デュエリングネットワーク:強化学習の進化

AIを知りたい
先生、デュエリングネットワークって、普通の強化学習と何が違うんですか?

AIエンジニア
良い質問だね。通常の強化学習、例えばDQNでは、ある状態である行動をとった時の価値(状態行動価値Q)を学習するよね。デュエリングネットワークでは、状態価値VとアドバンテージAという2つの値を学習するんだよ。
AIを知りたい
状態価値VとアドバンテージA…ですか?二つも学習する必要があるんですか?
AIエンジニア
そうなんだ。状態価値Vはある状態にいることの価値を表していて、アドバンテージAはある状態で特定の行動をとることによる価値の差を表す。QはVとAを組み合わせることで計算できる。別々に学習することで、より正確な価値の推定ができる場合があるんだよ。
デュエリングネットワークとは。
人工知能の分野で使われる『決闘ネットワーク』という用語について説明します。決闘ネットワークは、強化学習におけるネットワークの仕組みをより良くしたモデルです。従来のDQNという手法では、ある状態である行動をとったときの価値(状態行動価値Q)だけを学習していました。一方、決闘ネットワークでは状態の価値(状態価値V)と、状態行動価値Qから状態価値Vを引いた値である有利さ(アドバンテージA)を学習します。
はじめに

この資料は、強化学習という学習方法の入門書です。強化学習とは、機械がまるで人間のように試行錯誤を繰り返しながら、目的を達成するための最適な行動を学ぶ仕組みのことです。近年、この強化学習に深層学習という技術を組み合わせた深層強化学習が大きな注目を集めています。深層学習の力を借りることで、強化学習は様々な分野で目覚ましい成果を上げています。
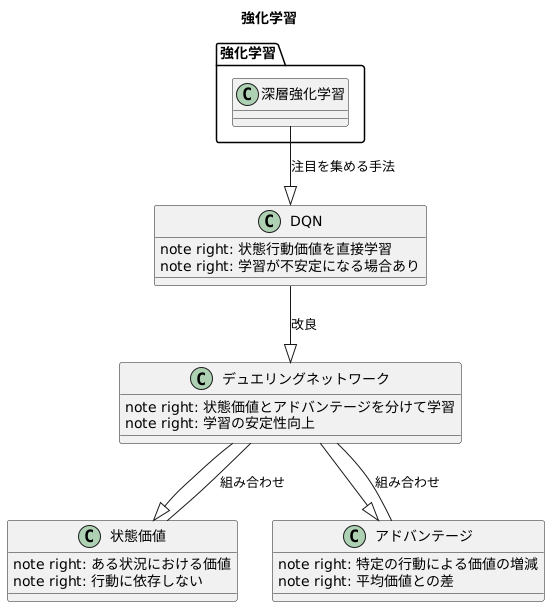
深層強化学習の中でも、特に有名な手法の一つにDQN(深層Q学習)があります。DQNは、状態行動価値と呼ばれる、ある状況である行動をとった時の価値を予測することで学習を進めます。しかし、この状態行動価値を直接学習しようとすると、学習の過程が不安定になり、うまく学習できない場合がありました。
そこで登場したのが、DQNを改良したデュエリングネットワークという手法です。デュエリングネットワークは、状態行動価値を直接学習するのではなく、状態価値とアドバンテージという二つの要素に分けて学習します。状態価値とは、ある状況における価値を表すもので、どんな行動をとるかに関係なく決まります。一方、アドバンテージはある状況において特定の行動をとることによる価値の増減を表します。つまり、ある行動をとった時の価値が、その状況における平均的な価値と比べてどれくらい良いか悪いかを示すものです。
デュエリングネットワークは、この二つの要素を別々に学習し、最後に組み合わせて状態行動価値を計算します。こうすることで、学習の安定性が向上し、DQNよりも効率的に学習を進めることが可能になります。この資料では、これからデュエリングネットワークの仕組みや利点について詳しく解説していきます。
従来手法の問題点

