
デュエリングネットワーク:強化学習の進化

AIを知りたい
先生、デュエリングネットワークって、普通の強化学習と何が違うんですか?

AIエンジニア
いい質問だね。普通の強化学習、例えばDQNだと、ある状態である行動をとった時の価値(状態行動価値Q)を直接学習するよね。デュエリングネットワークでは、状態価値VとアドバンテージAという2つの値を別々に学習して、それを組み合わせてQを求めるんだ。
AIを知りたい
状態価値VとアドバンテージA…ですか?難しそうですね。もう少し詳しく教えてもらえますか?
AIエンジニア
もちろん。状態価値Vはある状態にいることの良さ、つまりどれだけ有利な状態かを表す値だよ。アドバンテージAはある状態である行動をとることの、他の行動と比べてどれだけ有利かを表す値なんだ。だから、ある行動の価値Qは「その状態にいることの良さV」+「その行動をとることの良さA」で求めることができるんだよ。
デュエリングネットワークとは。
人工知能の分野で使われる『決闘ネットワーク』という用語について説明します。決闘ネットワークは、強化学習におけるネットワークの仕組みをより良くしたモデルです。従来のDQNと呼ばれる手法では、ある状態である行動をとったときの価値(状態行動価値Q)だけを学習していました。一方、決闘ネットワークでは状態の価値(状態価値V)と、状態行動価値Qから状態価値Vを引いた値である有利さ(アドバンテージA)を学習します。
行動価値と状態価値の分離

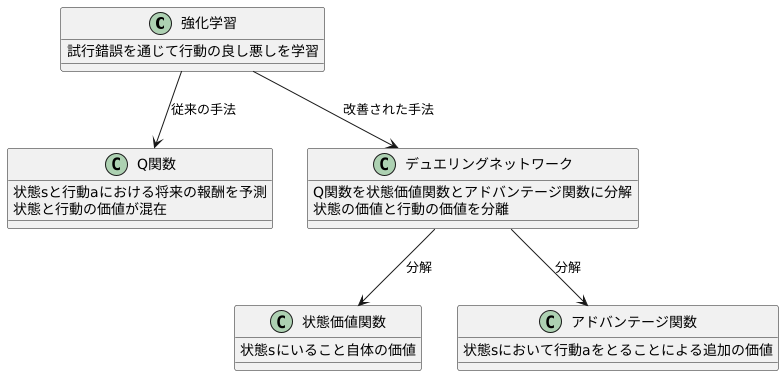
強化学習とは、試行錯誤を通じて行動の良し悪しを学習する枠組みのことです。この学習において、行動の価値を適切に評価することは非常に重要です。従来の深層強化学習の手法では、状態行動価値関数、よくQ関数と呼ばれるものが用いられてきました。Q関数は、ある状態において、ある行動をとったときに、将来どれだけの報酬が得られるかを予測する関数です。
しかし、Q関数を直接学習させる方法には、状態と行動の価値が混在しているという問題がありました。例えば、ある状態自体が非常に良い状態であれば、その状態においてどのような行動をとっても、高い報酬が期待できます。逆に、ある状態自体が非常に悪い状態であれば、どんな行動をとっても良い報酬は期待できません。このような状況では、Q関数は状態の価値を反映してしまい、個々の行動の良し悪しを適切に評価することが難しくなります。
この問題を解決するために、デュエリングネットワークという手法が提案されました。デュエリングネットワークでは、Q関数を状態価値関数とアドバンテージ関数という二つの関数に分解します。状態価値関数は、ある状態にいること自体の価値を表します。一方、アドバンテージ関数は、ある状態において、ある行動をとることによる追加の価値、つまり他の行動と比べてどれくらい優れているかを表します。
具体的には、ある状態における各行動のアドバンテージ関数の値を計算し、そこから平均値を引いたものを用います。こうすることで、状態の価値と行動の価値を分離することができます。状態が良いか悪いかに関わらず、それぞれの行動の相対的な価値を評価できるようになるため、より効率的な学習が可能になります。結果として、複雑な環境においても、より適切な行動を選択できるようになります。
ネットワーク構造の改良

