような猫といった、今までにない画像が生成されます。この混ぜ合わせの比率は自在に変更可能で、猫の要素を多くしたり、犬の要素を多くしたりと、様々なバリエーションを生み出すことができます。このようにして生成された新たな画像は、元の画像には存在しない特徴を持つため、学習データの多様性を飛躍的に高めることができます。多様なデータで学習したモデルは、様々な変化に対応できる柔軟性を持ち、未知の画像に遭遇した際にも、高い精度で識別できるようになります。これは、様々な絵の具を混ぜ合わせて微妙な色彩を表現できるようになる画家の訓練にも似ています。多くの色を混ぜ合わせる経験を積むことで、画家の色彩表現はより豊かになり、見たことのない風景も正確に描写できるようになるでしょう。「混ぜ合わせ」も同様に、モデルに多様な画像を学習させることで、未知の画像への対応力を高め、画像認識技術の更なる進化を促すと期待されています。
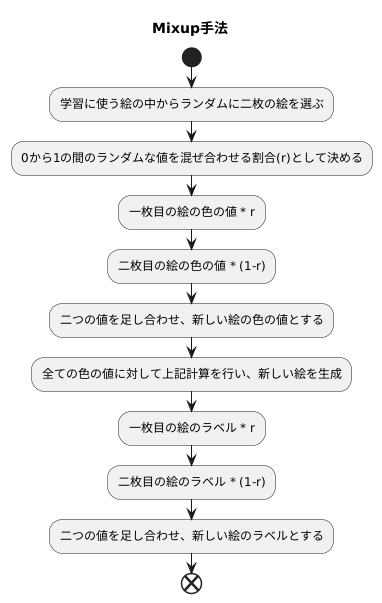
画像の合成方法

絵を混ぜ合わせる手法、ミックスアップについて説明します。ミックスアップは、二枚の絵をある割合で混ぜ合わせて新しい絵を作る方法です。まず、学習に使う絵の中からランダムに二枚の絵を選びます。次に、ゼロから一の間の数をランダムに決めます。これが混ぜ合わせる割合になります。この割合に基づいて、二枚の絵のそれぞれの色の値を混ぜ合わせ、新しい絵の色を作ります。
たとえば、混ぜ合わせる割合が0.7だとします。一枚目の絵の色の値に0.7を掛け、二枚目の絵の色の値に0.3を掛けます。そして、その二つの値を足し合わせると、新しい絵の色の値が決まります。この計算を絵の全ての色の値に対して行うことで、滑らかに混ぜ合わされた新しい絵が完成します。
混ぜ合わせる割合は、絵の種類を示すラベルにも使われます。新しい絵に付けるラベルも、元の二枚の絵のラベルを同じ割合で混ぜ合わせて作ります。例えば、一枚目の絵が「猫」で二枚目の絵が「犬」で、混ぜ合わせる割合が0.7だとします。新しい絵のラベルは「猫」と「犬」を混ぜ合わせたものになり、どちらの要素が強いのかを表すことができます。このように、絵とラベルの両方を混ぜ合わせることで、より効果的な学習が可能になります。この手法は、学習データを増やすだけでなく、学習の精度を向上させたり、過学習を防ぐ効果も期待できます。
正則化の効果