これまでのやり方では、ある状況での行動の価値を直接学習していました。これは、ある状況でどの行動をとればどれだけの良い結果が得られるかを学ぶということです。しかし、ある状況でどの行動をとっても結果が変わらない場合、学習が不安定になることがあります。
たとえば、迷路の行き止まりを考えてみましょう。行き止まりでは、右に行こうが左に行こうが、前に進もうが、状況は変わりません。どの行動をとっても、行き止まりから抜け出せないのです。このような状況では、行動の価値を学ぶための計算に、偶然の要素が大きく影響してしまい、学習の効率が悪くなります。ちょうど、たくさんの雑音の中で話を聞き取ろうとするようなものです。雑音が大きすぎると、何を言っているのか分からなくなってしまいます。
また、選べる行動の種類が多い場合も問題です。たとえば、100個の選択肢があるとき、それぞれの選択肢の価値を正確に見極めるのは大変です。それぞれの選択肢を試すのに時間がかかるだけでなく、少しの誤差が大きな違いを生んでしまう可能性があります。100個の選択肢それぞれに、わずかに異なる価値があるとします。このわずかな違いを正確に学ぶのは難しく、学習が不安定になる原因となります。
さらに、価値がほとんど変わらない行動が複数ある場合も、学習が難しくなります。たとえば、99個の選択肢が全く同じ価値で、1つの選択肢だけがわずかに良い価値を持っているとします。この場合、99個の選択肢の中から、わずかに良い選択肢を見つけ出すのは困難です。まるで、砂浜から一粒の金を探し出すようなものです。このように、従来の方法は、状況によっては学習が不安定になり、効率が悪くなるという問題を抱えていました。
| 問題点 | 具体例 | 例え |
|---|---|---|
| 結果が変わらない場合、学習が不安定になる | 迷路の行き止まり | 雑音の中で話を聞く |
| 選択肢が多い場合、学習が不安定になる | 100個の選択肢 | わずかな違いを見分ける |
| 価値がほとんど変わらない行動が多い場合、学習が難しい | 99個の同じ価値の選択肢と1つの良い選択肢 | 砂浜から金を探す |
デュエリングネットワークの仕組み

デュエリングネットワークは、深層強化学習でよく使われるDQN(ディープ・キュー・ネットワーク)を改良した手法です。DQNは、ゲームのような状況で、どの行動をとるのが一番良いかを学習しますが、状況によっては学習が不安定になったり、効率が悪くなったりする問題がありました。この問題を解決するために考えられたのがデュエリングネットワークです。
デュエリングネットワークの最大の特徴は、ネットワークの出力を「状態価値」と「有利さ」の2つに分けて学習する点です。「状態価値」はある場面における、状態そのものの価値を表します。例えば、迷路ゲームでゴールに近いほど価値が高く、遠いほど価値が低いと考えられます。これは、どの行動をとるかに関係なく、その場所にいること自体につけられる価値です。一方、「有利さ」はある場面で特定の行動をとることによる価値の増減を表します。例えば、迷路の分かれ道で、右に行くのと左に行くのとでは、ゴールに近づく方向に進んだ方が有利さは高く、遠ざかる方向に進んだ方が有利さは低くなります。
DQNでは、それぞれの行動に対する価値を直接学習していましたが、デュエリングネットワークでは状態価値と有利さを別々に学習し、後で組み合わせることで、各行動の価値を計算します。このようにすることで、状態によらず一定の価値を持つ部分と、行動によって価値が変化する部分を分けて学習できるため、学習の安定性と効率が向上します。
具体例として、迷路の行き止まりを考えてみましょう。行き止まりでは、どの行動をとっても、次に進めるわけではなく、状態価値は変わりません。しかし、引き返す行動と、壁に進む行動とでは、明らかに引き返す方が良いでしょう。DQNでは、行き止まりでの各行動の価値をそれぞれ学習する必要がありますが、デュエリングネットワークでは、状態価値はどの行動でも同じであることを学習し、有利さの部分で引き返す行動の価値が高いことを学習します。このように、状態価値と有利さを分けて学習することで、より効率的に学習を進めることが可能になります。

