
RNNエンコーダ・デコーダ入門

AIを知りたい
先生、「RNN Encoder-Decoder」って、入力と出力が両方とも時間的に変化するデータの場合に使うんですよね?でも、具体的にどんなふうに動くのか、よくわからないんです。

AIエンジニア
そうだね。例えば、日本語を英語に翻訳する機械を考えてみよう。日本語の文章が入力で、英語の文章が出力になる。どちらも単語の並びで、時間の流れに沿って処理していく必要があるよね。これが「入力と出力が両方とも時間的に変化するデータ」の一例だよ。RNN Encoder-Decoderは、このような場合に使えるんだ。
AIを知りたい
なるほど。翻訳の例だとイメージしやすいです。エンコーダとデコーダって、それぞれどんな役割をするんですか?
AIエンジニア
エンコーダは入力された日本語の文章を、意味を圧縮した情報に変換する役割だよ。そして、デコーダはこの圧縮された情報を受け取って、英語の文章を一つずつ生成していくんだ。デコーダは、一つ前の単語を参考にしながら、次の単語を予測していくんだよ。
RNN Encoder-Decoderとは。
人工知能で使われる『RNN符号化器・復号化器』について説明します。RNN符号化器・復号化器は、入力と出力がどちらも時間とともに変化するデータの場合に使われる方法です。この方法は、符号化器と復号化器と呼ばれる二つのRNNを使います。符号化器は入力されたデータを処理して暗号のような形に変換し、復号化器はこの暗号を元のデータの形に戻します。出力も時間とともに変化していくため、復号化器は一度出力したものを次の入力として再び処理します。
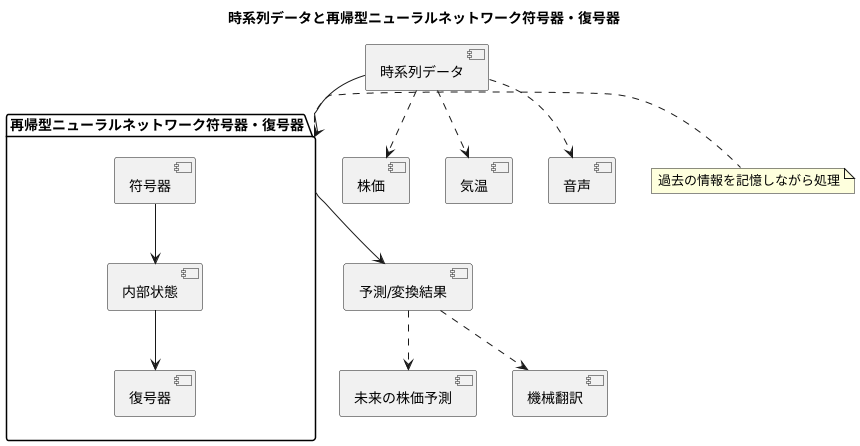
時系列データの処理

近ごろ、様々な分野で情報を集めて分析することが盛んになってきており、その中でも、時間の流れに沿って記録されたデータである時系列データの重要性が特に高まっています。株価の上がり下がりや、日々の気温の変化、録音された音声など、私たちの身の回りには、時間とともに変化するデータが溢れています。これらの時系列データをうまく扱うことで、未来の出来事を予測したり、隠れた規則性を見つけ出したりすることができるため、様々な分野で役に立つのです。
時系列データを扱うための強力な方法として、「再帰型ニューラルネットワーク符号器・復号器」というものがあります。これは、ある時系列データを入力として受け取り、別の時系列データに変換して出力する技術です。例えば、日本語の文章を入力すると、英語の文章が出力される機械翻訳や、過去の株価の情報から未来の株価を予測するといった用途に利用できます。
これまでの技術では、時系列データの中に潜む複雑な関係性を捉えるのが難しかったのですが、この「再帰型ニューラルネットワーク符号器・復号器」は、過去の情報を記憶しながら処理を進める特殊な仕組みを持っているため、この問題を解決することができます。これは、まるで人間の脳のように、過去の出来事を覚えておきながら、現在の状況を判断するようなものです。
具体的には、「符号器」と呼ばれる部分が、入力された時系列データを、特徴をコンパクトにまとめた情報に変換します。そして、「復号器」と呼ばれる部分が、このまとめられた情報をもとに、別の時系列データを出力します。このように、二つの部分を組み合わせることで、より正確な予測や変換が可能になるのです。例えば、機械翻訳では、日本語の文章を「符号器」で意味を表す情報に変換し、「復号器」でその情報を基に英語の文章を作り出します。株価予測では、過去の株価の変動を「符号器」で分析し、「復号器」で未来の株価の動きを予測します。このように、「再帰型ニューラルネットワーク符号器・復号器」は、時系列データの複雑な関係性を捉え、様々な分野で役立つ情報を提供してくれるのです。
エンコーダの役割