従来の強化学習手法であるディープ・キュー・ネットワーク(DQN)は、ゲーム画面のような状態を入力として受け取り、各行動に対する価値(Q値)を出力します。このQ値に基づいて、行動の選択を行います。しかし、DQNは状態と行動の組み合わせごとにQ値を学習するため、学習の効率が悪くなる場合がありました。
そこで、デュエリングネットワークと呼ばれる改良手法が考案されました。デュエリングネットワーク最大の特徴は、その名の通り決闘のように二つの流れを持つネットワーク構造にあります。具体的には、ネットワークの中間層で二つの流れに分岐します。一つ目の流れは、現在の状態がどれだけ良いかを表す状態価値を推定します。例えば、ゲームにおいて自機が有利な位置にいる場合、状態価値は高くなります。もう一つの流れは、特定の行動をとることによる利得、つまりアドバンテージ関数を推定します。同じ状態でも、攻撃する、防御する、逃げるといったそれぞれの行動で、得られる利得は異なります。
デュエリングネットワークでは、最終的にこの状態価値とアドバンテージ関数を組み合わせることで、Q値を計算します。この構造により、状態価値とアドバンテージ関数を別々に学習することが可能になります。つまり、ある状態においてどの行動をとっても価値が変わらない場合、状態価値だけを学習すれば良くなります。これは、全ての行動の価値を個別に学習する必要がないため、学習の効率向上に繋がります。また、状態価値とアドバンテージ関数を分離することで、それぞれの推定精度が向上し、より正確なQ値の推定にも繋がります。結果として、デュエリングネットワークはDQNに比べて、より効率的で正確な学習を実現できるのです。
学習の安定化と効率化

学ぶことの安定性と効率を高めるためには、様々な工夫が凝らされています。その一つに、戦い合う構造を持つ仕組みがあります。この仕組みは、学ぶ上での安定性と効率性を高める効果があります。従来の方法では、状況と行動の組み合わせごとに値を学ぶ必要がありました。そのため、学ぶ負担が大きくなってしまい、多くの時間を必要としていました。
しかし、戦い合う構造を持つ仕組みでは、状況の価値と行動の有利さを分けて学ぶことができます。そのため、学ぶ負担が軽くなり、効率的に学ぶことができます。特に、状況の価値があまり変わらない場合は、行動の有利さだけを更新すれば良いため、学ぶ時間を大幅に短縮できます。
この仕組みは、学ぶことの安定性にも貢献します。状況の価値は、周りの状況によって大きく変わる可能性がありますが、行動の有利さは比較的安定している場合が多いです。そのため、状況の価値と行動の有利さを分けて学ぶことで、学ぶ過程での雑音の影響を少なくし、安定した学習を行うことができます。
例えるなら、迷路を解く場面を想像してみてください。従来の方法では、迷路全体の様子を把握しながら、一つ一つの分かれ道で進む方向を決めていました。しかし、戦い合う構造を持つ仕組みでは、まず迷路全体の価値を大まかに把握し、次に各分かれ道での有利さを判断します。全体像を把握することで、どの道が有利なのかが分かりやすくなり、より早く、そして正確にゴールに辿り着くことができます。このように、戦い合う構造を持つ仕組みは、様々な場面で学ぶことの安定性と効率性を高めることができると期待されています。
| 項目 | 従来の方法 | 戦い合う構造を持つ仕組み |
|---|---|---|
| 学習内容 | 状況と行動の組み合わせごとの値 | 状況の価値と行動の有利さを分けて学習 |
| 学習負担 | 大きい | 小さい |
| 学習効率 | 低い | 高い |
| 学習時間 | 長い | 短い |
| 学習の安定性 | 低い | 高い |
| 雑音の影響 | 大きい | 小さい |
| 例 | 迷路全体の様子を把握しながら、一つ一つの分かれ道で進む方向を決める | まず迷路全体の価値を大まかに把握し、次に各分かれ道での有利さを判断する |
様々な応用への可能性