学習の安定化

学習を安定させることは、人工知能の分野において非常に重要です。 学習が不安定だと、せっかく学習してもその成果が信頼できないものになってしまいます。そこで、この問題に取り組むための手法として、デュエリングネットワークという方法が注目されています。
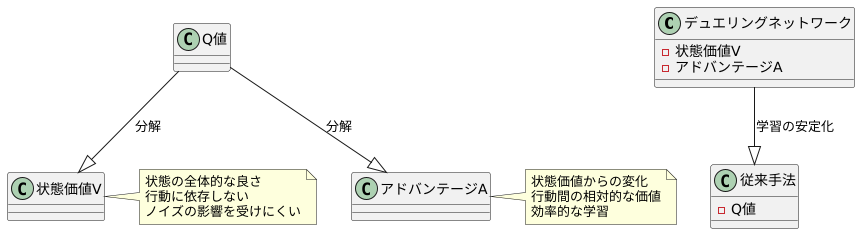
デュエリングネットワークは、状態の価値を表す部分(状態価値V)と、各行動による価値の変化を表す部分(アドバンテージA)を分けて学習します。 従来の方法では、状態と行動を組み合わせた価値(Q値)を直接学習していましたが、デュエリングネットワークではこのQ値を状態価値VとアドバンテージAに分解することで、学習の安定化を図っています。
状態価値Vは、ある状態が全体的にどれくらい良い状態かを表します。 例えば、迷路でゴールに近い状態は高い状態価値を持ち、遠い状態は低い状態価値を持ちます。この状態価値は、個々の行動に依存しないため、学習データに含まれる多少のばらつき(ノイズ)の影響を受けにくく、安定して学習できます。
一方、アドバンテージAは、ある状態である行動をとった場合に、状態価値Vからどれくらい価値が変化するかを表します。 例えば、迷路でゴールに近い状態では、ゴールに向かう行動は高いアドバンテージを持ち、ゴールから遠ざかる行動は低いアドバンテージを持ちます。アドバンテージは行動間の相対的な価値を表すため、各行動の価値を効率的に学習できます。
このように、状態価値VとアドバンテージAを分けて学習することで、デュエリングネットワークは従来の方法よりも安定した学習を実現し、より良い結果を得ることができます。 特に、行動の種類が多い場合でも、各行動の価値を効率よく学習できるため、複雑な問題にも対応できます。この手法は、ゲームプレイやロボット制御など、様々な分野での応用が期待されています。
適用事例

勝負する仕組みを持つ網の目は、様々な学びの場に役立っています。まるで、人と人が教え合い競い合うように、この仕組みは機械にも学び方を教えてくれます。例えば、遊びのように楽しむゲームや、機械の動きを細かく指示する制御、限りある資源をうまく使う方法など、幅広い分野で成果を上げています。
特に、テレビゲームのような複雑な状況では、この仕組みを使うことで、従来の方法よりも高い得点が出せることが分かっています。画面の中の敵やアイテム、背景など、たくさんの情報の中からどれが大切かを見分けるのが上手なのです。例えば、敵が迫っているときは戦う行動を選び、アイテムがあるときは拾う行動を選びます。状況に応じて適切な行動を選ぶことで、より良い結果を得られるようになります。
また、機械の動きを滑らかにしたり、無駄なく動かしたりするのにも役立ちます。例えば、ロボットアームを動かすときに、目的の位置までスムーズに到達させることができます。従来の方法では、がくがくとした動きになってしまうこともありましたが、この仕組みを使うことで、より人間らしい滑らかな動きを実現できるのです。まるで熟練した職人技のように、正確で無駄のない動きを機械に教えることができます。
その他にも、限られた資源をうまく配分する問題にも役立ちます。例えば、発電所の電力を調整したり、工場の生産ラインを管理したりする際に、この仕組みを使うことで、資源の無駄を減らし、効率的な運用が可能になります。限られた資源を最大限に活用し、より良い成果を生み出すことができるのです。
このように、勝負する仕組みを持つ網の目は、学びの場において重要な技術として、様々な分野で活躍が期待されています。今後、さらに多くの分野で応用され、私たちの生活をより豊かにしてくれることでしょう。
| 分野 | 効果 | 例 |
|---|---|---|
| ゲーム | 高得点獲得 | 状況に応じた適切な行動選択 (敵への攻撃、アイテム取得など) |
| 制御 | 滑らかで無駄のない動作 | ロボットアームの制御、人間らしい滑らかな動き |
| 資源管理 | 資源の無駄削減、効率的な運用 | 発電所の電力調整、工場の生産ライン管理 |
今後の展望