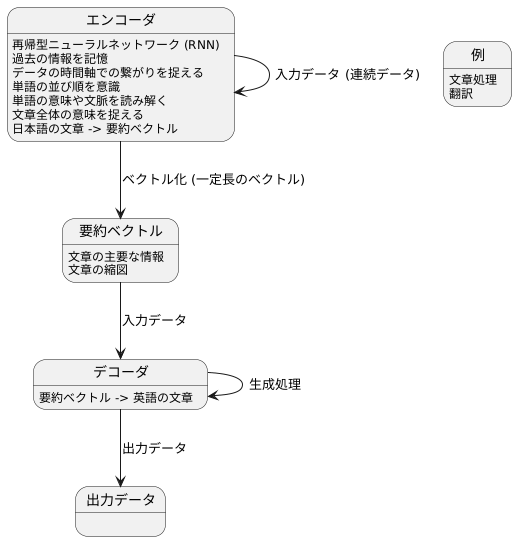
エンコーダは、与えられた連続したデータを、一定の長さのベクトルに変換する重要な役割を担います。このベクトルは、入力データの全体像をギュッと凝縮したもので、いわばデータのエッセンスを抽出したものと言えます。このエッセンスは、デコーダという別の処理装置にとって、非常に重要な情報源となります。
エンコーダは、情報を順番に処理していく特別な仕組み(再帰型ニューラルネットワーク)を用いて、入力データを一つずつ丁寧に処理します。この仕組みは、過去の情報を記憶する能力に長けており、データの長い時間軸での繋がりを捉えることができます。例えば、文章を扱う場合を考えてみましょう。エンコーダは、単語の並び順を意識しながら、それぞれの単語の意味や文脈を読み解いていきます。「青い」「空」という二つの単語が並んでいれば、「空が青い」という状況を理解し、「青い」「鳥」であれば、「鳥の色が青い」と理解するといった具合です。このようにして、文章全体の意味を捉え、最終的に文章の要約となるベクトルを作り出します。
この要約ベクトルには、文章の主要な情報がぎゅっと詰め込まれており、いわば文章の縮図のようなものです。デコーダは、この縮図を受け取って、出力データを作成します。例えば、翻訳であれば、日本語の文章をエンコーダで処理して要約ベクトルを作り、それをデコーダに渡すことで、英語の文章を生成するといった具合です。エンコーダは、データの全体像を捉え、それを簡潔な表現に変換することで、デコーダの処理を助ける重要な役割を果たしているのです。
デコーダの働き

翻訳機や文章の要約を作るものなど、様々な場面で活躍する仕組みの一つに「デコーダ」というものがあります。デコーダは、エンコーダと呼ばれる別の仕組みと連携して情報を処理します。エンコーダが文章などのデータの全体像を捉えた「要約ベクトル」を作成した後、デコーダはこの要約ベクトルを受け取って、具体的な形に変換します。
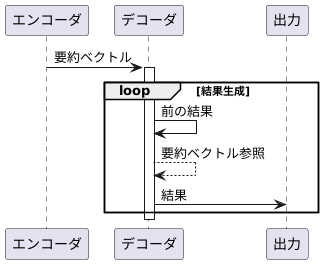
デコーダは、過去の情報を踏まえながら、一つずつ順番に結果を作り出していきます。この働きを実現するために、「再帰型ニューラルネットワーク」と呼ばれる仕組みがよく使われます。この仕組みは、過去の情報を記憶しながら、新たな情報を受け取り、結果を生成するという特徴を持っています。エンコーダから受け取った要約ベクトルは、デコーダが処理を始める際の最初の状態として設定されます。そして、デコーダはこの状態に基づいて最初の結果を生成します。
次に、デコーダは自分が生成した結果を、次の処理の入力として使います。つまり、前の段階で得られた結果を踏まえて、さらに新しい結果を作り出すということです。この処理を繰り返すことで、デコーダは最終的に一連の結果、例えば翻訳された文章や要約された文章などを生成します。
デコーダが結果を作り出す過程では、エンコーダから受け取った要約ベクトルが常に参照されます。これにより、最終的な結果は、入力されたデータ全体の文脈を反映したものになります。例えば、翻訳の作業では、デコーダは要約ベクトルに含まれる情報に基づいて、翻訳先の言葉で適切な単語を選び、文章を作り上げていきます。このように、デコーダはエンコーダと協力して、複雑な情報処理を可能にしています。
相互の連携

情報を伝える人と受け取る人、両方の働きがあって初めて、話は伝わります。これと同じように、RNNエンコーダ・デコーダも、符号化するエンコーダと解読するデコーダが協力して初めて、時系列データの変換をうまく行うことができます。
エンコーダは、入力された時系列データの全体的な意味を捉え、それを要約ベクトルと呼ばれる、コンパクトな情報のかたまりに変換します。この作業は、まるで長い文章を読んで要点をまとめるようなものです。要約ベクトルは、入力データの持つ重要な特徴を凝縮した、いわば情報のエッセンスと言えるでしょう。
次に、デコーダはエンコーダから受け取ったこの要約ベクトルを基に、出力データを作り出します。これは、要点を参考にしながら、元の文章とは異なる表現で内容を伝えるようなものです。エンコーダが作った要約ベクトルが詳細で正確であればあるほど、デコーダは元のデータの内容をより正確に再現できます。
エンコーダとデコーダは、この要約ベクトルを通して繋がっているため、入力データの長さには縛られません。入力データがどれだけ長くても、エンコーダはそれを固定長の要約ベクトルに変換します。そして、デコーダはこの固定長のベクトルから、出力データの長さに合わせて新しい時系列データを生成します。これにより、例えば長い文章を短い要約にしたり、異なる長さの文章を相互に変換したりすることが可能になります。
このように、エンコーダとデコーダが要約ベクトルを介して連携することで、RNNエンコーダ・デコーダは柔軟に時系列データの変換を扱うことができるのです。