混ぜ合わせ学習は、訓練中に新たな学習事例を作り出す手法であり、モデルの性能向上に役立ちます。この手法は、二つの異なる学習事例とその正解ラベルを混ぜ合わせることで、新たな合成事例を生成します。例えば、犬の画像と猫の画像を混ぜ合わせることで、犬と猫の特徴を併せ持つ新たな画像が作られます。混ぜ合わせ学習は、特に画像認識において、モデルの過剰適合を抑える効果があります。過剰適合とは、訓練データの特徴を細部まで覚え込みすぎてしまい、未知のデータに対する予測精度が低下する現象です。混ぜ合わせ学習では、合成された画像を用いることで、モデルが訓練データの個々の特徴に過度に注目することを防ぎます。言い換えると、一つ一つの学習事例に固執するのではなく、様々な事例の特徴を総合的に学習するようになります。これにより、モデルは滑らかで汎化性能の高い決定境界を学習できます。決定境界とは、異なる分類を区別するための境界線のことです。滑らかな決定境界は、訓練データに含まれる細かい差異や特殊な例に左右されにくく、本質的な特徴に基づいて分類を行います。つまり、混ぜ合わせ学習は、モデルが訓練データの細かなノイズや例外的な特徴に惑わされにくくし、本質的な特徴を捉える能力を向上させます。その結果、未知のデータに対しても、より安定した信頼性の高い予測が可能になります。例えば、手書き数字認識において、数字の書き方に多少の癖や歪みがあっても、正しく認識できるようになります。これは、混ぜ合わせ学習によって、モデルが数字の形状の本質的な特徴を学習しているためです。このように、混ぜ合わせ学習は、モデルの汎化性能を高め、より頑健で実用的なモデルを構築する上で非常に有効な手法です。
| 手法 | 目的 | 効果 | メカニズム | 例 |
|---|---|---|---|---|
| 混ぜ合わせ学習 | 訓練中に新たな学習事例を作り出す | モデルの性能向上(過剰適合の抑制) | 二つの異なる学習事例とその正解ラベルを混ぜ合わせることで、新たな合成事例を生成 →モデルが訓練データの個々の特徴に過度に注目することを防ぎ、滑らかで汎化性能の高い決定境界を学習 |
犬の画像と猫の画像を混ぜ合わせることで、犬と猫の特徴を併せ持つ新たな画像を作る 手書き数字認識において、数字の書き方に多少の癖や歪みがあっても、正しく認識できる |
中間の識別能力

混ぜ合わせる手法を用いることで、学習モデルは絵のぼんやりとした見方も習得できるようになります。例えば、犬の絵と猫の絵を混ぜ合わせた新しい絵を考えると、学習モデルはこの混ぜ合わせた絵を「犬と猫の中間のようなもの」として捉えることを学びます。これは、従来の方法では難しかった、はっきりしない絵や複数の物が入り混じった絵に対しても、よりうまく対応できる見込みを示しています。
具体的に説明すると、従来の学習方法では、犬の絵は「犬」、猫の絵は「猫」と、それぞれ個別に学習させていました。しかし、現実世界では、必ずしも絵がはっきりと写っているとは限りません。例えば、遠くから撮った写真や、一部が隠れている物体など、ぼんやりとした絵を認識する必要も出てきます。混ぜ合わせる手法では、二つの絵の中間状態を作り出すことで、学習モデルに曖昧な状態を認識する能力を身につけさせることができます。
例えば、犬の絵と猫の絵を混ぜ合わせることで、「犬に近いもの」「猫に近いもの」「犬と猫の中間的なもの」など、様々な状態を学習させることができます。これにより、学習モデルは、一部分しか見えていない絵や、複数の物が重なっている絵に対しても、より正確に認識できるようになると考えられます。
また、複数の物が入り混じった絵に対しても、この手法は有効です。例えば、果物籠の絵の中に、りんご、バナナ、みかんが混ざって入っている場合、従来の方法では、それぞれの果物を個別に認識させる必要がありました。しかし、混ぜ合わせる手法を用いることで、果物同士が重なり合っている状態や、一部分しか見えていない状態でも、それぞれの果物を正しく認識できるようになります。
このぼんやりとした状態を認識する能力は、現実世界での複雑な絵認識作業において、非常に大切になるでしょう。例えば、自動運転車では、周囲の状況を正確に認識する必要がありますが、天候や照明条件などによって、絵の見え方が大きく変わる場合があります。このような状況でも、混ぜ合わせる手法を用いて学習させたモデルは、より正確に周囲の状況を認識し、安全な運転を支援することが期待されます。
精度向上への貢献