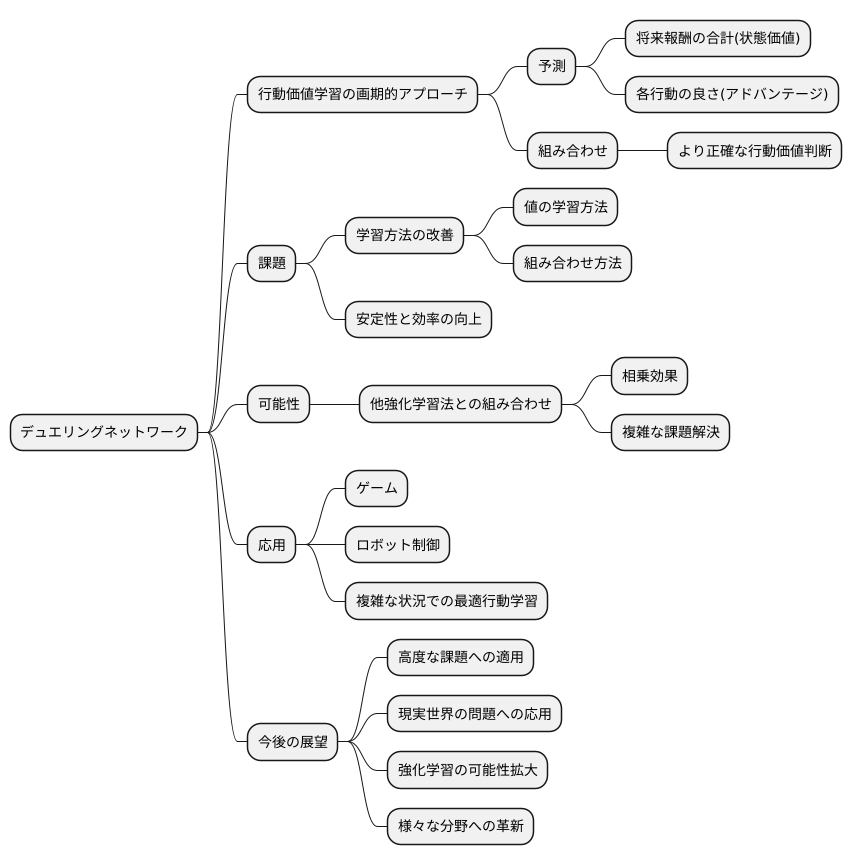
強化学習という分野において、行動の価値を学ぶための画期的な方法として、デュエリングネットワークが注目を集めています。この方法は、将来得られるであろう報酬の合計を予測するだけでなく、それぞれの行動がどれだけ良いかを個別に評価するという、二つの側面から学習を進めます。全体的な価値を状態価値と呼び、個々の行動の価値を、平均からの差分で表したものをアドバンテージと呼びます。この二つの要素を組み合わせることで、より正確に行動の価値を判断できるようになります。
しかし、デュエリングネットワークは発展途上の技術であり、状態価値とアドバンテージの学習方法には、まだ改善の余地があります。例えば、これらの値をどのように学習させるか、どのように組み合わせるかによって、学習の安定性や効率が大きく変化します。より効果的な学習方法を見つけることが、今後の重要な課題です。
さらに、デュエリングネットワークは単独で用いられるだけでなく、他の強化学習の方法と組み合わせることで、より強力な学習を実現できる可能性を秘めています。様々な学習方法と組み合わせ、相乗効果を生み出すことで、複雑な課題を解決できるようになると期待されています。
デュエリングネットワークは、ゲームやロボット制御といった分野で応用が期待されています。複雑な状況で最適な行動を学習する能力は、様々な分野での課題解決に役立つと考えられます。今後、より高度な課題への適用や、現実世界の問題への応用など、研究の進展が期待されます。デュエリングネットワークの進化は、強化学習の可能性を大きく広げ、様々な分野に革新をもたらす可能性を秘めています。