応用例

繰り返し使える部品のようなもの(再帰型ニューラルネットワーク)を組み合わせた符号化器と復号化器は、様々な場面で役に立っています。これは、まるで暗号のように情報を一度別の形に変換し、そしてまた元の形に戻すような仕組みです。
例えば、外国語を私たちの言葉に置き換える機械翻訳では、元の言葉が符号化器で一度情報のかたまりに変えられ、復号化器で私たちの言葉に置き換えられます。まるで、通訳者が一度内容を理解してから別の言葉で伝え直すようなものです。
また、人の声を文字に変換する音声認識もこの仕組みを使っています。音の波形が符号化器で分析され、情報のかたまりに変換された後、復号化器によって文字へと変換されます。まるで、速記者が音を聞いて文字に書き起こす作業のようです。
長い文章を短くまとめる文章要約も得意な仕事です。長い文章が符号化器で重要な情報だけを抜き出した形に変換され、復号化器で短い文章として出力されます。まるで、要点を絞って簡潔に説明するようなものです。
人と話す機械を作る対話システムもこの仕組みを使います。私たちの言葉が符号化器で意味を理解できる形に変換され、復号化器で適切な返答が生成されます。まるで、人と人が会話するように、自然なやり取りができるように工夫されています。
これらの技術は、より深く学ぶ技術と組み合わせることで、さらに精度が向上すると期待されています。まるで、経験を積むことでより正確で自然な言葉遣いを身につけていくように、技術も進化していくのです。
| タスク | 符号化器の役割 | 復号化器の役割 | 例え |
|---|---|---|---|
| 機械翻訳 | 元の言葉を情報のかたまりに変換 | 情報のかたまりを別の言葉に変換 | 通訳者 |
| 音声認識 | 音の波形を分析し、情報のかたまりに変換 | 情報のかたまりを文字に変換 | 速記者 |
| 文章要約 | 長い文章から重要な情報だけを抜き出す | 抜き出した情報を短い文章に変換 | 要点を絞る |
| 対話システム | 人の言葉を意味を理解できる形に変換 | 理解した意味に基づき適切な返答を生成 | 人と人との会話 |
今後の展望

この技術は、既に様々な分野で成果を上げていますが、更なる発展が期待されています。今後の展望としては、複雑な時系列データへの対応や学習効率の改善といった課題に取り組むことで、性能の向上が見込まれます。
まず、複雑な時系列データへの対応については、現在のモデルでは捉えきれない複雑なパターンを学習できるよう、モデルの改良が必要です。例えば、データの時間的な依存関係をより深く理解できるような構造を取り入れることで、より精度の高い分析が可能になると考えられます。また、学習効率の改善も重要な課題です。現在のモデルは学習に膨大な時間と計算資源を必要とするため、より効率的な学習手法の開発が求められます。これにより、より多くのデータを用いた学習や、より複雑なモデルの学習が可能となり、更なる性能向上が期待できます。
さらに、近年注目されている注目機構を導入することで、より精度の高い変換を実現できる可能性があります。注目機構は、入力データのどの部分に注目すべきかを自動的に判断する仕組みです。これにより、入力データと出力データの関係性をより正確に把握し、不要な情報の影響を抑えながら、重要な情報に焦点を当てた処理が可能になります。
これらの技術開発が進展することで、この技術の応用範囲は更に広がると期待されます。特に、膨大なデータの分析や複雑な予測といったタスクへの応用は、様々な分野で革新的な成果をもたらす可能性を秘めています。例えば、経済予測や医療診断、自然災害の予測など、社会的に重要な課題の解決に貢献することが期待されます。これらの技術の更なる発展により、私たちの生活はより豊かで安全なものになるでしょう。
| 課題 | 対策 | 期待される効果 |
|---|---|---|
| 複雑な時系列データへの対応 | ・モデルの改良 ・データの時間的な依存関係をより深く理解できる構造を取り入れる |
・より精度の高い分析 |
| 学習効率の改善 | ・より効率的な学習手法の開発 | ・より多くのデータを用いた学習 ・より複雑なモデルの学習 ・更なる性能向上 |
| 精度の向上 | ・注目機構の導入 ・入力データのどの部分に注目すべきかを自動的に判断する仕組みの導入 |
・より精度の高い変換 ・入力データと出力データの関係性をより正確に把握 ・不要な情報の影響を抑える ・重要な情報に焦点を当てた処理 |