勝負する仕組みを取り入れた学習方法である、デュエリングネットワークは、遊びの対戦だけでなく、機械の操作や資源のやりくりなど、様々な学びの課題に役立てることができます。 この方法は、物事の状態の価値と、そこで行う行動の良し悪しを分けて考えることで、より賢い判断を可能にします。
例えば、機械の操作を考えてみましょう。ロボットアームが物を掴む動作を学習させる場合、デュエリングネットワークは、アームの位置や角度といった現在の状態の価値と、次にどんな動きをすれば良いのかという行動の価値を別々に評価します。 これにより、掴む対象物までの距離や障害物の有無といった状況に応じて、最適な行動を選択することができます。従来の方法では、状態と行動をまとめて評価していたため、複雑な状況での判断が難しかったのですが、デュエリングネットワークは、状態と行動を切り分けることで、より正確で効率的な学習を実現します。
資源のやりくりについても同様です。限られた予算をどのように配分すれば最大の利益を得られるか、あるいは限られた時間の中でどのように作業を進めれば効率的かを考える際に、デュエリングネットワークは力を発揮します。現在の資源の状況を評価するだけでなく、それぞれの選択肢の価値を比較することで、最良の戦略を導き出すことができます。 例えば、新しい工場を建設する、既存の設備を改良する、あるいは広告に投資するといった選択肢がある場合、デュエリングネットワークは、それぞれの行動の価値を予測し、限られた資源を最大限に活用するための最適な配分方法を学習します。
このように、デュエリングネットワークは、様々な状況における意思決定を支援する強力な手法であり、学びの分野において、今後ますます重要な技術として発展していくことが期待されています。
| 分野 | 従来の方法 | デュエリングネットワーク | 利点 |
|---|---|---|---|
| 機械操作 (ロボットアーム) | 状態と行動をまとめて評価 | 状態の価値と行動の価値を分けて評価 (例: アームの位置・角度と次の動きの良し悪しを別々に評価) |
複雑な状況での最適な行動選択が可能 |
| 資源のやりくり (予算配分) | – | 資源状況の評価 + 各選択肢の価値比較 (例: 工場建設、設備改良、広告投資の価値を予測し最適配分) |
限られた資源を最大限に活用する戦略導出 |
将来の展望

勝負を挑む網の仕組みは、試行錯誤を通じて学ぶ計算技術において大きな進歩と言えるでしょう。しかし、より良いものにするための工夫はまだまだ必要です。例えば、ものの価値を見極める働きと、それぞれの行動がもたらす利点を計算する働きを、どううまく組み合わせるか、また、網そのものの形をどう整えるかなど、探求すべき点は数多く残されています。
勝負を挑む網の仕組みは、それ単体で使うだけでなく、他の試行錯誤学習法と組み合わせることで、更に効果を高めることが見込めます。例えば、これまで試行錯誤学習が苦手としてきた、複雑で変化の多い状況にも対応できるようになるかもしれません。今後の探求によって、勝負を挑む網の仕組みは更に磨きがかけられ、試行錯誤学習が活躍する場も広がっていくでしょう。
複雑な課題を解くことや、より高度な学習方法と組み合わせることなど、勝負を挑む網の仕組みの未来には、大きな可能性が秘められています。具体的には、自動運転技術やロボット制御、資源管理、ゲームプレイなど、様々な分野での応用が期待されています。勝負を挑む網の仕組みが進化することで、これらの分野で画期的な成果が生まれる可能性も秘めているのです。より良い判断を下し、複雑な問題にもうまく対応できるようになれば、私たちの生活は更に豊かになるでしょう。今後の発展に大いに期待したいところです。
| 項目 | 内容 |
|---|---|
| 概要 | 勝負を挑む網の仕組みは試行錯誤を通じて学ぶ計算技術において大きな進歩だが、更なる工夫が必要。 |
| 課題 | ものの価値を見極める働きと行動の利点計算の組み合わせ、網の形状の最適化。 |
| 他の学習法との組み合わせ | 他の試行錯誤学習法と組み合わせることで、複雑で変化の多い状況への対応が可能になる。 |
| 将来の可能性 | 複雑な課題の解決、高度な学習方法との組み合わせ。 |
| 応用分野 | 自動運転技術、ロボット制御、資源管理、ゲームプレイなど。 |
| 期待される効果 | より良い判断、複雑な問題への対応、生活の向上。 |