多くの視覚情報を用いた認識作業において、正確さを上げるための工夫が広く行われています。その中で、「混ぜ合わせ」という手法は、様々な課題において正確さを向上させるのに役立つことが分かっています。特に、画像を種類分けする作業では、従来の画像データを少し変化させる方法と比べて、この「混ぜ合わせ」を使うことで、より高い正確さが得られる場合が多く見られます。これは、「混ぜ合わせ」が持つ、学習データに過剰に適応してしまうことを防ぐ効果や、あいまいな画像に対しても適切に判断する能力などが複雑に影響し合い、見慣れない画像に対しても正しく認識できる力が高まるためだと考えられています。
この「混ぜ合わせ」は、二つの画像とそれに対応する正解ラベルを、それぞれ特定の比率で混ぜ合わせることで、新たな訓練データを作成します。例えば、猫の画像と犬の画像を混ぜ合わせることで、猫と犬の特徴を併せ持つ新たな画像が生成されます。この時、正解ラベルも同様に混ぜ合わされます。例えば、猫のラベルが「1」で犬のラベルが「0」の場合、混ぜ合わせ比率に応じて、例えば「0.7」や「0.3」といった新しいラベルが生成されます。
この手法は、計算に要する手間も比較的少ないため、多くの視覚情報を用いた認識作業で効果的な方法と言えるでしょう。さらに、二つの画像を単純に混ぜ合わせるだけでなく、混ぜ合わせ方や混ぜ合わせる画像の選び方などを工夫することで、より効果を高める試みもされています。近年では、この「混ぜ合わせ」を基にした様々な改良手法が提案されており、更なる正確さの向上を目指した研究が活発に行われています。これらの研究により、今後ますます視覚情報を用いた認識作業の精度が高まっていくことが期待されます。
| 手法 | 説明 | 効果 | 利点 | 課題と展望 |
|---|---|---|---|---|
| 混ぜ合わせ | 二つの画像と対応するラベルを特定の比率で混ぜ合わせ、新たな訓練データを作成する。 | 様々な視覚認識作業、特に画像分類において正確さを向上させる。過剰適応を防ぎ、あいまいな画像への対応能力を高める。 | 計算コストが比較的低い。 | 混ぜ合わせ方や混ぜ合わせる画像の選び方などの工夫により、更なる効果向上が期待される。近年、様々な改良手法が提案されており、研究が活発に行われている。 |
今後の展望

混ぜ合わせという手法は、図形を認識する分野で、新しい情報の増やし方として注目を集めています。この手法は、図形だけでなく、言葉や音声を扱う分野にも応用できる可能性を秘めており、今後の発展に大きな期待が寄せられています。
たとえば、言葉の学習では、二つの異なる文章を混ぜ合わせることで、新しい表現方法を生み出す可能性があります。「今日は晴れです」と「明日は雨です」という二つの文章を混ぜ合わせることで、「今日は晴れ時々曇りで、明日は雨です」のような、より複雑で自然な表現を学習できるかもしれません。音声認識においても、異なる話者の音声を混ぜ合わせることで、雑音に強い音声認識モデルの構築に役立つ可能性があります。
さらに、混ぜ合わせの手法そのものについても、より深く掘り下げた研究が必要です。混ぜ合わせの割合や、混ぜ合わせる対象の選び方など、より効果的な方法を見つけることで、学習の効率を高めることができると考えられます。例えば、似た性質を持つデータを混ぜ合わせる方が、全く異なるデータを混ぜ合わせるよりも効果的である可能性があります。また、混ぜ合わせの割合を学習の段階に応じて調整することで、より精度の高いモデルを作ることができるかもしれません。
混ぜ合わせという手法は、様々な機械学習の分野で、学習の効率と精度を向上させる可能性を秘めた、大変重要な技術です。今後の研究により、この手法がさらに進化し、様々な分野で応用されることで、人工知能技術の発展に大きく貢献することが期待されます。
| 分野 | 例 | 効果 |
|---|---|---|
| 図形認識 | – | 新しい情報の増やし方 |
| 言葉の学習 | 「今日は晴れです」と「明日は雨です」→「今日は晴れ時々曇りで、明日は雨です」 | 新しい表現方法を生み出す |
| 音声認識 | 異なる話者の音声を混ぜ合わせる | 雑音に強い音声認識モデルの構築 |
| 混ぜ合わせ手法そのもの | 混ぜ合わせの割合や、混ぜ合わせる対象の選び方 | 学習の効率を高める、より精度の高いモデルの作成 |